Zephyr-7B, Kann dieser 7B LLM wirklich ChatGPT schlagen?
Entdecken Sie Zephyr 7B Alpha und Beta: Durchbrüche in Conversational AI – Benchmarks, Training und Anwendungen. 🚀 Erfahren Sie, wie diese Modelle die Fähigkeiten von Chatbots neu definieren und welchen realen Einfluss sie haben. #AI #ConversationalAI
Die Landschaft der KI hat mit der Entwicklung von Large Language Models (LLMs) eine revolutionäre Veränderung erlebt. Diese hochentwickelten Algorithmen, die in der Lage sind, menschenähnlichen Text zu verstehen und zu generieren, haben verändert, wie wir mit Technologie interagieren. An vorderster Front dieser Entwicklung steht Zephyr-7B, ein Modell, das nicht nur durch seine Größe, sondern auch durch seine bemerkenswerte Effizienz und Leistung hervorsticht.
Entwickelt vom innovativen Team bei Hugging Face, ist Zephyr-7B ein Zeugnis für die rasante Entwicklung von KI. Als Nachfolger des Modells Mistral 7B verkörpert Zephyr-7B den Höhepunkt dessen, was kleinere, effizientere Modelle erreichen können. Es ist nicht nur ein weiteres Modell in der Masse der KI; es ist ein Symbol für Effizienz und Effektivität und setzt neue Maßstäbe im Bereich der LLMs.
Die Entstehung der Zephyr-7B-Modelle
Zephyr-7B Alpha: Der Pionier
Zephyr-7B Alpha markierte den ersten Vorstoß in die Welt der feinabgestimmten Sprachmodelle. Hier ist, was es auszeichnet:
Grundlagenmodell: Zephyr-7B Alpha ist eine feinabgestimmte Version des Modells Mistral 7B, das für seinen Status als eines der besten kleinen Open-Source-Modelle bekannt ist.
Trainingsmethode: Der Trainingsprozess für Zephyr-7B Alpha umfasste drei wesentliche Phasen:
Distilled Supervised Fine-Tuning (dSFT): Diese Phase begann mit der Erstellung eines umfangreichen, selbstinstruktiven Datensatzes namens UltraChat, gefolgt von distilliertem SFT.
AI-Feedback (AIF) Sammlung: Vier verschiedene große Sprachmodelle (LLMs) generierten Abschlüsse, die dann von GPT-4 bewertet wurden, um Feedback (UltraFeedback) zu sammeln.
Distilled Direct Preference Optimization (dDPO): Das dSFT-Modell wurde mithilfe der Feedback-Daten durch DPO verbessert.
Erkenntnisse über Überanpassung: Interessanterweise führte Überanpassung an den Präferenzdaten während der DPO zu besseren Chat-Ergebnissen und unterstreicht die Anpassungsfähigkeit des Modells.
Zephyr-7B Beta: Verfeinert und Verbessert
Zephyr-7B Beta baut auf den Grundlagen seines Vorgängers Alpha auf und bringt mehrere bemerkenswerte Verbesserungen mit sich:
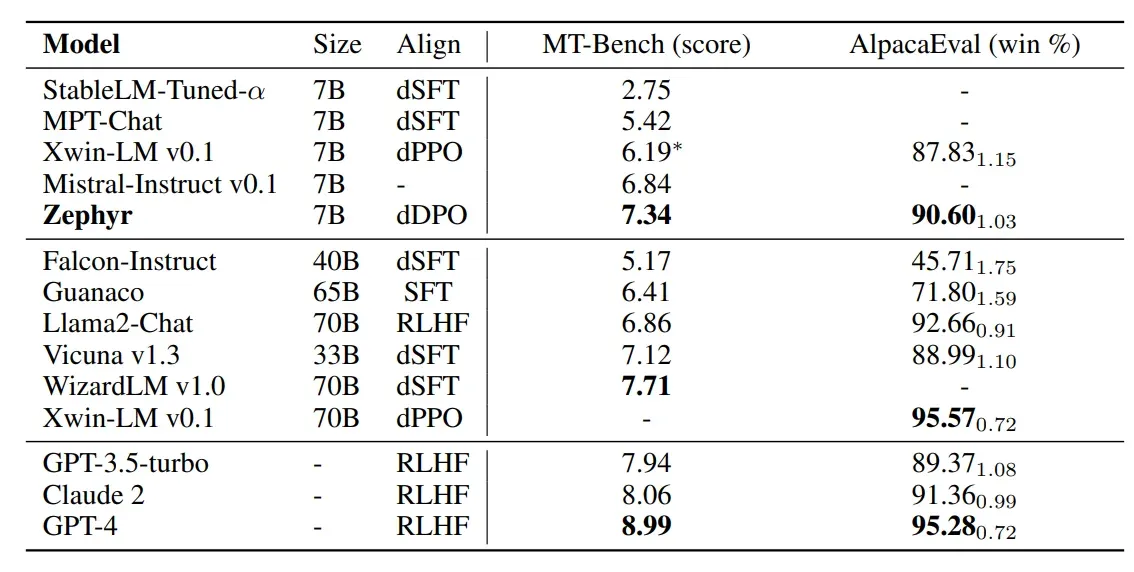
Benchmark-Leistung: Die Leistung von Zephyr-7B Beta in Benchmark-Tests ist ein herausragendes Merkmal. Es erzielte 7,34 bei MT-Bench und übertraf damit den Wert von Llama 2 Chat 70B von 6,86. Allerdings erreichte es auf AlpacaEval eine leicht niedrigere Siegesrate von 90,60% im Vergleich zu 92,66% bei Llama 2 Chat 70B.
Direct Preference Optimization (DPO): Zephyr-7B Beta verwendet weiterhin DPO, verfeinert und verbessert jedoch diesen Ansatz, was zu verbesserten Chat-Ergebnissen führt.
Schwerpunkt des Trainings: Das Training der Beta-Version legt starken Wert auf die Ausrichtung auf menschliche Präferenzen, ein entscheidender Faktor zur Verbesserung der Leistung des Modells.
Bevor Sie in die Welt von Zephyr-7B eintauchen, möchten Sie vielleicht einen Vorgeschmack darauf bekommen, was es kann. Das Team hat eine interaktive Demo zur Verfügung gestellt, in der Sie mit dem Modell interagieren und seine beeindruckenden Gesprächsfähigkeiten erleben können. Probieren Sie es aus, Anakin AI!
Wie schon bei der Alpha-Version zeichnet sich Zephyr-7B Beta nicht nur durch Metriken aus, sondern auch durch seinen einzigartigen Trainingsprozess und die gewonnenen Erkenntnisse auf dem Weg.
Gezieltes Feinabstimmen: Zephyr-7B Beta setzt die Tradition fort, auf einer starken Grundlage feinabzustimmen. Es startet mit dem Modell Mistral 7B und stellt sicher, dass die Kernfähigkeiten robust und zuverlässig sind. Auf dieser Grundlage kann Zephyr seine Gesprächsfähigkeiten verbessern.
Daten für das Training: Der groß angelegte Präferenzdatensatz UltraFeedback bleibt ein Grundpfeiler des Trainings von Zephyr-7B Beta. Durch das Verstehen und Priorisieren von Benutzerpräferenzen sorgt Zephyr-7B Beta dafür, dass seine Antworten den Erwartungen der Benutzer entsprechen und eine zufriedenstellende Gesprächserfahrung bieten.
Übergang zur direkten Präferenzoptimierung (DPO): Zephyr-7B Beta bleibt seiner Verpflichtung zur direkten Präferenzoptimierung (DPO) treu, einer Methode, die den Feinabstimmungsprozess vereinfacht. Durch die direkte Verwendung von Feedback-Daten eliminiert DPO die Notwendigkeit eines Belohnungsmodells und macht den Trainingsprozess effizienter und effektiver.
Überanpassung für bessere Chat-Ergebnisse: Eine faszinierende Erkenntnis, die auch von Zephyr-7B Alpha übernommen wurde, ist das Konzept der Überanpassung. Entgegen der herkömmlichen Weisheit hat sich gezeigt, dass Überanpassung an den Präferenzdatensatz zu besseren Chat-Ergebnissen führt. Zephyr-7B Beta nutzt dieses Phänomen und zeigt damit seine Anpassungsfähigkeit und seine Fähigkeit, aus Benutzerinteraktionen zu lernen.
Verwendung von Supervised Fine-Tuning (SFT): Wie bereits in der Alpha-Phase gezeigt, bestätigt Zephyr-7B Beta, dass sowohl Supervised Fine-Tuning (SFT) als auch Direct Preference Optimization (DPO) für den Erfolg unerlässlich sind. Die Synergie zwischen diesen Techniken gewährleistet, dass das Modell nicht nur versteht, sondern auch in der Kunst des Gesprächs brilliert.
Zephyr-7B Beta stellt einen bedeutenden Fortschritt dar, der auf den Erfolgen seines Vorgängers Alpha aufbaut. Es ist nicht nur ein Modell; es ist ein Gesprächspartner, der weiterhin dazulernt und sich anpasst und nach Exzellenz in jeder Interaktion strebt.`
Benchmarks für Zephyr-7B Beta
Zephyr-7B Alpha und Beta haben beachtliche Fortschritte in der Benchmark-Leistung gemacht. Insbesondere die Beta-Version zeichnet sich durch ihre Fähigkeit aus, in komplexen Gesprächsszenarien herausragende Leistungen zu erbringen. Hier ist das Radar-Diagramm zum Vergleich der Modelle:
Um Zephyr-7B in den Kontext zu stellen, wollen wir seine Leistung mit anderen bemerkenswerten Modellen vergleichen:
GPT-4: Im Vergleich zu GPT-4 zeigt Zephyr-7B Beta beeindruckende Benchmark-Werte. Obwohl GPT-4 in einigen Metriken möglicherweise einen etwas höheren Wert hat, machen Zephyr Beta's Fokus auf Ausrichtung und Effizienz es zu einem überzeugenden Konkurrenten.
Llama 2 Chat 70B: Zephyr-7B Beta übertrifft Llama 2 Chat 70B in MT-Bench und unterstreicht seine Fähigkeiten bei der Bewältigung von mehrstufigen Gesprächen. Obwohl Llama 2 Chat in AlpacaEval einen kleinen Vorteil behält, ist die Gesamtleistung von Zephyr Beta lobenswert.
Die Trainingsphasen der Zephyr 7B-Modelle erklärt:
Distilliertes überwachtes Feintuning (dSFT): Zephyrs Streben nach Exzellenz beginnt mit einer Grundlage in Form der Trainingsstufe des distillierten überwachten Feintunings (dSFT). Während dieser Phase taucht das Modell in eine umfangreiche und vielfältige Sammlung von Dialogen ein, die als UltraChat-Datensatz bekannt ist. Es lernt in einem selbstinstruktiven Stil und nimmt die Feinheiten von Sprache und Konversation auf.
KI-Feedback (AIF) Sammlung: Die zweite Stufe führt das Konzept des kollaborativen Lernens ein. Vier unterschiedliche, große Sprachmodelle tragen durch die Generierung potenzieller Antworten bei. Diese Antworten werden dann von dem beeindruckenden GPT-4 evaluiert. Dieser Prozess führt zur Erstellung des UltraFeedback-Datensatzes, der eine wertvolle Ressource für weitere Verfeinerungen darstellt.
Distilliertes direktes Präferenz-Optimieren (dDPO): Die letzte Stufe, das distillierte direkte Präferenz-Optimieren (dDPO), stellt den Höhepunkt des Trainings von Zephyr dar. Hier erfährt das Modell die transformative Kraft des DPO, unter Verwendung der Fülle an Feedback-Daten, die in der vorherigen Stufe erworben wurden. Dieser Verfeinerungsprozess führt zu signifikanten Verbesserungen in der Qualität der Gespräche, in denen Zephyr engagiert sein kann.
Das Ergebnis der Trainingsansätze
Overfitting funktioniert! Eine der bemerkenswerten Entdeckungen auf Zephyrs Reise ist der unerwartete Vorteil des Overfittings auf dem Präferenzdatensatz. Gegensätzlich zu Erwartungen hat sich gezeigt, dass dieses Overfitting ein Katalysator für verbesserte Konversationsfähigkeiten auf verschiedenen Benchmarks ist. Zephyrs Fähigkeit, seine Antworten basierend auf Präferenzen anzupassen, hebt es von anderen ab.
SFT und DPO, kombiniert: Experimente und rigorose Tests haben die entscheidende Rolle von sowohl dem überwachten Feintuning (SFT) als auch der direkten Präferenz-Optimierung (DPO) betont. Es hat sich gezeigt, dass die Kombination dieser beiden Trainingsansätze die Geheimzutat ist, die Zephyr in Chat-Szenarien glänzen lässt. DPO allein ist möglicherweise nicht ausreichend; es ist die Synergie von SFT und DPO, die Zephyrs Leistung verbessert.
Zephyr Beta vs Alpha, welche Verbesserungen gibt es?
Zephyr Alpha war beeindruckend, hatte aber auch seine Macken.
Benutzer berichteten Probleme mit der Schreibweise, bei denen die Antworten gelegentlich falsche Großbuchstaben enthielten.
Einige Antworten hatten eigenartige Einleitungen, die den Gesprächsfluss beeinflussten.
Zephyr Beta nimmt diese Erkenntnisse zu Herzen und wurde zusätzlich gefiltert, um diese Bedenken anzugehen. Als Ergebnis können Benutzer natürlichere und nahtlosere Interaktionen mit Zephyr Beta erwarten, was einen Schritt nach vorne in seiner Entwicklung darstellt.
Wie man Zephyr 7B mit Hugging Face-Transformers ausführt
Sie können Zephyr 7B ganz einfach mit der Hugging Face-Transformers-Bibliothek ausführen. Hier ist eine Anleitung, wie Sie das Modell mit Beispielen programmieren können:
# Importieren Sie erforderliche Bibliotheken
import torch
from transformers import pipeline
# Erstellen Sie eine Pipeline für die Textgenerierung mit Zephyr 7B Beta
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-beta", torch_dtype=torch.bfloat16, device_map="auto")
# Definieren Sie die Chat-Nachrichten
messages = [
{
"role": "system",
"content": "Du bist ein freundlicher Chatbot, der immer im Stil eines Piraten antwortet",
},
{"role": "user", "content": "Wie viele Helikopter kann ein Mensch auf einmal essen?"},
]
# Wenden Sie die Chat-Vorlage an und generieren Sie eine Antwort
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
# Geben Sie die generierte Antwort aus
print(outputs[0]["generated_text"])
Dieser Code richtet einen Chat mit Zephyr 7B Beta ein, in dem Sie die Rolle der Chat-Teilnehmer definieren und Ihre Fragen oder Nachrichten eingeben können. Das Modell generiert Antworten entsprechend den definierten Rollen und Inhalten. Passen Sie die Nachrichten und Parameter nach Bedarf an Ihren spezifischen Anwendungsfall an.
Einschränkungen von Zephyr 7B
Zephyr 7B Beta ist zwar ein leistungsstarkes Sprachmodell, hat jedoch bestimmte Einschränkungen und Aspekte zu beachten:
Sicherheitsbedenken: Zephyr-7B-β wurde noch nicht auf die Einhaltung menschlicher Präferenzen hinsichtlich Sicherheit im RLHF-Verfahren überprüft. Das bedeutet, dass das Modell problematische Ausgaben produzieren kann, insbesondere wenn es dazu aufgefordert wird.
Filterung von Antworten: Im Gegensatz zu Modellen wie ChatGPT wird Zephyr-7B-β nicht mit einer In-the-Loop-Filterung von Antworten bereitgestellt. Benutzer sollten Vorsicht walten lassen, um bei der Verwendung des Modells angemessene und sichere Interaktionen zu gewährleisten.
Trainingsdaten: Die genaue Größe und Zusammensetzung des Korpus, der für das Training des Basismodells (Mistral-7B-v0.1) verwendet wurde, sind unbekannt. Es ist wahrscheinlich, dass die Trainingsdaten eine Mischung aus Webdaten und technischen Quellen wie Büchern und Code enthalten haben. Dies kann sich auf das Wissen und die Antworten des Modells auswirken.
Es ist wichtig, sich dieser Einschränkungen bewusst zu sein, wenn Sie Zephyr 7B Beta verwenden, und den Kontext zu berücksichtigen, in dem es angewendet wird.
Fazit
Zusammenfassend sind Zephyr 7B Alpha und Zephyr 7B Beta bahnbrechende Sprachmodelle, die dank innovativer Schulungstechniken wie DPO Benchmarks übertroffen haben. Diese Modelle stellen einen bedeutenden Fortschritt in der Konversations-KI dar und bieten spannende Möglichkeiten für Aufgaben der natürlichen Sprachverarbeitung. Obwohl sie in verschiedenen Szenarien glänzen, sollten Benutzer potenzielle Einschränkungen und eine verantwortungsvolle Nutzung beachten, um sichere und ethische Interaktionen zu gewährleisten.
Sie können die Leistung der Zephyr 7B-Modelle ganz einfach auf Anakin AI testen: