DeepEP Mengubah Komunikasi untuk Model MoE: Hari Kedua OpenSourceweek DeepSeek
lansekap AI yang cepat berubah, DeepSeek telah memperkenalkan solusi inovatif untuk salah satu bottleneck paling signifikan dalam pelatihan dan inferensi model AI berskala besar. DeepEP, perpustakaan komunikasi Expert Parallelism (EP) sumber terbuka pertama, menjanjikan untuk merevolusi cara model Mixture-of-Experts (MoE) diterapkan dan diskalakan.
generasi berbasis gambar, video, atau teksFlux 1.
lansekap AI yang cepat berubah, DeepSeek telah memperkenalkan solusi inovatif untuk salah satu bottleneck paling signifikan dalam pelatihan dan inferensi model AI berskala besar. DeepEP, perpustakaan komunikasi Expert Parallelism (EP) sumber terbuka pertama, menjanjikan untuk merevolusi cara model Mixture-of-Experts (MoE) diterapkan dan diskalakan.
generasi berbasis gambar, video, atau teksFlux 1.1 Pro Ultra, Stable Diffusion XL, dan Minimax Video 01
Integrasikan model-model AI seperti GPT-4o, Claude 3, dan Gemini untuk inferensi generasi berikutnya. Optimalkan sumber daya komputasi dengan pipeline AI otomatis dan penerapan agen cerdas. Manfaatkan model generasi gambar, video, dan teks yang canggih untuk mempercepat inovasi AI Anda.
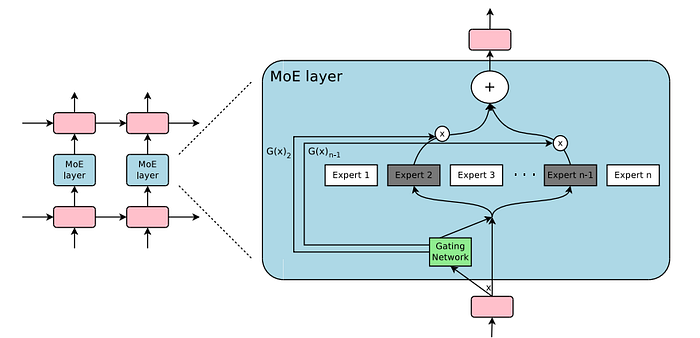
Model MoE dengan cepat menjadi favorit dalam penelitian AI. Alih-alih membebani satu jaringan, arsitektur ini hanya mengaktifkan jaringan saraf "ahli" yang diperlukan untuk tugas tertentu, menjadikannya sangat efisien. Bayangkan memiliki tim spesialis, masing-masing menangani bagian pekerjaannya, daripada satu orang yang bisa melakukan semuanya. Itulah keajaiban di balik MoE — memungkinkan model besar untuk diskalakan hingga triliunan parameter tanpa membengkakkan biaya komputasi.
Tantangan Komunikasi
Namun, setiap mawar memiliki durinya. Seiring pertumbuhan model MoE, begitu juga kebutuhan untuk dengan efisien mengarahkan token ke ahli yang tepat, apakah mereka berada di GPU yang sama atau tersebar di berbagai node. Perpustakaan komunikasi tradisional tidak dibangun untuk jenis pertukaran data ini. Hasilnya? Pelambatan pelatihan, peningkatan latensi inferensi, dan perangkat keras yang tidak terpakai secara optimal. Ketika Anda berlomba melawan waktu dan biaya, setiap mikrodetik sangat berarti.
DeepSeek DeepEP Terungkap: Apa Itu, Apa yang Dilakukannya, dan Bagaimana Cara Kerjanya
Anda mungkin bertanya, “Apa sebenarnya DeepSeek DeepEP?” Nah, mari kita urai dalam bahasa yang sederhana. DeepEP adalah perpustakaan komunikasi sumber terbuka yang dirancang oleh DeepSeek. Ini dirancang khusus untuk meringankan beban berat dalam model MoE — model-model tersebut yang membagi tugas di antara banyak ahli yang berspesialisasi. Pada dasarnya, DeepEP memastikan bahwa setiap bit data menemukan jalannya ke ahli yang tepat dengan cepat dan lancar.
Apa yang Dilakukan DeepEP?
Sederhananya, DeepEP menyederhanakan pengacakan data antara para ahli. Ini menangani pengiriman token input ke para ahli yang sesuai dan kemudian dengan efisien mengumpulkan hasilnya. Dengan melakukan ini, ia mengurangi lag dan bottleneck yang biasanya memperlambat pelatihan dan inferensi dalam sistem AI berskala besar.
Bagaimana Cara Kerjanya?
DeepEP memanfaatkan teknologi komunikasi berkecepatan tinggi:
Di Dalam Mesin: Ini menggunakan NVLink dari NVIDIA untuk memindahkan data dengan kecepatan luar biasa 153 GB/s. Bayangkan seperti sabuk konveyor berkecepatan tinggi di dalam dapur yang sibuk, di mana setiap bahan mencapai tujuannya tanpa penundaan.
Antar Mesin: Untuk komunikasi antara mesin yang berbeda, DeepEP mengandalkan RDMA di atas InfiniBand, mencapai kecepatan hingga 47 GB/s. Bayangkan layanan pengiriman yang terkoordinasi dengan baik yang memastikan pesanan dikirim dan diterima dalam waktu yang sangat cepat.
Pengelolaan Presisi: Dengan dukungan FP8 asli, DeepEP mengurangi penggunaan memori secara signifikan sambil menjaga akurasi model tetap utuh — seperti mengemas koper dengan lebih efisien tanpa meninggalkan barang-barang penting.
Contoh dalam Tindakan:
Bayangkan Anda sedang mengelola restoran pada saat makan malam yang ramai. Pesanan (token input) masuk dan perlu dikirim ke koki yang tepat (ahli) untuk hidangan spesial mereka. Sistem tradisional mungkin akan mencampuradukkan pesanan atau menunda pengiriman, yang mengakibatkan layanan lambat dan pelanggan yang frustrasi. Dengan DeepEP, setiap pesanan dengan cepat dikirim ke koki yang benar, dan hidangan yang selesai segera kembali dikirim ke pelayan (hasil gabungan), memastikan bahwa setiap tamu mendapatkan makanannya tepat waktu. Proses yang disederhanakan ini adalah apa yang dilakukan DeepEP untuk model MoE — memastikan setiap potongan data ditangani dengan cepat dan akurat.
Dampak Dunia Nyata
Manfaat DeepEP bukan hanya teori — mereka sudah membuat gelombang dalam aplikasi dunia nyata. Pengguna awal melaporkan:
55% pemrosesan token lebih cepat selama pelatihan, yang berarti lebih banyak data ditangani dalam waktu yang lebih sedikit.
Pengurangan 30% dalam waktu iterasi, menghemat beberapa detik (atau bahkan menit) selama pelatihan model.
Efisiensi daya yang meningkat — ini juga lebih ramah lingkungan, membantu mengurangi biaya energi sambil meningkatkan kinerja.
Peningkatan ini bukan hanya angka di halaman; mereka diterjemahkan menjadi penghematan nyata dalam biaya cloud, siklus eksperimen yang lebih cepat, dan peningkatan signifikan dalam skala. Apakah Anda sedang melatih model bahasa besar atau menggerakkan analitik video real-time, DeepEP membuktikan nilainya di seluruh bidang.
Melihat ke Depan
DeepEP tidak berpuas diri. Peta jalan terlihat cukup menjanjikan:
Interkoneksi optik menjanjikan throughput yang lebih tinggi — pikirkan 800 Gb/s.
Adaptasi presisi otomatis ada di cakrawala, beralih secara dinamis antara FP8, FP16, dan FP32 untuk mendapatkan kecepatan dan stabilitas terbaik.
Beberapa bahkan mengisyaratkan tentang rute terinspirasi kuantum, yang terdengar seperti fiksi ilmiah tetapi bisa jadi merupakan lompatan besar berikutnya dalam efisiensi pengiriman token.
Putusan
Jadi, apa kata terakhir tentang DeepEP? Ini adalah angin segar bagi siapa saja yang bekerja dengan model MoE. Dengan menangani salah satu bottleneck tersulit dalam pelatihan dan inferensi AI, DeepEP tidak hanya meningkatkan kecepatan dan efisiensi tetapi juga mendemokratisasi akses ke alat komunikasi berkinerja tinggi melalui sifatnya yang sumber terbuka. Para ahli di seluruh papan memuji kemampuannya untuk menyeimbangkan ketepatan teknis dengan manfaat praktis yang nyata.
Secara singkat, DeepEP membalikkan tantangan komunikasi tradisional dalam AI. Ini adalah alat yang tidak hanya mendorong batasan apa yang mungkin, tetapi juga membuat seluruh proses menjadi lebih lancar, lebih cepat, dan lebih hemat energi. Bagi mereka di komunitas AI, ini adalah terobosan yang patut diperhatikan.
Seperti pepatah mengatakan, ketika situasi menjadi sulit, yang kuat akan bergerak maju — dan dengan DeepEP, masa depan AI terdistribusi tampak lebih cerah dari sebelumnya.