Mixtral 8x7B - Compact Version of GPT-4, Built by Mistral AI
Mistral AI's latest creation, Mixtral 8x7B, emerges as a compact yet powerful alternative to GPT-4. Read this article to learn how to download Mistral 8x7B torrents and how to run Mistral 8x7B locally with ollama
A notable event in the AI landscape just happened. Mistral AI's Mixtral 8x7B stands out as a significant advancement. This open-source large language model (LLM) is more than just a new addition; it's akin to a local, mini GPT-4.
Mixtral 8x7B: A Compact Version of GPT-4
Mixtral 8x7B stands as a compact, efficient version of GPT-4, offering advanced AI capabilities in a more manageable and accessible form. By adopting a similar Mixture of Experts (MoE) architecture, but in a scaled-down format, Mistral AI makes it a practical alternative for diverse applications.
Key Aspects of Mixtral 8x7B:
Structure: Utilizes 8 experts, each with 7 billion parameters, compared to GPT-4's larger scale.
Efficient Processing: Employs only 2 experts per token for inference, mirroring GPT-4's efficiency.
Technical Parameters:
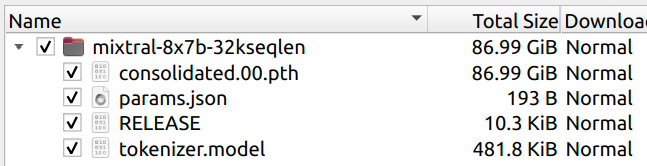
Size: The model is 87GB, smaller than an 8x Mistral 7B, indicating shared attention parameters for size reduction.
Comparison with GPT-4: Features a 2x reduction in the number of experts and a 24x reduction in parameters per expert, leading to an estimated total of 42 billion parameters.
Context Capacity:
Maintains a 32K context size, similar to GPT-4, ensuring robust performance.
Mixtral 8x7B
Why Everybody Is Talking About Mistral AI's New LLM Drop?
Developed by Mistral AI: This Paris-based startup has garnered attention for combining technical expertise with open-source accessibility.
Impact on the AI Industry: The release of Mixtral 8x7B signals a paradigm shift, challenging industry norms and promoting democratization in AI technology.
Beyond Adding to AI Achievements: Mixtral 8x7B goes beyond enhancing the list of AI innovations. It challenges existing standards and opens new avenues for innovation and exploration.
Paving the Way for Open, Accessible AI: Mistral AI’s approach with Mixtral 8x7B sets new precedents for openness and collaboration in AI development.
Download Mixtral 8x7B Torrents
Instead of the usual elaborate launches, Mistral AI chose a unique path for Mixtral 8x7B, releasing it via torrent links.
Here're the torrent links to Download the latest Mixtral 87XB model:
This approach starkly contrasts with the more orchestrated releases from companies like Google and OpenAI, focusing more on making a statement than creating spectacle.
The unconventional release has not only highlighted the model's capabilities but also sparked conversations about the future of AI technology and the role of open-source models.
Here's the specs you need to run Mixtral-8x7B locally (if you wish):
Running Mixtral 8x7b Locally
VRAM Requirements:
Minimum VRAM: 86GB
Equivalent to a 43B model's VRAM needs.
Parameter sharing among the 8x7B experts reduces VRAM usage.
A quantized 4-bit version can fit within 24GB of VRAM.
Compute Power:
Compute requirements are on par with a 14B model.
Every token generation involves running a 7B "manager" expert and the 7B "selected" expert.
Efficiency Considerations:
Mixture of Experts (MoE) models aim to optimize compute power rather than VRAM.
Parameter sharing among experts does provide some level of VRAM savings.
Try Out Mixtral 8x7B Online with Anakin AI
Anakin AI is one of the most popular No Code AI App builder online, where you can explore the beauty of this wonderkid LLM online, right now using Anakin AI's API:
Diving into the heart of Mixtral 8x7B, one finds a marvel of modern AI engineering, a testament to Mistral AI's expertise and vision. This model is more than just a smaller sibling of the widely acclaimed GPT-4; it's a refined, efficient, and accessible tool that stands on its own merits.
Mixtral 8x7B operates on the principle of a Mixture of Experts (MoE) model, a concept that has gained traction in recent years for its efficiency and scalability. Specifically, Mixtral 8x7B is comprised of 8 experts, each with 7 billion parameters, which is a significant scale-down from GPT-4’s speculated 8 experts with 111 billion parameters each. This design choice makes Mixtral not only more manageable in terms of computational requirements but also uniquely positioned for a variety of applications.
The architecture of Mixtral 8x7B is particularly fascinating. It is designed for token inference using only 2 of the 8 experts, a strategy that optimizes processing efficiency and speed. This approach is reflected in the model metadata, which provides deeper insights into its configuration:
This configuration showcases an advanced setup, featuring a high-dimensional embedding space (dim: 4096), multiple layers (n_layers: 32), and a substantial number of heads for attention mechanisms (n_heads: 32). The MoE architecture ("moe": {"num_experts_per_tok": 2, "num_experts": 8}) underscores the model’s focus on efficient, specialized processing for each token.
One of the most remarkable aspects of Mixtral 8x7B is its ability to deliver high-level AI capabilities while being considerably more accessible than its larger counterparts. This accessibility is not just in terms of usability but also in terms of the computational resources required to run it. The model's reduced size, compared to a hypothetical 8x scale-up of Mistral 7B, is achieved through shared attention parameters, a clever design choice that significantly reduces the overall model size without compromising its performance.
The implementation of Mixtral 8x7B in practical applications is also noteworthy. The model's design allows for flexible adaptation to various computing environments, from high-end servers to more modest setups. Here's a glimpse into how Mixtral 8x7B can be implemented:
In this simple command, example_text_completion.py represents a script utilizing the Mixtral 8x7B model, with the paths directing to the model and tokenizer files. This level of straightforward implementation speaks to Mistral AI's commitment to making advanced AI technology more accessible and user-friendly.
You can visit the Mixtral 8x7B Hugging Face page by someone here:
Mixtral 8x7B stands as a powerful yet approachable tool in the AI landscape. Its technical sophistication, combined with its pragmatic design, makes it not only a formidable LLM but also a beacon of what the future of AI models could look like - powerful, efficient, and within reach of a broader range of users and applications.
How to Run Mixtral 8x7B - Two Current Methods
Method 1: Run Mixtral 8x7B with This Hack
Run Mixtral 8x7B with This Hack
For those eager to experiment with Mixtral 8x7B immediately, a somewhat unorthodox but functional method exists. This approach involves adapting the original Llama codebase to work with Mixtral 8x7B, although it's important to note that this implementation is still in its early stages and might not fully leverage the model's capabilities.
Key Points of the Hack:
Naive and Slow: The implementation is admittedly basic and not optimized for speed.
Hardware Requirements: To run this version, you will need either two 80GB GPUs or four 40GB GPUs.
Technical Details: The method involves removing model parallelism for simplicity and sharding experts across the available GPUs. It also includes a reverse-engineered MoE implementation based on this research paper. How to Implement: Download the Weights: The Mixtral model weights are available either via Torrent or from the Hugging Face repository at Mixtral 8x7B on Hugging Face. Running the Model: Once you have the weights, you can run the model on 2 GPUs (requiring about 45GB each) using the following command:
For a 4 GPU setup, add --num-gpus 4 to the command.
Method 2. Run Mixtral 8x7B with Fireworks AI
Run Mixtral 8x7B with Fireworks AI
An alternative, more user-friendly way to test Mixtral 8x7B is through the Fireworks.ai.
Fireworks AI offers a streamlined experience, though it's important to note that this is not an official implementation from Mistral AI.
Key Features of Fireworks.ai:
Quick Access: The model is available for use just hours after the initial release of the weights, demonstrating the agility and collaborative spirit of the AI community.
Reverse-Engineered Architecture: The implementation on Fireworks.ai was achieved by reverse-engineering the architecture from the parameter names in collaboration with the community. Using Fireworks.ai:
Accessing the Model: Simply visit Fireworks.ai to try out Mixtral 8x7B.
Caveat: Users should be aware that since this is not an official release, the results might vary, and updates are expected once Mistral AI releases the official model code.
Method 3. Run Mixtral 8x7B with Ollama
Run Mixtral 8x7B with Ollama
Prerequisites:
Ensure your system has a minimum of 48GB of RAM to accommodate the model's requirements.
Install Ollama version 0.1.16. This specific version is necessary for compatibility with the Mixtral-8x7B model. You can download it from the provided link.
Model Overview:
The Mixtral-8x7B is a state-of-the-art Sparse Mixture of Experts (MoE) Large Language Model (LLM) developed by Mistral AI.
It's known for its open weights and superior performance, outperforming the Llama 2 70B in various benchmarks.
With a permissive license, it's accessible for a wide range of applications, balancing cost and performance efficiently.
Execution Command:
To run the model, use the command ollama run mixtral:8x7b. This command initiates the model within the OLLAMA environment.
Usage Tips:
Ensure your environment is properly configured for OLLAMA. Check for any dependencies or environment variables that need to be set.
After executing the command, the model should start. Depending on your system's specifications, initialization time may vary.
Post-Execution:
Once the model is running, you can interact with it according to your project's requirements.
The model is equipped for a wide range of generative tasks, making it versatile for both research and practical applications.
Support and Updates:
Regular updates and support are available, as indicated by its recent update and usage statistics (over 871 pulls).
For troubleshooting and more detailed instructions, refer to the Mistral AI documentation or community forums.
The release of Mixtral 8x7B has rippled across the AI community, eliciting a range of reactions that underscore its significance. Enthusiasts, experts, and developers have all weighed in, highlighting the model's impact from multiple angles.
Positive Buzz and Constructive Criticism: The response has been largely positive, with many praising Mistral AI for their innovative approach and the model's technical capabilities.
This enthusiasm is tempered by constructive criticism, mainly focused on the model's limitations compared to larger counterparts like GPT-4, but even these critiques acknowledge the potential of Mixtral 8x7B.
Perhaps most importantly, the AI community has shown a strong appreciation for Mistral AI’s commitment to open-source principles. This approach has been hailed as a step towards democratizing AI technology, making it more accessible to a wider range of users and developers.
Mistral AI: Setting New Standards for Open Source LLMs with Mixtral 8x7B
As we look to the future, Mixtral 8x7B’s influence on the AI landscape becomes increasingly apparent. Mistral AI’s approach to releasing and designing Mixtral 8x7B could set new standards for AI model development and dissemination.
Mixtral 8x7B represents a significant push towards more open-source AI solutions. Its success could inspire more companies to adopt similar approaches, potentially leading to a more diverse and innovative AI research environment.
How Will Mistral AI's Mixtral 8x7B Changes the Future of AI and LLM Development
The enthusiastic reception of Mixtral 8x7B and the conversations it has sparked are indicative of a growing trend towards more open, collaborative AI development. This model has not only provided a valuable tool for various applications but has also opened up new avenues for innovation, exploration, and discussion in AI field.
As we look forward, Mixtral 8x7B is poised to play a crucial role in shaping the future of AI. Its impact will likely be felt across industries and communities, driving further advancements and democratizing access to cutting-edge AI technology. In summary, Mixtral 8x7B is not just a milestone for Mistral AI; it's a milestone for the AI community as a whole, signaling a shift towards more inclusive, collaborative, and open AI development.
Want to test out all these awesome LLMs online? Try Anakin AI!
Anakin AI is one of the most convenient way that you can test out some of the most popular AI Models without downloading them!