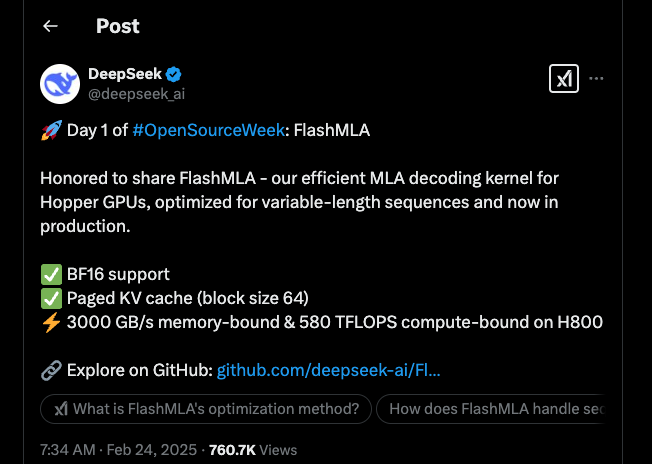
DeepSeek Memperkenalkan FlashMLA: Hari 1 OpenSourceWeek!
DeepSeek telah memulai Minggu Sumber Terbuka mereka dengan gempar, mengungkapkan FlashMLA — sebuah kernel dekode MLA canggih yang dibangun untuk GPU Hopper NVIDIA. Pengumuman ini telah membuat komunitas teknologi heboh, dan orang-orang sangat antusias untuk mengetahui apa arti pembaruan ini untuk pemrosesan AI.
Ingin memanfaatkan kekuatan AI untuk pembuatan dan pengeditan
DeepSeek telah memulai Minggu Sumber Terbuka mereka dengan gempar, mengungkapkan FlashMLA — sebuah kernel dekode MLA canggih yang dibangun untuk GPU Hopper NVIDIA. Pengumuman ini telah membuat komunitas teknologi heboh, dan orang-orang sangat antusias untuk mengetahui apa arti pembaruan ini untuk pemrosesan AI.
Ingin memanfaatkan kekuatan AI untuk pembuatan dan pengeditan video yang mulus? Anakin AI adalah platform yang tepat untuk Anda! Dengan rangkaian lengkap generator video AI canggih — termasuk Runway M, Minimax Video 01, Tencent Hunyuan Video, dan banyak lagi — Anda dapat dengan mudah mewujudkan visi kreatif Anda. Baik Anda sedang mentransformasi adegan, menghasilkan urutan sinematik, atau menyempurnakan editan dengan model AI lanjutan, Anakin AI memiliki semua yang Anda butuhkan.
FlashMLA adalah kernel khusus yang dirancang untuk mempercepat proses dekode untuk Multi-head Latent Attention (MLA). Dalam istilah sederhana, ini membantu model AI menangani urutan dengan panjang variabel dengan lebih efisien. Apakah Anda berfokus pada pemrosesan bahasa alami atau tugas AI lainnya, alat ini siap membuat gebrakan besar.
Fitur Utama dan Kinerja
Dukungan BF16
Salah satu fitur menonjol dari FlashMLA adalah dukungannya untuk presisi BF16 (Brain Float 16). Dengan menggunakan BF16, kernel mengurangi penggunaan memori tanpa mengorbankan akurasi yang dibutuhkan oleh model AI berskala besar. Pengguna telah memuji alat ini, mencatat bahwa ini adalah pengubah permainan nyata dalam menangani komputasi berat.
Paged KV Cache
Aspek menarik lainnya adalah cache key-value terpage, yang datang dengan ukuran blok 64. Pengaturan ini secara efisien mengelola memori dan membantu meningkatkan kinerja inferensi. Ini seperti memiliki kotak alat yang terorganisir dengan baik di mana setiap alat berada tepat di tempat yang Anda butuhkan.
Metrik Mengagumkan
Dari segi kinerja, FlashMLA tidak mengecewakan. Di GPU H800 SXM5, alat ini mencatat 3000 GB/s dalam skenario terbatas memori dan mencapai hingga 580 TFLOPS ketika tugasnya terbatas pada komputasi. Angka-angka ini bukan hanya mengesankan — mereka adalah bukti dari rekayasa luar biasa di balik kernel ini.
Bagaimana FlashMLA Berbeda
FlashMLA mengambil inspirasi dari proyek-proyek terkenal seperti FlashAttention dan CUTLASS dari NVIDIA. Ini dibangun dengan fokus pada efisiensi dan kesiapan produksi, memastikan bahwa pengembang dapat mengintegrasikannya dengan lancar ke dalam alur kerja mereka. Orang-orang dalam komunitas cepat berkomentar bahwa ini adalah alat yang harus dimiliki bagi siapa saja yang serius tentang mendorong batas kinerja AI.
Integrasi dan Pengaturan
Bagi mereka yang ingin memulai, instalasinya semudah membuat pie. Dengan GPU Hopper, CUDA 12.3 atau lebih tinggi, dan PyTorch 2.0 atau di atasnya, Anda dapat menginstal FlashMLA menggunakan perintah sederhana:python setup.py install
Setelah terinstal, Anda dapat menjalankan benchmark dengan:python tests/test_flash_mla.py
Proses sederhana ini sangat diterima di kalangan pengembang, banyak dari mereka yang sudah berbagi testimonial mengagumkan tentang bagaimana FlashMLA telah mengubah proyek mereka.
Gambaran yang Lebih Besar
Rilis FlashMLA oleh DeepSeek menandai awal dari minggu inovasi sumber terbuka yang menarik. Perusahaan ini tidak hanya berhenti di sini — mereka mengundang pengembang dari seluruh dunia untuk berkolaborasi dan membangun teknologi baru ini. Seiring AI terus berkembang, alat seperti FlashMLA memainkan peran penting dalam membuat AI canggih lebih mudah diakses dan efisien.
Pengembang dan penggemar teknologi sama-sama memperhatikan proyek ini. Dengan FlashMLA, DeepSeek telah menunjukkan komitmen yang jelas untuk mendorong batasan, dan pengumuman ini hanyalah puncak gunung es selama Minggu Sumber Terbuka.
Pemikiran Akhir
Pengenalan FlashMLA oleh DeepSeek membuat semua orang berbicara. Dengan dukungan yang kuat untuk BF16, cache KV terpage yang inovatif, dan metrik kinerja yang luar biasa, jelas bahwa alat ini ditujukan untuk mendefinisikan kembali efisiensi dalam pemrosesan AI. Jika Anda terlibat dalam game AI, sekarang adalah saatnya untuk menjelajahi apa yang dapat dilakukan FlashMLA untuk Anda. Pantau terus untuk pembaruan lebih lanjut saat DeepSeek terus meluncurkan fitur baru yang menarik sepanjang Minggu Sumber Terbuka.