El Modelo R1-Omni de Alibaba: Pionero en el Reconocimiento Multimodal de Emociones con Aprendizaje por Refuerzo
💡¿Interesado en la última tendencia en IA?
¡Entonces no puedes perderte Anakin AI!
Anakin AI es una plataforma todo-en-uno para toda tu automatización de flujos de trabajo, crea aplicaciones de IA poderosas con un Creador de Aplicaciones sin Código fácil de usar, con Deepseek, o3-mini-high de OpenAI, Claude 3.7
Anakin AI es una plataforma todo-en-uno para toda tu automatización de flujos de trabajo, crea aplicaciones de IA poderosas con un Creador de Aplicaciones sin Código fácil de usar, con Deepseek, o3-mini-high de OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
¡Construye tu aplicación de IA soñada en minutos, no en semanas, con Anakin AI!
Construye fácilmente flujos de trabajo de IA Agente con Anakin AI
La inteligencia artificial ha logrado avances notables en la comprensión de la comunicación humana, pero reconocer con precisión las emociones a través de diferentes modalidades sigue siendo un desafío. El modelo R1-Omni recientemente presentado por Alibaba representa un avance significativo en este ámbito, estableciéndose como la primera aplicación de la industria de Aprendizaje por Refuerzo con Recompensa Verificable (RLVR) para un modelo de lenguaje multimodal grande Omni.
Un Nuevo Enfoque para el Reconocimiento de Emociones
Las emociones humanas son complejas y se expresan a través de múltiples canales simultáneamente: expresiones faciales, tonos de voz, lenguaje corporal y contenido verbal. Los sistemas de reconocimiento de emociones tradicionales han tenido dificultades para integrar estas señales diversas de manera efectiva, a menudo fallando en capturar la interacción matizada entre las pistas visuales y auditivas que los humanos procesan instintivamente.
R1-Omni aborda este desafío aprovechando un enfoque sofisticado de aprendizaje por refuerzo que permite al modelo desarrollar una comprensión más refinada de cómo las diferentes modalidades contribuyen a los estados emocionales. Basado en la fundación de código abierto HumanOmni-0.5B, este modelo innovador demuestra capacidades superiores en razonamiento, comprensión y generalización en comparación con sistemas entrenados de manera convencional.
"Nos enfocamos en el reconocimiento de emociones, una tarea donde tanto las modalidades visuales como las auditivas juegan roles cruciales, para validar el potencial de combinar RLVR con el modelo Omni", señala los investigadores detrás de R1-Omni en su documentación técnica.
Arquitectura Técnica e Innovación
En su núcleo, R1-Omni combina procesamiento multimodal avanzado con técnicas de aprendizaje por refuerzo para crear un sistema de reconocimiento de emociones más explicable y preciso. El modelo procesa entradas visuales utilizando la torre de visión SigLIP-base-patch16-224 y gestiona el audio a través de Whisper-large-v3, un poderoso modelo de procesamiento de audio capaz de capturar pistas vocales sutiles que transmiten información emocional.
Lo que distingue a R1-Omni de enfoques anteriores es su metodología de entrenamiento. Mientras que el ajuste fino (SFT) supervisado tradicional entrena modelos para predecir etiquetas de emociones basadas en ejemplos anotados, R1-Omni emplea un marco de aprendizaje por refuerzo donde el modelo es recompensado no solo por predicciones correctas, sino por demostrar caminos de razonamiento verificables que conducen a esas predicciones.
Este enfoque novedoso promueve conexiones explicables entre entradas multimodales y salidas emocionales. En lugar de simplemente etiquetar una emoción como "enojado", R1-Omni puede articular pistas visuales específicas (cejas fruncidas, músculos faciales tensos) y características de audio (voz levantada, discurso rápido) que contribuyen a su evaluación, una capacidad crucial para generar confianza en los sistemas de IA desplegados en contextos sensibles.
Capacidades Clave y Rendimiento
R1-Omni demuestra tres avances clave sobre sistemas de reconocimiento de emociones anteriores:
Capacidad de Razonamiento Mejorada: El modelo proporciona explicaciones detalladas para sus clasificaciones, conectando observaciones multimodales específicas con conclusiones emocionales. Esta transparencia representa una mejora significativa sobre enfoques de "caja negra" que ofrecen clasificaciones sin explicaciones.
Capacidad de Comprensión Mejorada: En comparación con modelos entrenados a través de ajuste fino supervisado, R1-Omni demuestra una precisión sustancialmente mejor en tareas de reconocimiento emocional. Esto sugiere que el enfoque de aprendizaje por refuerzo ayuda a desarrollar representaciones más matizadas de estados emocionales que se alinean mejor con los juicios humanos.
Capacidad de Generalización Más Fuerte: Quizás lo más impresionante, R1-Omni exhibe un rendimiento notable en datos fuera de distribución, escenarios que difieren de sus ejemplos de entrenamiento. Esta capacidad de generalizar más allá de contextos de entrenamiento específicos es crucial para aplicaciones del mundo real.
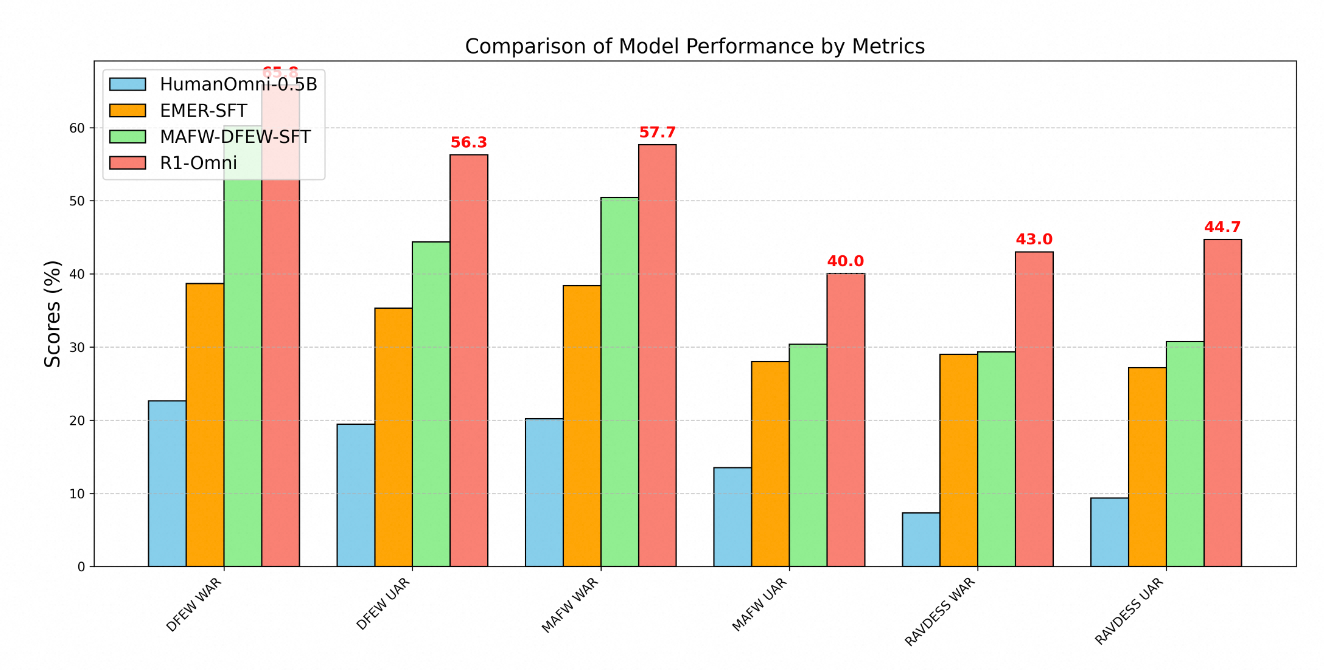
La superioridad técnica de R1-Omni se demuestra claramente a través de métricas de rendimiento en múltiples benchmarks de reconocimiento de emociones. Las pruebas en tres conjuntos de datos clave: DFEW, MAFW y RAVDESS proporcionan una evaluación integral de las capacidades del modelo tanto en datos de distribución como fuera de distribución.
En el conjunto de datos DFEW, R1-Omni logró un recall promedio ponderado (WAR) del 65.83% y un recall promedio no ponderado (UAR) del 56.27%, superando considerablemente tanto al modelo base HumanOmni-0.5B (22.64% WAR) como al modelo MAFW-DFEW-SFT (60.23% WAR) que fue ajustado directamente en los conjuntos de entrenamiento.
Aún más revelador es el rendimiento del modelo en datos fuera de distribución. Al probarse en el conjunto de datos RAVDESS, que no se utilizó durante el entrenamiento, R1-Omni logró un 43% WAR y un 44.69% UAR, dramáticamente mejor que el modelo base (7.33% WAR) y sustancialmente superior a alternativas ajustadas mediante fine-tuning supervisado (29.33% WAR).
Metodología de Entrenamiento
El desarrollo de R1-Omni siguió un sofisticado proceso de entrenamiento en dos etapas:
Primero, en la fase de "inicio en frío", los investigadores inicializaron el modelo usando HumanOmni-0.5B y lo ajustaron en un conjunto de datos cuidadosamente curado que consiste en 232 muestras del conjunto de datos de Razonamiento Emocional Multimodal Explicable y 348 muestras del conjunto de datos HumanOmni. Esto proporcionó capacidades fundamentales mientras se enfatizaban los procesos de razonamiento explicables.
La segunda etapa empleó Aprendizaje por Refuerzo con Recompensa Verificable utilizando un conjunto de datos sustancialmente más grande que consta de 15,306 muestras de video de los conjuntos de datos MAFW y DFEW. Esta fase de aprendizaje por refuerzo fue crítica para desarrollar las capacidades avanzadas de razonamiento y generalización del modelo.
A lo largo del entrenamiento, el proceso priorizó no solo la clasificación precisa sino también el desarrollo de caminos de razonamiento verificables. Los ejemplos de entrenamiento típicamente incluían tanto etiquetas de emociones como procesos de pensamiento estructurados que conectan observaciones con conclusiones. Este enfoque alentó al modelo a desarrollar conexiones explicables en lugar de simplemente aprender correlaciones estadísticas.
Aplicaciones en el Mundo Real
Las capacidades demostradas por R1-Omni abren numerosas posibilidades en varias áreas:
Apoyo en Salud Mental: El modelo podría ayudar a los terapeutas proporcionando evaluaciones objetivas de los estados emocionales de los pacientes, identificando potencialmente pistas emocionales sutiles que de otro modo podrían pasarse por alto.
Educación: Sistemas similares podrían ayudar a los profesores a medir el compromiso y las respuestas emocionales de los estudiantes a los materiales de aprendizaje, permitiendo enfoques educativos más receptivos.
Servicio al Cliente: La tecnología de R1-Omni podría mejorar los sistemas automatizados de servicio al cliente al reconocer y responder apropiadamente a las emociones de los clientes, mejorando las tasas de satisfacción.
Análisis de Contenidos: El modelo podría analizar el contenido emocional en videos y grabaciones de audio para investigación de mercado, análisis de medios y moderación de contenidos.
La explicabilidad del modelo es particularmente valiosa en estos contextos, ya que permite a los operadores humanos entender y validar el razonamiento detrás de las evaluaciones emocionales generadas por IA. Esta transparencia genera confianza y facilita la colaboración efectiva entre humanos e IA, esencial para una adopción generalizada en dominios sensibles.
Desarrollo Futuro
Según la hoja de ruta del proyecto, los desarrollos futuros para R1-Omni incluyen la integración del código fuente de HumanOmni, la publicación de un proceso de reproducción más detallado, la open-sourcing de todos los datos de entrenamiento, el desarrollo de capacidades de inferencia para datos de modalidades de video y audio únicos, y la publicación de resultados de una versión más grande del modelo de 7B.
Estas mejoras planificadas aumentarán aún más la accesibilidad y utilidad del modelo para investigadores y desarrolladores, acelerando potencialmente el progreso en el campo del reconocimiento de emociones multimodal.
Conclusión
R1-Omni de Alibaba representa un avance significativo en el reconocimiento de emociones basado en IA a través de su innovadora aplicación de técnicas de aprendizaje por refuerzo para la comprensión multimodal. Al mejorar las capacidades de razonamiento, aumentar la precisión y demostrar una superior generalización a escenarios novedosos, R1-Omni empuja los límites de lo que es posible en la IA emocional.
A medida que avanzamos hacia una interacción más natural entre humanos y computadoras, sistemas como R1-Omni que pueden reconocer y responder con precisión a las emociones humanas a través de diferentes canales de comunicación jugarán un papel cada vez más importante. El énfasis del modelo en la explicabilidad y la generalización aborda limitaciones críticas de enfoques anteriores, estableciendo un nuevo estándar para la tecnología de reconocimiento de emociones responsable y efectiva.
Al combinar las fortalezas del aprendizaje por refuerzo con capacidades de procesamiento multimodal, Alibaba ha creado no solo un sistema de reconocimiento de emociones mejorado, sino potencialmente un nuevo paradigma para cómo los sistemas de IA pueden aprender a entender las complejidades sutiles de la comunicación humana.