DeepSeek Revela FlashMLA: Dia 1 da Semana de Open Source!
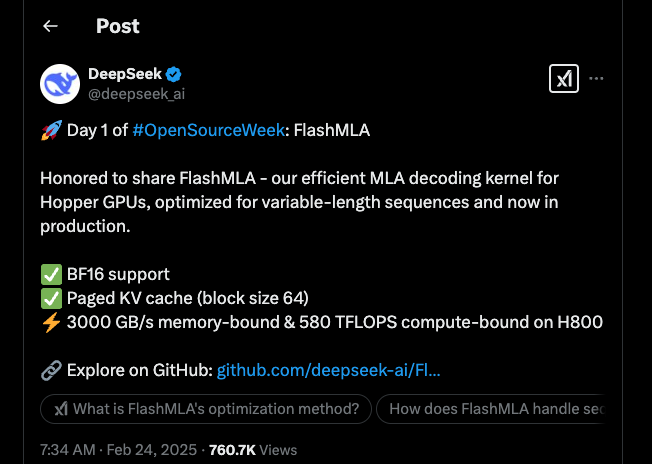
DeepSeek deu início à sua Semana de Código Aberto com tudo, revelando o FlashMLA — um kernel de decodificação MLA de ponta projetado para as GPUs Hopper da NVIDIA. Este anúncio deixou a comunidade tecnológica animada, e as pessoas estão ansiosas para descobrir o que essa atualização significa para o processamento
DeepSeek deu início à sua Semana de Código Aberto com tudo, revelando o FlashMLA — um kernel de decodificação MLA de ponta projetado para as GPUs Hopper da NVIDIA. Este anúncio deixou a comunidade tecnológica animada, e as pessoas estão ansiosas para descobrir o que essa atualização significa para o processamento de IA.
Quer aproveitar o poder da IA para a criação e edição de vídeos de forma tranquila? Anakin AI é a sua plataforma ideal! Com um conjunto abrangente de geradores de vídeos de IA de ponta — incluindo Runway M, Minimax Video 01, Tencent Hunyuan Video, e mais — você pode trazer sua visão criativa à vida sem esforço. Seja transformando cenas, gerando sequências cinematográficas ou refinando edições com modelos avançados de IA, Anakin AI tem tudo o que você precisa.
FlashMLA é um kernel especializado projetado para acelerar o processo de decodificação para Atenção Latente Multi-head (MLA). Em termos simples, ajuda modelos de IA a lidar com sequências de comprimento variável de forma mais eficiente. Se você está envolvido com processamento de linguagem natural ou outras tarefas de IA, essa ferramenta está pronta para causar um grande impacto.
Principais Recursos e Desempenho
Suporte a BF16
Uma das características mais notáveis do FlashMLA é seu suporte à precisão BF16 (Brain Float 16). Ao usar BF16, o kernel reduz o uso de memória sem sacrificar a precisão que os modelos de IA em larga escala exigem. Os usuários têm elogiado, apontando que é uma verdadeira revolução no tratamento de computações pesadas.
Cache KV Paginado
Outro aspecto interessante é o cache chave-valor paginado, que vem com um tamanho de bloco de 64. Essa configuração gerencia a memória de maneira eficiente e ajuda a aumentar o desempenho da inferência. É como ter uma caixa de ferramentas bem organizada, onde cada ferramenta está exatamente onde você precisa.
Métricas Impressionantes
No que diz respeito ao desempenho, o FlashMLA não decepciona. Na GPU H800 SXM5, ele atinge impressionantes 3000 GB/s em cenários limitados pela memória e chega a 580 TFLOPS quando a tarefa é limitada pelo cálculo. Esses números não são apenas impressionantes — eles são um testemunho da engenharia incrível por trás do kernel.
Como o FlashMLA se Destaca
FlashMLA se inspira em projetos renomados como FlashAttention e CUTLASS da NVIDIA. Ele foi construído com foco em eficiência e prontidão para produção, garantindo que os desenvolvedores possam integrá-lo facilmente em seus fluxos de trabalho. As pessoas na comunidade têm comentado rapidamente que esta é uma ferramenta essencial para qualquer um que leve a sério a superação dos limites do desempenho da IA.
Integração e Configuração
Para aqueles que estão ansiosos para começar, a instalação é tão fácil quanto torta. Com uma GPU Hopper, CUDA 12.3 ou superior, e PyTorch 2.0 ou acima, você pode instalar o FlashMLA usando um comando simples: python setup.py install
Uma vez instalado, você pode executar benchmarks com: python tests/test_flash_mla.py
Esse processo simples tem sido um sucesso entre os desenvolvedores, muitos dos quais já estão compartilhando testemunhos elogiosos sobre como o FlashMLA está remodelando seus projetos.
O Quadro Geral
A liberação do FlashMLA pela DeepSeek marca o início de uma semana empolgante de inovação em código aberto. A empresa não está parando por aqui — está convidando desenvolvedores de todo o mundo a colaborar e construir sobre essa nova tecnologia. À medida que a IA continua a evoluir, ferramentas como o FlashMLA desempenham um papel crucial em tornar a IA avançada mais acessível e eficiente.
Desenvolvedores e entusiastas de tecnologia estão de olho nesse projeto. Com o FlashMLA, a DeepSeek demonstrou um compromisso claro de ultrapassar os limites, e esse anúncio é apenas a ponta do iceberg durante a Semana de Código Aberto.
Considerações Finais
A introdução do FlashMLA pela DeepSeek está fazendo todos comentarem. Com seu robusto suporte ao BF16, um inovador cache KV paginado e métricas de desempenho excepcionais, está claro que esta ferramenta está prestes a redefinir a eficiência no processamento de IA. Se você está no jogo da IA, agora é a hora de explorar o que o FlashMLA pode fazer por você. Fique atento para mais atualizações enquanto a DeepSeek continua a lançar novos recursos empolgantes ao longo da Semana de Código Aberto.