Dans ce cas, vous ne pouvez pas manquer Anakin AI !
Anakin AI est une plateforme tout-en-un pour automatiser vos flux de travail, créer des applications AI puissantes avec un constructeur d'applications sans code facile à utiliser, avec Deepseek, l'o3-mini-high d'OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
Créez votre application AI de rêve en quelques minutes, pas en semaines avec Anakin AI !

L'intelligence artificielle a fait des progrès remarquables dans la compréhension de la communication humaine, mais la reconnaissance précise des émotions à travers différentes modalités reste un défi. Le modèle R1-Omni récemment dévoilé par Alibaba représente une avancée significative dans ce domaine, s'établissant comme la première application de l'apprentissage par renforcement avec une récompense vérifiable (RLVR) appliquée à un modèle de langage multimodal omni-large.
Une nouvelle approche de la reconnaissance des émotions
Les émotions humaines sont complexes et s'expriment à travers plusieurs canaux simultanément : expressions faciales, tonalités vocales, langage corporel et contenu verbal. Les systèmes de reconnaissance des émotions traditionnels ont du mal à intégrer efficacement ces signaux divers, échouant souvent à capturer l'interaction nuancée entre les indices visuels et auditifs que les humains traitent instinctivement.
R1-Omni s'attaque à ce défi en s'appuyant sur une approche d'apprentissage par renforcement sophistiquée qui permet au modèle de développer une compréhension plus affinée de la manière dont différentes modalités contribuent aux états émotionnels. S'appuyant sur la base open-source HumanOmni-0.5B, ce modèle innovant démontre des capacités supérieures en raisonnement, compréhension et généralisation par rapport aux systèmes entraînés de manière conventionnelle.
"Nous nous concentrons sur la reconnaissance des émotions, une tâche où les modalités visuelles et audio jouent des rôles cruciaux, pour valider le potentiel de la combinaison de RLVR avec le modèle Omni," notent les chercheurs derrière R1-Omni dans leur documentation technique.
Architecture technique et innovation
Au cœur de R1-Omni se trouve la combinaison d'un traitement multimodal avancé avec des techniques d'apprentissage par renforcement pour créer un système de reconnaissance des émotions plus explicable et précis. Le modèle traite les entrées visuelles en utilisant la tour de vision SigLIP-base-patch16-224 et gère l'audio via Whisper-large-v3, un puissant modèle de traitement audio capable de capturer des indices vocaux subtils qui transmettent des informations émotionnelles.
Ce qui distingue R1-Omni des approches précédentes est sa méthodologie d'entraînement. Alors que l'ajustement fin supervisé traditionnel (SFT) forme des modèles à prédire des étiquettes d'émotion en fonction d'exemples annotés, R1-Omni emploie un cadre d'apprentissage par renforcement où le modèle est récompensé non seulement pour des prédictions correctes, mais pour avoir démontré des chemins de raisonnement vérifiables menant à ces prédictions.
Cette approche novatrice favorise des connexions explicables entre les entrées multimodales et les sorties émotionnelles. Plutôt que de simplement étiqueter une émotion comme "en colère", R1-Omni peut articuler des indices visuels spécifiques (sourcils froncés, muscles faciaux tendus) et des caractéristiques audio (voix élevée, discours rapide) qui contribuent à son évaluation - une capacité cruciale pour établir la confiance dans les systèmes d'IA déployés dans des contextes sensibles.
Capacités clés et performances
R1-Omni démontre trois avancées clés par rapport aux systèmes de reconnaissance des émotions précédents :
- Capacité de raisonnement améliorée : Le modèle fournit des explications détaillées pour ses classifications, reliant des observations multimodales spécifiques à des conclusions émotionnelles. Cette transparence représente une amélioration significative par rapport aux approches en "boîte noire" qui offrent des classifications sans explications.
- Capacité de compréhension améliorée : Comparé aux modèles formés par ajustement fin supervisé, R1-Omni démontre une précision substantiellement meilleure dans les tâches de reconnaissance des émotions. Cela suggère que l'approche d'apprentissage par renforcement aide à développer des représentations plus nuancées des états émotionnels qui s'alignent mieux avec les jugements humains.
- Capacité de généralisation renforcée : Peut-être le plus impressionnant, R1-Omni présente des performances remarquables sur des données hors distribution - des scénarios différents de ses exemples d'entraînement. Cette capacité à généraliser au-delà des contextes d'entraînement spécifiques est cruciale pour des applications réelles.
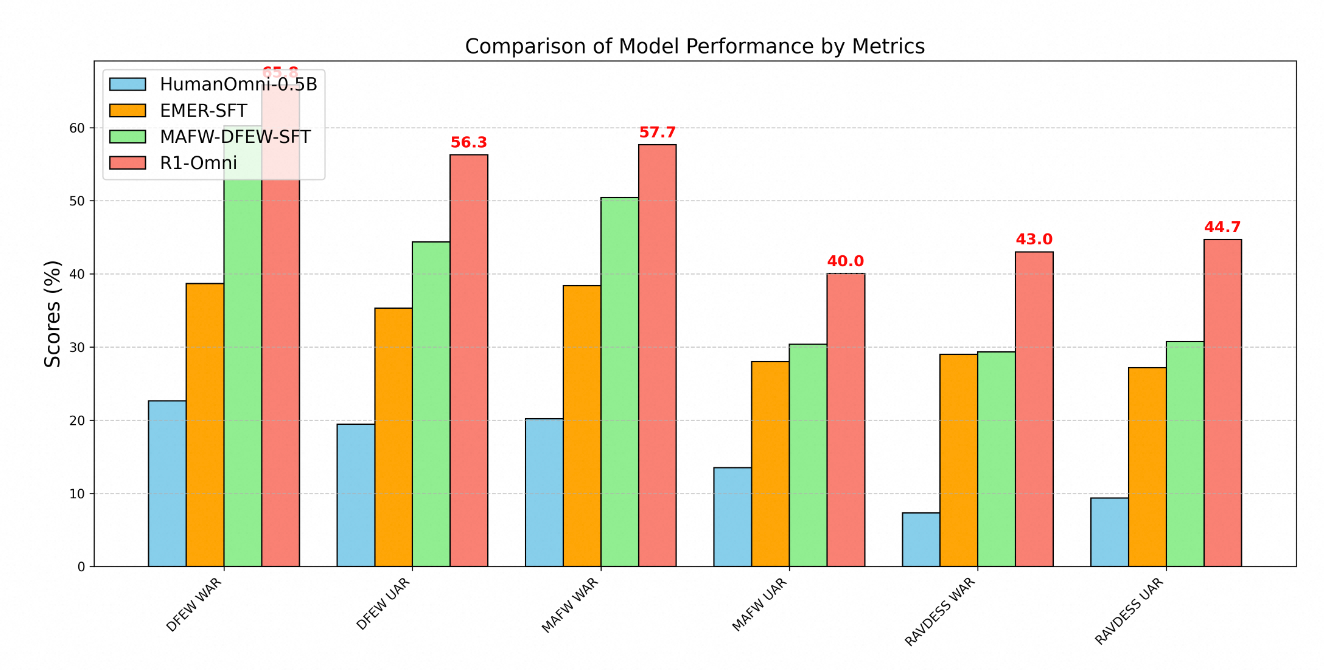
La supériorité technique de R1-Omni est clairement démontrée par des métriques de performance à travers plusieurs benchmarks de reconnaissance des émotions. Les tests sur trois ensembles de données clés - DFEW, MAFW et RAVDESS - fournissent une évaluation complète des capacités du modèle sur les données à distribution et hors distribution.
Sur l'ensemble de données DFEW, R1-Omni a atteint un rappel moyen pondéré (WAR) de 65,83 % et un rappel moyen non pondéré (UAR) de 56,27 %, surpassant considérablement à la fois le modèle de référence HumanOmni-0.5B (22,64 % WAR) et le modèle MAFW-DFEW-SFT (60,23 % WAR) qui a été directement ajusté sur les ensembles d'entraînement.
Encore plus révélateur est la performance du modèle sur les données hors distribution. Lorsqu'il a été testé sur l'ensemble de données RAVDESS, qui n'a pas été utilisé lors de l'entraînement, R1-Omni a atteint 43 % WAR et 44,69 % UAR - bien mieux que le modèle de base (7,33 % WAR) et substantiellement supérieur aux alternatives ajustées par supervision (29,33 % WAR).
Méthodologie d'entraînement
Le développement de R1-Omni a suivi un processus d'entraînement sophistiqué en deux étapes :
Tout d'abord, lors de la phase de "demarrage à froid", les chercheurs ont initialisé le modèle en utilisant HumanOmni-0.5B et l'ont ajusté sur un ensemble de données soigneusement sélectionné comprenant 232 échantillons de l'ensemble de données Explainable Multimodal Emotion Reasoning et 348 échantillons de l'ensemble de données HumanOmni. Cela a permis de fournir des capacités fondamentales tout en mettant l'accent sur les processus de raisonnement explicables.
La seconde étape a employé l'apprentissage par renforcement avec récompense vérifiable en utilisant un ensemble de données considérablement plus large comprenant 15 306 échantillons vidéo des ensembles de données MAFW et DFEW. Cette phase d'apprentissage par renforcement a été cruciale pour développer les capacités avancées de raisonnement et de généralisation du modèle.
Tout au long de l'entraînement, le processus a donné la priorité non seulement à la classification précise, mais aussi au développement de chemins de raisonnement vérifiables. Les exemples d'entraînement comprenaient généralement à la fois des étiquettes d'émotion et des processus de pensée structurés reliant des observations à des conclusions. Cette approche encourageait le modèle à développer des connexions explicables plutôt que d'apprendre simplement des corrélations statistiques.
Applications pratiques
Les capacités démontrées par R1-Omni ouvrent de nombreuses possibilités dans divers domaines :
- Soutien à la santé mentale : Le modèle pourrait aider les thérapeutes en fournissant des évaluations objectives des états émotionnels des patients, identifiant potentiellement des indices émotionnels subtils qui pourraient autrement passer inaperçus.
- Éducation : Des systèmes similaires pourraient aider les enseignants à évaluer l'engagement des étudiants et les réponses émotionnelles aux matériaux d'apprentissage, permettant des approches éducatives plus réactives.
- Service client : La technologie de R1-Omni pourrait améliorer les systèmes de service client automatisés en reconnaissant et en répondant de manière appropriée aux émotions des clients, améliorant ainsi les taux de satisfaction.
- Analyse de contenu : Le modèle pourrait analyser le contenu émotionnel dans des vidéos et des enregistrements audio pour des études de marché, des analyses médiatiques et de la modération de contenu.
L'explicabilité du modèle est particulièrement précieuse dans ces contextes, car elle permet aux opérateurs humains de comprendre et de valider le raisonnement derrière les évaluations émotionnelles générées par l'IA. Cette transparence renforce la confiance et facilite une collaboration efficace homme-IA, essentielle pour une adoption généralisée dans des domaines sensibles.
Développement futur
Selon la feuille de route du projet, les développements futurs pour R1-Omni comprennent l'intégration du code source de HumanOmni, la publication d'un processus de reproduction plus détaillé, l'ouverture de toutes les données d'entraînement, le développement de capacités d'inférence pour des données de vidéo unique et d'audio unique, et la publication des résultats d'une version plus grande du modèle de 7B.
Ces améliorations prévues augmenteront encore l'accessibilité et l'utilité du modèle pour les chercheurs et les développeurs, accélérant potentiellement les progrès dans le domaine de la reconnaissance des émotions multimodales.
Conclusion
Le R1-Omni d'Alibaba représente une avancée significative dans la reconnaissance des émotions basé sur l'IA grâce à son application innovante des techniques d'apprentissage par renforcement à la compréhension multimodale. En améliorant les capacités de raisonnement, en améliorant la précision et en démontrant une généralisation supérieure dans des scénarios nouveaux, R1-Omni repousse les limites de ce qui est possible dans l'IA émotionnelle.
Alors que nous nous orientons vers une interaction homme-machine plus naturelle, des systèmes comme R1-Omni, capables de reconnaître et de répondre avec précision aux émotions humaines à travers différents canaux de communication, joueront un rôle de plus en plus important. L'accent mis par le modèle sur l'explicabilité et la généralisation répond à des limitations critiques des approches précédentes, établissant une nouvelle norme pour la technologie de reconnaissance des émotions responsable et efficace.
En combinant les forces de l'apprentissage par renforcement avec des capacités de traitement multimodal, Alibaba a créé non seulement un système de reconnaissance des émotions amélioré, mais potentiellement un nouveau paradigme sur la manière dont les systèmes d'IA peuvent apprendre à comprendre les subtilités complexes de la communication humaine.