Mô Hình R1-Omni Của Alibaba: Tiên Phong Nhận Dạng Cảm Xúc Đa Mô Hình Bằng Học Tăng Cường
💡Bạn có quan tâm đến xu hướng mới nhất trong AI không?
Vậy thì, bạn không thể bỏ lỡ Anakin AI!
Anakin AI là nền tảng tất cả trong một cho tất cả các quy trình tự động hóa của bạn, tạo ra ứng dụng AI mạnh mẽ với một
Anakin AI là nền tảng tất cả trong một cho tất cả các quy trình tự động hóa của bạn, tạo ra ứng dụng AI mạnh mẽ với một Trình xây dựng ứng dụng No Code dễ sử dụng, với Deepseek, o3-mini-high của OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
Xây dựng ứng dụng AI mơ ước của bạn trong vài phút, không phải vài tuần với Anakin AI!
Xây dựng Quy trình Làm việc AI một cách dễ dàng với Anakin AI
Trí tuệ nhân tạo đã đạt được những bước tiến đáng kể trong việc hiểu biết giao tiếp của con người, nhưng việc nhận diện chính xác cảm xúc qua các phương thức khác nhau vẫn là một thách thức. Mô hình R1-Omni mới được Alibaba công bố gần đây đại diện cho một bước đột phá quan trọng trong lĩnh vực này, khẳng định nó là ứng dụng đầu tiên trong ngành về Học Tăng cường với Phần thưởng Xác minh được (RLVR) cho một mô hình ngôn ngữ lớn đa phương thức.
Một Cách Tiếp Cận Mới Đối Với Nhận Diện Cảm Xúc
Cảm xúc của con người rất phức tạp và được thể hiện qua nhiều kênh đồng thời – biểu cảm trên khuôn mặt, giọng nói, ngôn ngữ cơ thể và nội dung lời nói. Các hệ thống nhận diện cảm xúc truyền thống đã gặp khó khăn trong việc tích hợp các tín hiệu đa dạng này một cách hiệu quả, thường không thể nắm bắt sự tương tác tinh tế giữa các tín hiệu hình ảnh và âm thanh mà con người xử lý một cách bản năng.
R1-Omni giải quyết thách thức này bằng cách tận dụng một phương pháp học tăng cường tinh vi cho phép mô hình phát triển sự hiểu biết tinh vi hơn về cách các phương thức khác nhau góp phần vào trạng thái cảm xúc. Được xây dựng dựa trên nền tảng mã nguồn mở HumanOmni-0.5B, mô hình đổi mới này thể hiện khả năng vượt trội trong lý luận, hiểu biết và tổng quát so với các hệ thống được huấn luyện theo cách truyền thống.
"Chúng tôi tập trung vào việc nhận diện cảm xúc, một nhiệm vụ mà cả hai phương thức hình ảnh và âm thanh đều đóng vai trò quan trọng, để xác thực tiềm năng kết hợp RLVR với mô hình đa phương thức," các nhà nghiên cứu đứng sau R1-Omni chú thích trong tài liệu kỹ thuật của họ.
Kiến Trúc Kỹ Thuật và Đổi Mới
Tại cốt lõi, R1-Omni kết hợp xử lý đa phương thức tiên tiến với các kỹ thuật học tăng cường để tạo ra một hệ thống nhận diện cảm xúc giải thích được và chính xác hơn. Mô hình xử lý đầu vào hình ảnh nhờ vào tháp thị giác SigLIP-base-patch16-224 và xử lý âm thanh qua Whisper-large-v3, một mô hình xử lý âm thanh mạnh mẽ có khả năng nắm bắt các tín hiệu giọng nói tinh tế truyền tải thông tin cảm xúc.
Điều phân biệt R1-Omni với những cách tiếp cận trước đó là phương pháp đào tạo của nó. Trong khi việc tinh chỉnh có giám sát truyền thống (SFT) đào tạo các mô hình để dự đoán nhãn cảm xúc dựa trên các ví dụ đã được chú thích, R1-Omni sử dụng khung học tăng cường trong đó mô hình không chỉ được thưởng cho các dự đoán chính xác, mà còn cho việc thể hiện các con đường lý luận có thể xác minh dẫn đến những dự đoán đó.
Cách tiếp cận mới này thúc đẩy các kết nối có thể giải thích giữa các đầu vào đa phương thức và đầu ra cảm xúc. Thay vì chỉ đơn giản là gán một cảm xúc là "tức giận," R1-Omni có thể thể hiện các tín hiệu hình ảnh cụ thể (lông mày nhíu lại, cơ mặt căng thẳng) và các đặc điểm âm thanh (giọng nói cao, nói nhanh) góp phần vào đánh giá của nó - một khả năng thiết yếu để xây dựng lòng tin trong các hệ thống AI được triển khai trong các bối cảnh nhạy cảm.
Những Năng Lực Chính và Hiệu Suất
R1-Omni chứng tỏ ba tiến bộ chính so với các hệ thống nhận diện cảm xúc trước đó:
Năng lực lý luận nâng cao: Mô hình cung cấp các giải thích chi tiết cho các phân loại của nó, kết nối các quan sát đa phương thức cụ thể với các kết luận cảm xúc. Sự minh bạch này đại diện cho sự cải thiện đáng kể so với các cách tiếp cận "hộp đen" cung cấp phân loại mà không có giải thích.
Năng lực hiểu biết cải thiện: So với các mô hình được đào tạo thông qua việc tinh chỉnh có giám sát, R1-Omni thể hiện độ chính xác vượt trội hơn đáng kể trong các nhiệm vụ nhận diện cảm xúc. Điều này cho thấy phương pháp học tăng cường giúp phát triển các biểu diễn tinh vi hơn của các trạng thái cảm xúc, phù hợp hơn với đánh giá của con người.
Năng lực tổng quát mạnh mẽ: Có lẽ ấn tượng nhất, R1-Omni cho thấy hiệu suất đáng kể trên dữ liệu ngoài phân phối - các kịch bản khác với các ví dụ mà nó đã được đào tạo. Khả năng tổng quát vượt ra ngoài các bối cảnh đào tạo cụ thể là rất quan trọng cho các ứng dụng thực tế.
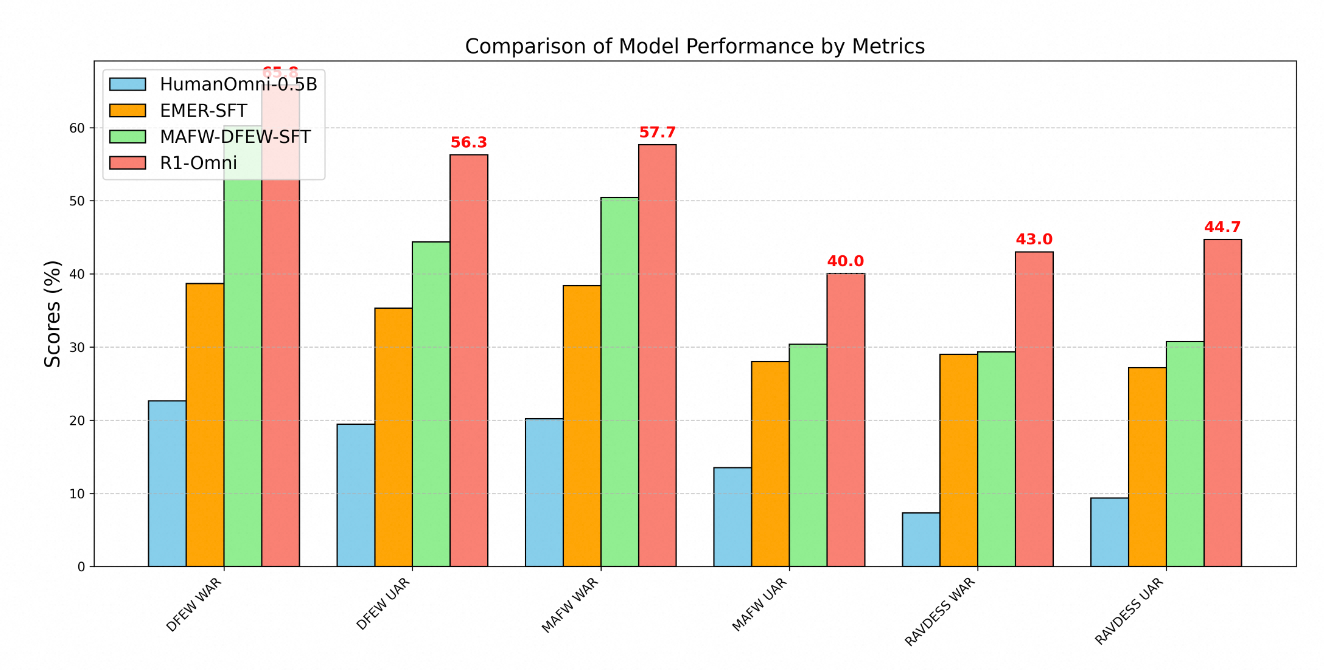
Ưu thế kỹ thuật của R1-Omni được thể hiện rõ qua các chỉ số hiệu suất trên nhiều chuẩn nhận diện cảm xúc. Thử nghiệm trên ba tập dữ liệu chính - DFEW, MAFW và RAVDESS - cung cấp đánh giá toàn diện về khả năng của mô hình trên cả dữ liệu trong phân phối và ngoài phân phối.
Trên tập dữ liệu DFEW, R1-Omni đạt được tỷ lệ hồi tưởng trung bình có trọng số (WAR) là 65.83% và tỷ lệ hồi tưởng trung bình không có trọng số (UAR) là 56.27%, vượt trội hơn đáng kể cả mô hình HumanOmni-0.5B cơ bản (22.64% WAR) và mô hình MAFW-DFEW-SFT (60.23% WAR) được tinh chỉnh trực tiếp trên các tập huấn luyện.
Thậm chí còn đáng lưu ý hơn là hiệu suất của mô hình trên dữ liệu ngoài phân phối. Khi được thử nghiệm trên tập dữ liệu RAVDESS, mà không được sử dụng trong quá trình đào tạo, R1-Omni đạt được 43% WAR và 44.69% UAR – tốt hơn đáng kể so với mô hình cơ sở (7.33% WAR) và cao hơn nhiều so với các lựa chọn tinh chỉnh có giám sát (29.33% WAR).
Phương Pháp Đào Tạo
Việc phát triển R1-Omni theo sau một quy trình đào tạo hai giai đoạn tinh vi:
Đầu tiên, trong giai đoạn "bắt đầu lạnh", các nhà nghiên cứu đã khởi tạo mô hình bằng cách sử dụng HumanOmni-0.5B và tinh chỉnh nó trên một tập dữ liệu được lựa chọn cẩn thận gồm 232 mẫu từ tập dữ liệu Lý luận Cảm xúc Đa phương thức Giải thích được và 348 mẫu từ tập dữ liệu HumanOmni. Điều này cung cấp các khả năng cơ bản đồng thời nhấn mạnh các quy trình lý luận có thể giải thích.
Giai đoạn thứ hai sử dụng Học Tăng cường với Phần thưởng Xác minh bằng cách sử dụng một tập dữ liệu lớn hơn đáng kể bao gồm 15,306 mẫu video từ các tập dữ liệu MAFW và DFEW. Giai đoạn học tăng cường này là rất quan trọng trong việc phát triển năng lực lý luận và tổng quát tiên tiến của mô hình.
Trong suốt quá trình đào tạo, quy trình này ưu tiên không chỉ phân loại chính xác mà còn phát triển các con đường lý luận có thể xác minh. Các ví dụ đào tạo thường bao gồm cả nhãn cảm xúc và các quy trình tư duy có cấu trúc kết nối các quan sát với các kết luận. Cách tiếp cận này khuyến khích mô hình phát triển các kết nối có thể giải thích thay vì chỉ đơn thuần học các mối tương quan thống kê.
Các Ứng Dụng Thực Tế
Các khả năng mà R1-Omni thể hiện mở ra nhiều khả năng trong các lĩnh vực khác nhau:
Hỗ Trợ Sức Khỏe Tâm Thần: Mô hình có thể hỗ trợ các nhà trị liệu bằng cách cung cấp đánh giá khách quan về trạng thái cảm xúc của bệnh nhân, có khả năng xác định các tín hiệu cảm xúc tinh tế có thể bị bỏ lỡ.
Giáo Dục: Các hệ thống tương tự có thể giúp các giáo viên đánh giá sự tham gia của học sinh và phản ứng cảm xúc đối với tài liệu học tập, tạo điều kiện cho các phương pháp giáo dục phản hồi tốt hơn.
Dịch Vụ Khách Hàng: Công nghệ của R1-Omni có thể nâng cao các hệ thống dịch vụ khách hàng tự động bằng cách nhận diện và phản ứng một cách phù hợp với cảm xúc của khách hàng, cải thiện tỷ lệ hài lòng.
Phân Tích Nội Dung: Mô hình có thể phân tích nội dung cảm xúc trong video và bản ghi âm để phục vụ nghiên cứu thị trường, phân tích truyền thông và kiểm duyệt nội dung.
Tính giải thích của mô hình đặc biệt có giá trị trong các bối cảnh này, vì nó cho phép người vận hành hiểu và xác thực lý luận đứng sau các đánh giá cảm xúc do AI tạo ra. Sự minh bạch này xây dựng lòng tin và tạo điều kiện cho hợp tác hiệu quả giữa con người và AI, điều cần thiết để áp dụng rộng rãi trong các lĩnh vực nhạy cảm.
Phát Triển Tương Lai
Theo lộ trình của dự án, các phát triển trong tương lai cho R1-Omni bao gồm việc tích hợp mã nguồn của HumanOmni, phát hành quy trình tái sản xuất chi tiết hơn, mã nguồn mở tất cả dữ liệu đào tạo, phát triển khả năng suy diễn cho dữ liệu âm thanh và video đơn, và phát hành kết quả từ phiên bản mô hình lớn hơn 7B.
Các cải tiến dự kiến này sẽ tăng cường khả năng tiếp cận và hữu ích của mô hình cho các nhà nghiên cứu và phát triển, có khả năng thúc đẩy sự tiến bộ trong lĩnh vực nhận diện cảm xúc đa phương thức.
Kết Luận
R1-Omni của Alibaba đại diện cho một bước tiến quan trọng trong nhận diện cảm xúc dựa trên AI thông qua việc ứng dụng đổi mới các kỹ thuật học tăng cường vào việc hiểu biết đa phương thức. Bằng cách tăng cường khả năng lý luận, cải thiện độ chính xác và chứng minh khả năng tổng quát vượt trội cho các kịch bản mới, R1-Omni đẩy lùi giới hạn của những gì có thể trong AI cảm xúc.
Khi chúng ta tiến tới giao tiếp người-máy tự nhiên hơn, các hệ thống như R1-Omni có thể nhận diện và phản ứng chính xác với cảm xúc của con người qua nhiều kênh giao tiếp khác nhau sẽ đóng vai trò ngày càng quan trọng. Sự nhấn mạnh của mô hình về tính giải thích và tổng quát giải quyết những hạn chế nghiêm trọng của các phương pháp trước đó, thiết lập tiêu chuẩn mới cho công nghệ nhận diện cảm xúc có trách nhiệm và hiệu quả.
Bằng cách kết hợp các thế mạnh của học tăng cường với khả năng xử lý đa phương thức, Alibaba đã tạo ra không chỉ một hệ thống nhận diện cảm xúc được cải thiện, mà có thể là một hình mẫu mới cho cách mà các hệ thống AI có thể học để hiểu các phức tạp tinh tế của giao tiếp con người.