特にAIの最新動向に追従している場合、GPT-Fastについて聞いたことがあるかもしれません。GPT-FastはAIモデルのターボチャージャーのようなもので、モデルをより高速かつ効率的にし、LLMに真剣なパフォーマンス向上をもたらします。
これはクラシックカーにパワフルなエンジンを搭載するようなものです。同じ素晴らしいモデルですが、今でははるかに速く動作するのです!次のGIFで、GPT-Fastの実際のパフォーマンス向上をご覧ください:
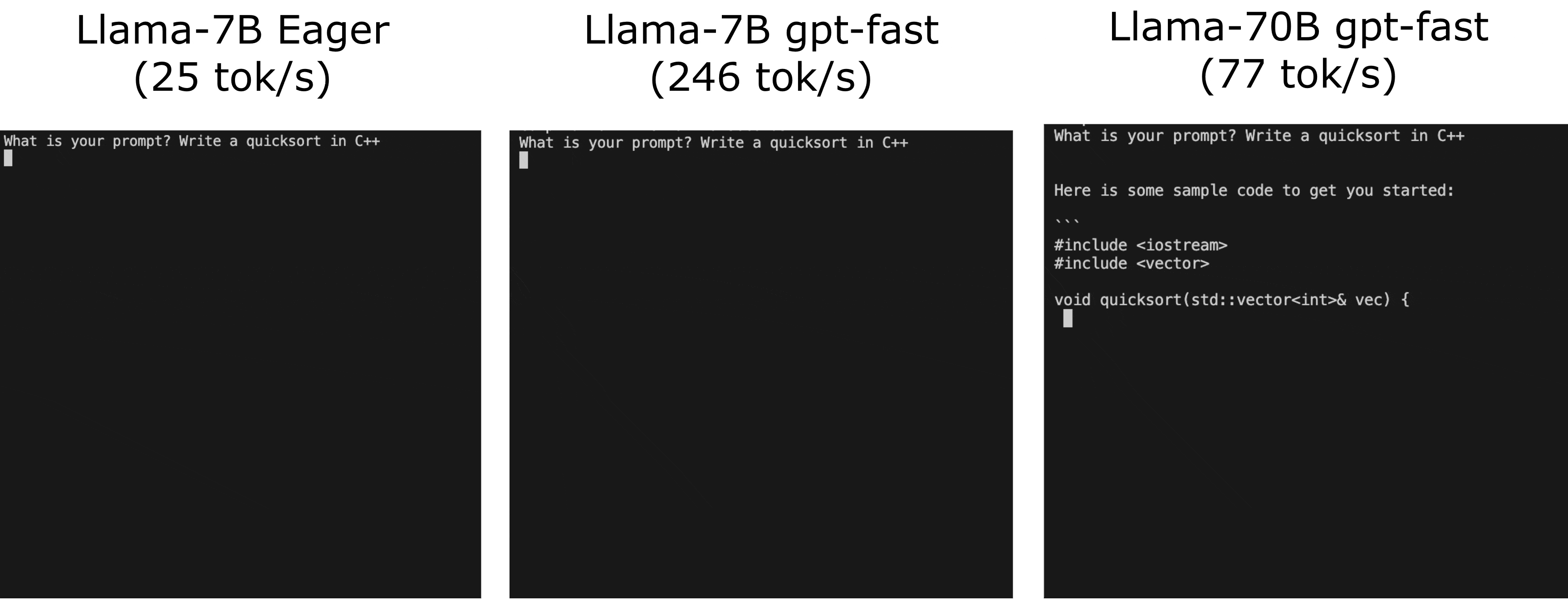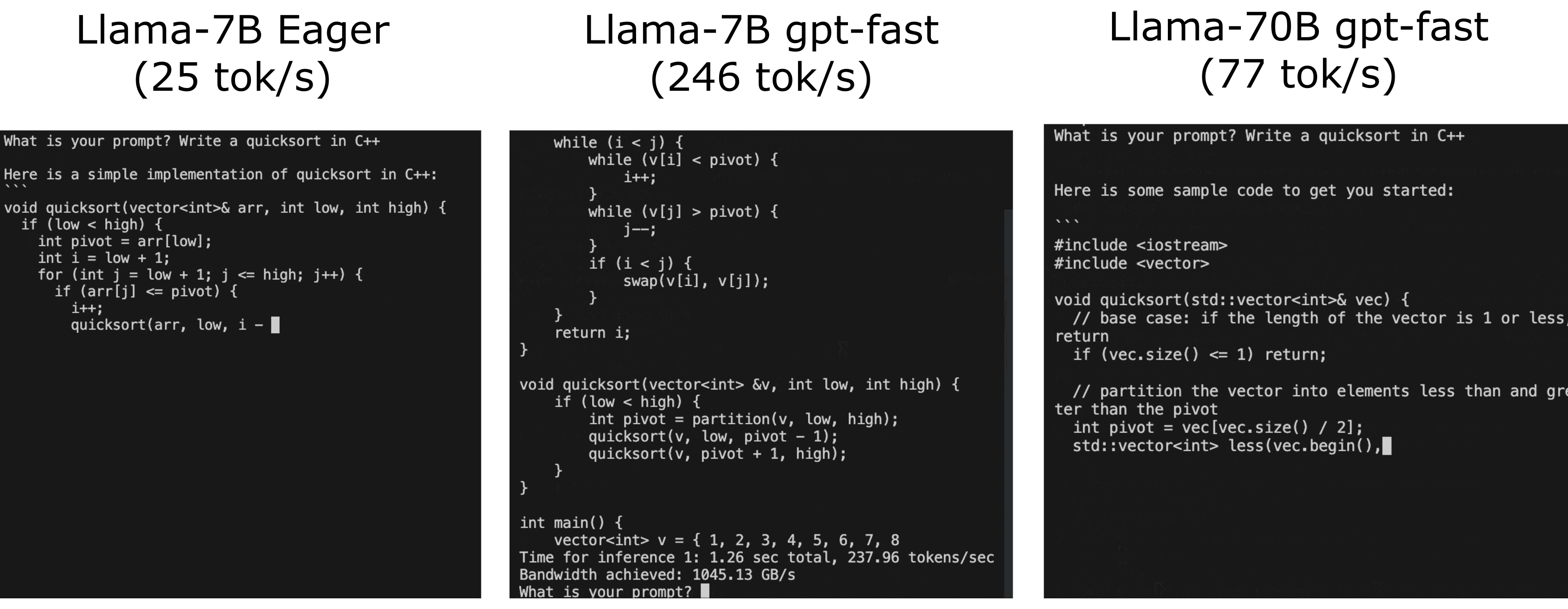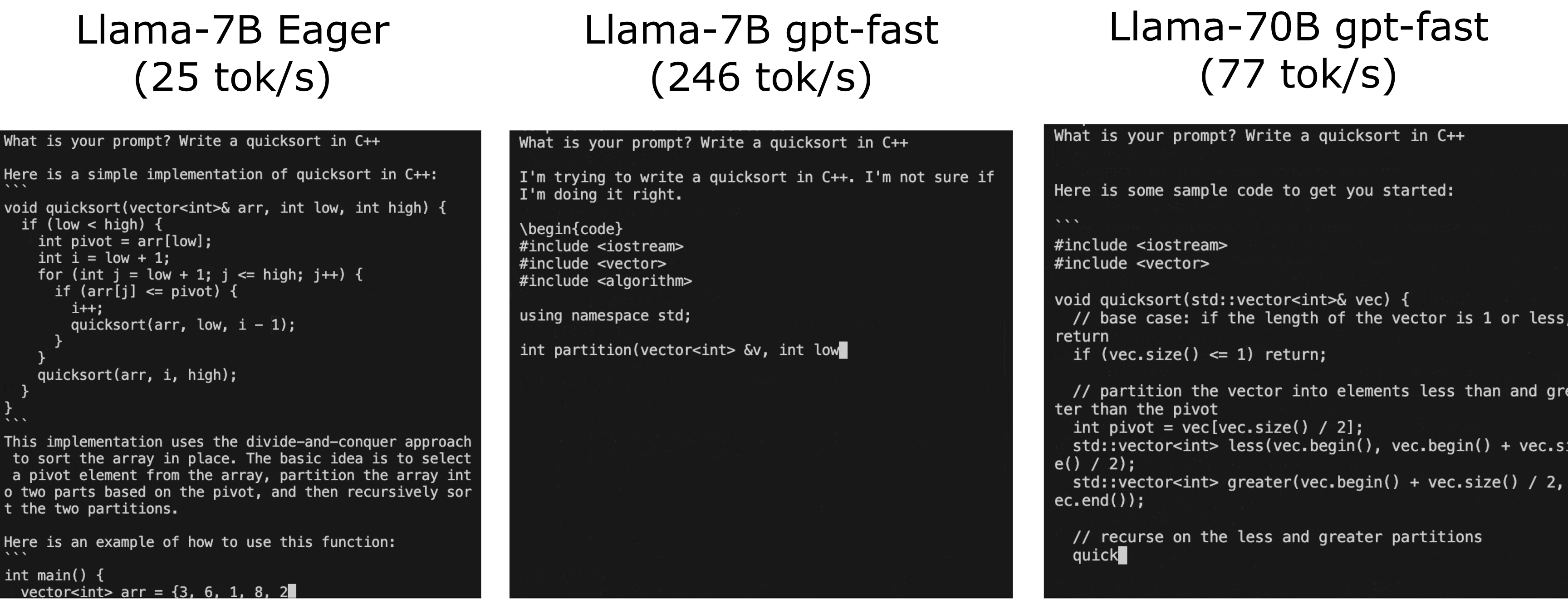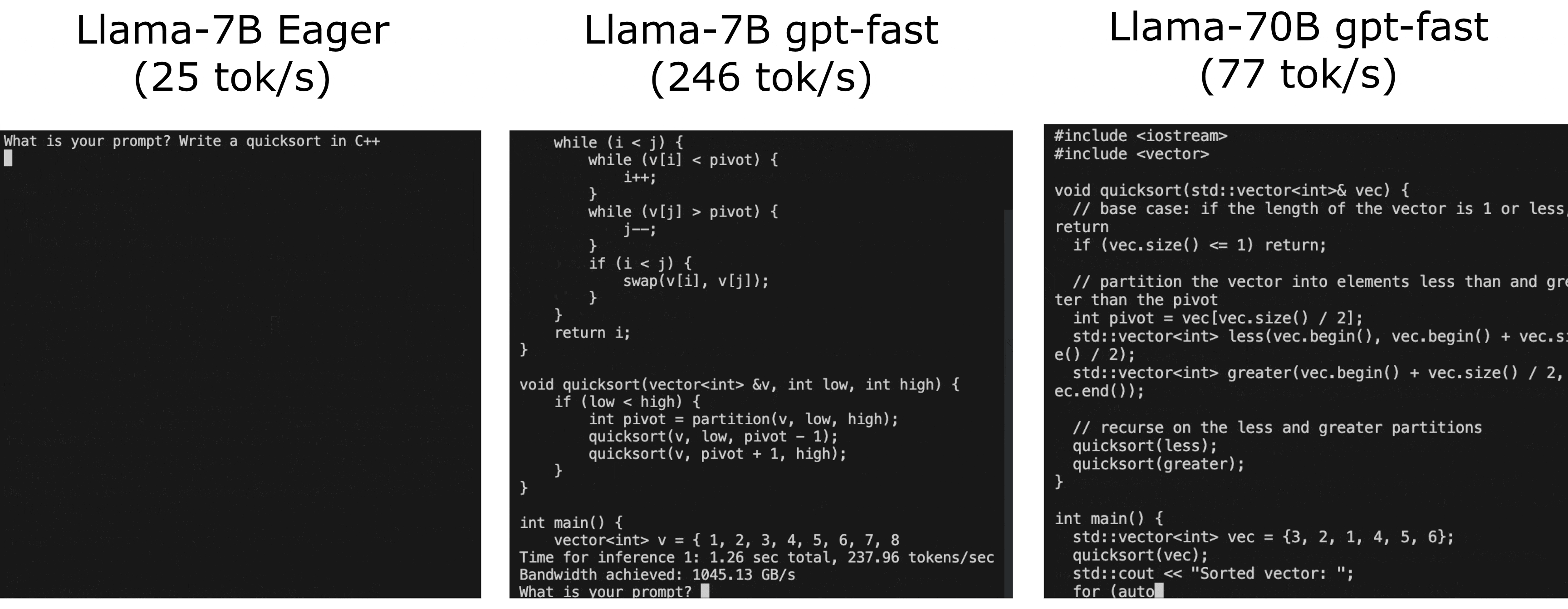
それでは、GPT-Fastはどのように機能するのでしょうか?GPT-Fastとは何でしょうか?
GPT-Fastとは何ですか?
GPT-Fastは、大規模な言語モデルのパフォーマンスを向上させるために特別に設計された最先端のツールです。これは、AIの革新的な進歩を物語るものであり、主に速度と効率に焦点を当てており、モデルの基本的な機能を損なうことなく、処理の高速化を図るために高度なコンピューティングの力を活用しています。
GPT-Fastの目標は2つあります:
- パフォーマンスの向上:GPT-FastはAIモデルの動作速度を向上させます。広範なデータセットと複雑な計算を迅速に処理するように設計されており、処理時間を短縮し、全体的な効率を向上させることができます。
- 効率の最適化:速度だけでなく、GPT-Fastは効率的なリソースの利用を重視します。高度な計算能力を必要とせずに素晴らしい結果を出すことができるため、パフォーマンスとリソース消費のバランスの取れたアプローチを実現します。
GPT-Fastのインストール方法
GPT-Fastを効果的に実行するためには、以下の手順に従ってください:
ステップ1. インストール:
PyTorch Nightlyをダウンロードしてインストールします。sentencepieceおよびhuggingface_hubをインストールします:
pip install sentencepiece huggingface_hub
LLama-2-7bなどの特定のモデルを使用する場合は、 Hugging Faceにアクセスしてログインし、huggingface-cli loginコマンドを実行します。
ステップ2. 重みのダウンロード:
サポートされているモデルには、openlm-research/open_llama_7b、meta-llama/Llama-2-7b-chat-hfなどがあります。
モデルを変換するには、次のコマンドを使用します:
export MODEL_REPO=meta-llama/Llama-2-7b-chat-hf
./scripts/prepare.sh $MODEL_REPO
ステップ3. テキストの生成:
以下のコマンドを使用します:
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --prompt "Hello, my name is"
パフォーマンスをさらに向上させるには、--compile_prefillを使用してプリフィルをコンパイルします(これにより、コンパイル時間が増加する場合があります)。
Anakin AIは、高度にカスタマイズされたワークフローで簡単にAIアプリを作成するのに役立ちます。GPT-4-Turbo、Claude-2-100k、Midjourney&Stable DiffusionのためのAPIなど、たくさんのAIモデルにアクセスすることができます!

興味がありますか?Anakin AIをチェックして、無料で試してみてください!👇👇👇
GPT-Fastはどれくらい速いですか?GPT-Fastのベンチマーク:
A100-80GB GPUで実行されるGPT-Fastのベンチマークは、次の表にまとめられています:
| モデル | テクニック | トークン/秒 | メモリ帯域幅(GB/s) |
|---|---|---|---|
| Llama-2-7B | 基本 | 104.9 | 1397.31 |
| 8ビット | 155.58 | 1069.20 | |
| 4ビット(G=32) | 196.80 | 862.69 | |
| Llama-2-70B | 基本 | OOM | - |
| 8ビット | 19.13 | 1322.58 | |
| 4ビット(G=32) | 25.25 | 1097.66 |
GPT-Fastの評価方法
次の手順で簡単にGPT-Fastを評価できます:評価ハーネスをこちらの指示に従ってインストールします。次に、次のコマンドを使用してモデルの正確性を評価します:
python eval.py --checkpoint_path checkpoints/$MODEL_REP O/model.pthの --compile --tasks hellaswag winogrande
注意: GPT-Fastでは生成タスクは現在サポートされていません。
GPT-Fastにおける量子化とは何ですか?
8ビットの量子化:
パラメータの精度を32ビットから8ビットに下げ、モデルのサイズを大幅に減らし、計算を高速化します。8ビットの量子化を適用するには、次のコマンドを使用します:
python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int8
次のコマンドでint8を使用して実行します:
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model_int8.pth
4ビットの量子化:
モデルのフットプリントをさらに減らし、精度の維持に焦点を当てます。4ビットの量子化を行うには、次のコマンドを使用します:
python quantize.py --checkpoint_path checkpoints/$MODEL_REPO/model.pth --mode int4 --groupsize 32
次のコマンドでint4を使用して実行します:
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model_int4.g32.pth
グループ化された量子化とGPTQ:
グループ化された量子化は精度を微調整するための細かい制御を可能にし、GPTQは量子化プロセスを微調整します。GPTQは次のコマンドを使用して適用されます:
python quantize.py --mode int4-gptq --calibration_tasks wikitext --calibration_seq_length 2048
これらの手順を実行し、量子化技術を理解することで、効率的かつパワフルなAIモデル最適化のためにGPT-Fastを効果的に実行および評価することができます。
なぜGPT-Fastは高速なのか?GPT-Fastの技術的詳細を見てみましょう

GPT-Fastの使用を始める際に、パフォーマンスの出発点と直面する可能性のある課題を認識することが重要です。最初の実装では、GPT-Fastの基本的な性能は約25.5トークン/秒(TOK/S)の程度です。これは悪くは聞こえませんが、実際にはツールの完全なポテンシャルではありません。ここでの主な障害は、CPUオーバーヘッドとして知られるものです。
GPT-FastのCPUオーバーヘッドとは何ですか?
- GPT-FastにおけるCPUオーバーヘッドは、CPU(中央処理装置)とGPU(グラフィックス処理装置)間の通信の遅延または遅れを指します。
- CPUはGPUに命令を送信する責任があります。理想的な場合、このプロセスは速くシームレスに行われるべきです。しかし、GPT-Fastの基本的な実装では、かなりの遅延があります。
- この遅延により、大量の計算を処理できるGPUが十分に活用されていない状態になります。これは、パワフルなスポーツカーを持っていても、1速しか走らせていない状態です。
なぜこれが重要なのですか?
- CPUオーバーヘッドは、GPT-Fastがデータを処理する速度と効率を制限する重要な要因です。
- この制約を理解することは、GPT-Fastの性能を最適化するための最初のステップです。CPU-GPUの通信に問題があることを知ることで、このボトルネックに直接対処する解決策に焦点を当てることができます。
torch.compileでGPT-Fastを高速化する方法
CPUオーバーヘッドによる初期のパフォーマンス制約を理解した後、GPT-Fastを効果的に活用するための次のステップは、torch.compileを利用して大幅なパフォーマンス向上を図ることです。
パフォーマンスを向上させるためのtorch.compileの活用
- CPUオーバーヘッドの削減: 特に「reduce-overhead」モードで
torch.compileを使用することで、CPUオーバーヘッドを大幅に削減することができます。この最適化により、より大きな操作領域を1つのコンパイルされたセグメントにキャプチャすることが可能となります。 - パフォーマンスの向上: この戦略的な実装により、最初の25.5 TOK/Sから印象的な107.0 TOK/Sまでパフォーマンスが大幅に向上します。
最適化の課題に対処する
- KVキャッシュの扱い方: 遭遇する主な課題は、トークン生成が増えるにつれてKVキャッシュの動的な性質です。GPT-Fastは、静的なKVキャッシュ割り当てを採用することで、キャッシュサイズを安定化させています。
- プリフィルフェーズの最適化: トランスフォーマーテキストの生成中には、プリフィルフェーズ(プロンプト全体が処理されるフェーズ)においてプロンプトの長さに変動があります。これにはさまざまなコンパイル戦略が必要ですが、GPT-Fastはこれをうまく処理し、効率的な処理を実現します。
Leve 激しいInt8量子化
- パフォーマンスのボトルネックをさらに軽減するために、特にメモリ帯域幅に関連するものは、GPT-Fastにはint8ウェイトのみの量子化が組み込まれています。
- 157.4 TOK/Sへのブースト: この量子化技術により、メモリに読み込む必要があるデータのサイズが削減され、処理速度が驚異的な157.4 TOK/Sに向上します。
GPT-Fastでの推測デコーディング
さらに、GPT-Fastは、トークン生成プロセスを大幅に加速する重要な技術である推測的デコーディングを実装しています。
繰り返しローディングの課題
- GPT-Fastの初期段階での注目すべき問題は、各トークン生成のための重みをロードする繰り返しで時間のかかるプロセスです。この繰り返しのローディングは、全体の操作を大幅に遅くしています。
推測的デコーディングの導入
- アウトカムの並列処理: 推測的デコーディングは、GPT-Fastが複数の潜在的なアウトカムを並列に処理できる革新的なソリューションです。1つずつ順番にトークンを生成する線形ではなく、複数の可能なトークンを一度に推測します。
- 生成の高速化: これにより、推測的デコーディングは生成プロセスを劇的に高速化します。各トークンの処理を待つ時間を実質的に減少させ、より迅速かつ効率的なテキスト生成が行われます。
GPT-Fastでの推測的デコーディングの動作方法
- GPT-Fastは、現在の状態に基づいていくつかの次のトークンを予測するために推測的デコーディングを使用します。
- これらの予測されたトークンは同時に処理され、最も可能性の高いアウトカムが選択されます。そのため、連続的な処理に費やされる時間を節約します。
そして最終的に、これがGPT-Fastの最適化されたパフォーマンスです:

GPT-Fastを試すには、GitHubページをご覧ください:

結論
結論として、GPT-Fastはただの突破口ではなく、AIのパフォーマンスの革命です。先進的な量子化技術、推測的デコーディング、テンソル並列処理により、GPT-Fastは驚くべきことを成し遂げました。
GPT-Fastは単なるツールではなく、AI愛好家や専門家が実験し、適応し、進化させるためのプレイグラウンドです。ですので、GPT-Fastに飛び込んで、その能力を探索し、そしてその進化に貢献してみてください。AIの未来はエキサイティングであり、GPT-Fastはその最前線で先導しています!
Anakin AIは、高度にカスタマイズ可能なワークフローで任意のAIアプリを簡単に作成できます。GPT-4-Turbo、Claude-2-100k、Midjourney&Stable DiffusionのAPIなど、多くのAIモデルにアクセスすることができます。

興味がありますか?Anakin AIをチェックし、無料で試してみてください!👇👇👇