Have you ever struggled to create consistent, high-quality videos that truly reflect your unique style or brand? You’re not alone. As content creators, marketers, or AI enthusiasts, we’ve all faced the frustration of inconsistent video outputs. But what if I told you there’s a powerful solution that can transform your video creation process?
Meet WAN 2.1 and its fine-tuned counterpart, WAN-LoRA-Trainer. This innovative AI model, combined with the Replicate platform, allows you to effortlessly train custom video styles using your own images and videos. By the end of this guide, you’ll know exactly how to harness WAN 2.1 to produce visually stunning, consistent videos every single time.
Let’s dive in!
What is WAN-LoRA-Trainer and Why Should You Care?
WAN-LoRA-Trainer is a specialized fine-tuning method based on WAN 2.1, utilizing LoRA (Low-Rank Adaptation) technology. Simply put, LoRA fine-tuning freezes most of the original model’s parameters, training only a small subset. This approach dramatically reduces computational costs and speeds up training without sacrificing quality.
Imagine crafting videos that consistently match your vision — no more unpredictable results or wasted hours tweaking outputs. WAN-LoRA-Trainer empowers you to create personalized AI models tailored precisely to your creative needs.
Step 1: Preparing Your Dataset — Quality Matters!
Your training dataset is the foundation of your model. Here’s how to prepare it effectively:
- Images: Use 5–30 high-quality images for focused concepts (like faces or objects). For broader styles or complex themes, aim for 20–100 images.
- Resolution: Ensure each image is at least 512×512 pixels. Larger images will automatically resize during training.
- Captions: Pair each image with a descriptive caption in a
.txtfile. Captions help the model grasp context and details.
Example:image1.jpg → image1.txt containing "A detailed photo of a steampunk-themed object."
Pro tip: Automate caption creation using AI tools like BLIP or Hugging Face models to save valuable time.
Step 2: Compress and Upload Your Dataset
Once your dataset is ready:
- Compress all images and captions into a single
.zipfile (e.g.,my_dataset.zip). - Upload this file to a publicly accessible URL using services like Google Drive, Amazon S3, or GitHub Pages.
Now, you’re ready to train!
Step 3: Training Your WAN-LoRA Model on Replicate
Replicate offers an intuitive, pay-as-you-go platform for training your WAN-LoRA model. Here’s how:
- Visit Replicate’s WAN-LoRA Trainer page.
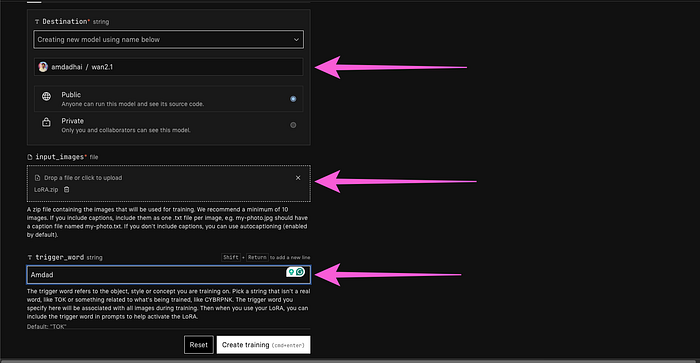
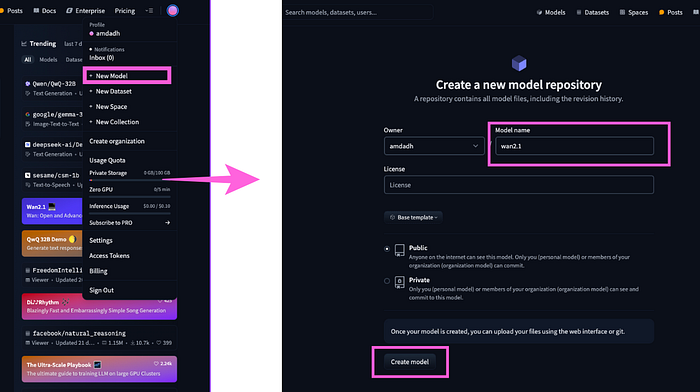
- First of all, click on destination and create a new model and name it whatever you want.
- After that in the input images section provide your zip file.
- Set your trigger word, trigger word is a specific word that identify your train model.
- Once you set up destination, input images, and trigger word, scroll down two steps so you'll find default 2000 steps. It is quite OK but you can increase it to 3000 to 4000 is recommended range.

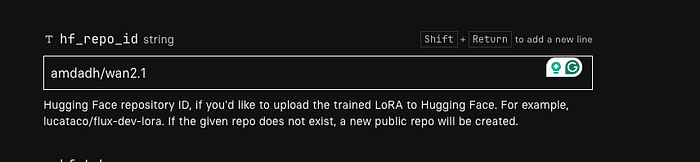
- After that head over to HF repo_id, it is hugging face repository ID. To get this ID visit hugging face and create your account> click on profile> create new model> name the model> hit on create model
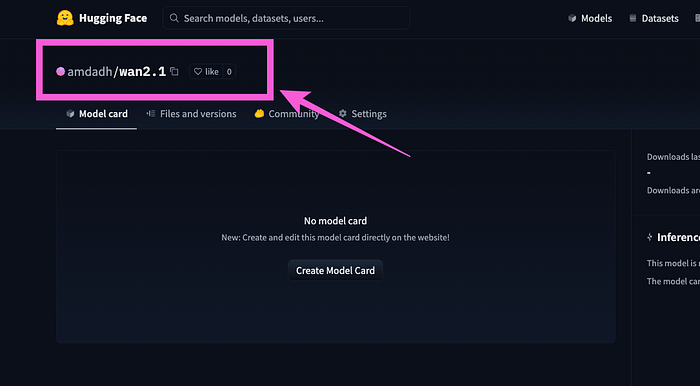
- Once you create the model you can copy the ID from the model description.
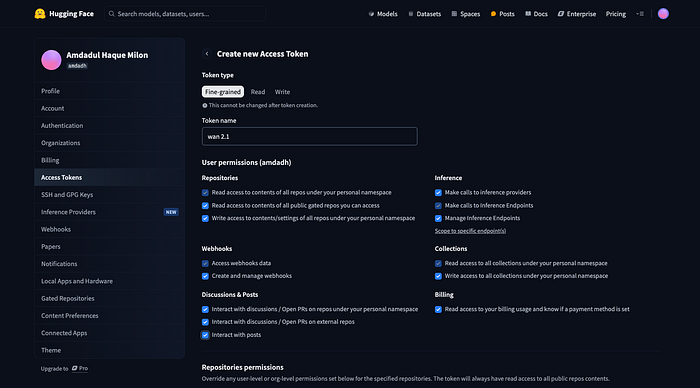
- Next, we need to provide HF token. It is also hugging face token. To get this token visit, hugging face again> click on setting> access token> create new token> name it> provide user permissions> click create token. Once you create a token, you will be able to copy your token. Just click on copy.
- Now paste this token to hf_token on replicate> and heat create training.
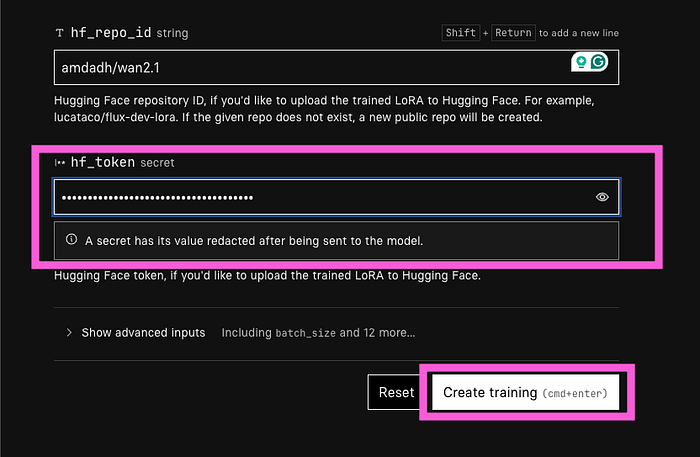
Now just wait and see the magic!
How to Easily Use Your Trained WAN-LoRA Model to Create Stunning Videos
Congratulations! You’ve successfully trained your WAN-LoRA model on Replicate. Now comes the exciting part — using your personalized model to effortlessly create consistent, high-quality videos.
Step 1: Access Your Trained LoRA URL
Once your training is complete, Replicate provides you with a unique URL pointing directly to your trained LoRA model. It typically looks something like this:https://huggingface.co/motimalu/wan-flat-color-v2/resolve/main/wan_flat_color_v2.safetensors
This URL is your golden ticket — it allows you to use your trained model virtually anywhere, even locally on your computer.
But there’s an even simpler, more streamlined way to create videos using your custom model.
Step 2: Effortlessly Generate Videos with Anakin AI
Instead of dealing with complex setups or local installations, you can leverage the intuitive Anakin AI platform. Here’s how easy it is:
- Visit the dedicated WAN 2.1 LoRA app on Anakin AI:
👉 WAN 2.1 LoRA Video Generator
Wan 2.1 LoRA | Anakin.ai
Instantly create stunning, personalized videos using your own trained WAN 2.1 LoRA models with Anakin AI.
anakin.ai
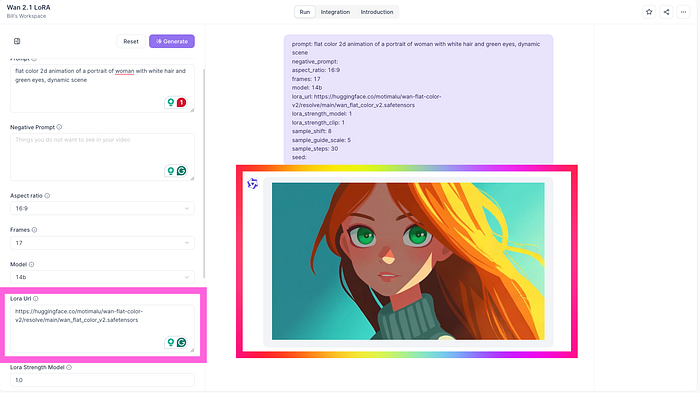
- Scroll down until you see the LoRA URL input field.
- Paste your trained LoRA URL directly into this field.
- Prompt & Negative Prompt: Clearly define what you want (and don’t want) in your video. Describe your scene vividly to achieve optimal results.
- Model Size Selection: Choose between two powerful WAN 2.1 versions:
- 14 Billion Parameters: Ideal for maximum quality and detail.
- 1 Billion Parameters: Perfect if you’re price-conscious or looking for quicker, cost-effective results.
Simply select the model size that best fits your budget and quality requirements.
Why Choose Anakin AI?
- Ease of Use: No technical headaches — just paste your URL and generate.
- Cost Flexibility: Choose the model size that matches your budget.
- Quality Results: Achieve consistent, professional-quality videos effortlessly.
Ready to see your creativity come alive?
✨ Start Creating Videos with Your WAN-LoRA Model on Anakin AI Now!
Cost Estimation: How Much Does WAN-LoRA Training Actually Cost?
Understanding the costs involved in training your WAN-LoRA model on Replicate is crucial for budgeting and planning. Replicate charges based on GPU usage per second, with different GPUs offering varying performance and pricing. Here’s a clear breakdown:
Example Cost Calculation for 3,000 Steps Training
Let’s assume your training takes approximately 7.5 hours on an Nvidia L40S GPU for 3,000 steps (this is an estimated duration; actual runtime may vary slightly depending on dataset complexity and settings):
- Hourly Cost (L40S GPU): $3.51
- Estimated Training Duration: 7.5 hours
- Total Estimated Cost: 7.5 hours × 3.51/hour = **26.33 USD**
If you choose a higher-performance GPU like the Nvidia A100, your training duration might reduce significantly (for example, down to approximately 5 hours):
- Hourly Cost (A100 GPU): $5.04
- Estimated Training Duration: 5 hours
- Total Estimated Cost: 5 hours × 5.04/hour = **25.20 USD**
While the Nvidia A100 GPU has a higher hourly rate, its faster processing speed often results in similar or even lower total costs compared to the L40S GPU — plus you benefit from quicker turnaround times.
Tips for Optimizing Your Training Costs and Results
To ensure you get the best value and highest quality from your WAN-LoRA training, consider these practical tips:
Dataset Quality:
- Avoid noisy or irrelevant images: High-quality, focused images yield better results.
- Include diverse perspectives: Different angles, lighting conditions, and backgrounds improve model generalization.
Hyperparameter Tuning:
- Adjust learning rate and gradient accumulation: Monitor early results and tweak these parameters accordingly.
- Use mixed precision (fp16): This significantly reduces memory usage and speeds up training without sacrificing quality.
Regular Testing:
- Generate sample outputs frequently: Check outputs every few epochs to ensure your model is on track.
- Refine captions or add data: If results aren’t meeting expectations, improve your captions or expand your dataset.
By carefully managing these factors, you can efficiently train your WAN-LoRA models on Replicate, keeping costs under control while consistently achieving outstanding results!
Automating Video Generation via API
For productivity enthusiasts, Replicate’s API lets you automate video creation effortlessly. Here’s a quick Python example:import replicatemodel = replicate.models.get("zsxkib/hunyuan-video-lora")
output = model.predict(
prompt="A futuristic cityscape at night",
lora_urls=["https://replicate.delivery/pbxt/your-trained-model.safetensors"],
resolution="720p",
num_frames=150,
fps=24,
guidance_scale=7.5
)print("Video URL:", output)
Automate your workflow and scale your video production seamlessly!
Final Thoughts: Consistency is Key
Creating consistent, visually appealing videos doesn’t have to be complicated or frustrating. With WAN-LoRA-Trainer and Replicate, you have powerful tools at your fingertips to effortlessly achieve your creative vision.
Imagine the possibilities — personalized branding, captivating storytelling, and impactful marketing campaigns — all consistently aligned with your unique style.
Are you ready to transform your video creation process and unleash your creativity?
Ready to Elevate Your Video Creation Game?
Harness the power of cutting-edge AI video production tools like WAN-LoRA-Trainer, HunyuanVideo, and more — all seamlessly integrated within one intuitive platform. Create cinematic masterpieces effortlessly and consistently.