Imagine a world where AI can not only understand the intricacies of human language but also engage in meaningful conversations about images. That's the world LLaVA is making a reality. As an open-source generative AI model, LLaVA bridges the gap between visual and textual understanding, offering capabilities reminiscent of, yet distinct from, OpenAI's GPT-4. Unlike its counterparts, LLaVA enables users to integrate images into chat conversations effortlessly, providing a platform for discussing image content, brainstorming ideas visually, and much more.
Leveraging a simpler model architecture and requiring significantly less training data, LLaVA represents a leap forward in making advanced AI more accessible and efficient. It's not just an alternative; it's a testament to the power of open-source collaboration in pushing the boundaries of what AI can achieve.
Article Summary:
LLaVA's introduction and its unique position as an open-source alternative to GPT-4V(vision).
A user-friendly guide to experiencing LLaVA through its web interface, making AI interaction more visual and intuitive.
The seamless process of running LLaVA locally, ensuring that cutting-edge AI is not just confined to high-end servers but is available right at your fingertips.
Do you want to run Local LLMs with an API instead of wasting time configuring them on your local laptop?
No worries, you can try out the latest Open Source LLM Online with Anakin AI! Here is a complete list of all the available open source models that you can test out right now within your browser:
The entry point for many into the world of LLaVA is its web interface—a testament to the model's user-centric design. Here, users can upload images and ask LLaVA to describe them, answer questions based on them, or even generate creative ideas. For instance, a picture of the contents of your fridge could lead LLaVA to suggest a variety of recipes, from fruit salads to smoothies or cakes, showcasing its ability to identify ingredients and propose relevant ideas.
This interaction is not limited to simple queries; LLaVA's prowess extends to making inferences, reasoning based on visual elements, and more. Whether it's identifying a movie from a poster, coding a website from a sketch, or explaining a joke depicted in a cartoon, LLaVA's online interface offers a glimpse into a future where AI understands not just our words, but our world.
In the next sections, we will delve deeper into how LLaVA operates, its installation process for local experimentation, and a practical guide to programming with this innovative tool, complete with examples of building a simple chatbot application using HuggingFace libraries on Google Colab. Stay tuned as we uncover the layers of LLaVA, the AI that's set to redefine our visual and conversational experiences.
To run LLaVA locally and understand its technical architecture, let's dive into a simplified, conceptual guide. While I can't access real-time or specific software documentation directly, I'll base this on common practices for similar AI models and theoretical knowledge of AI systems.
How Does LLaVA Work?
LLaVA's architecture is an innovative amalgamation of language processing and visual understanding, distinguished by two main components:
Vicuna: A pre-trained large language model based on advancements in natural language processing. It's designed to understand and generate human-like text responses.
CLIP: An image encoder that converts visual inputs into a format understandable by language models. It enables the model to 'see' images by translating them into descriptive tokens or embeddings.
Data Processing Workflow:
The interaction between Vicuna and CLIP is streamlined through a projection module, making the architecture both powerful and efficient.
When an image is inputted, CLIP encodes it into a series of tokens. These tokens, along with any text inputs, are fed to Vicuna, which processes them to generate a coherent response.
This process allows LLaVA to seamlessly blend text and visual information, leading to more enriched and context-aware interactions.
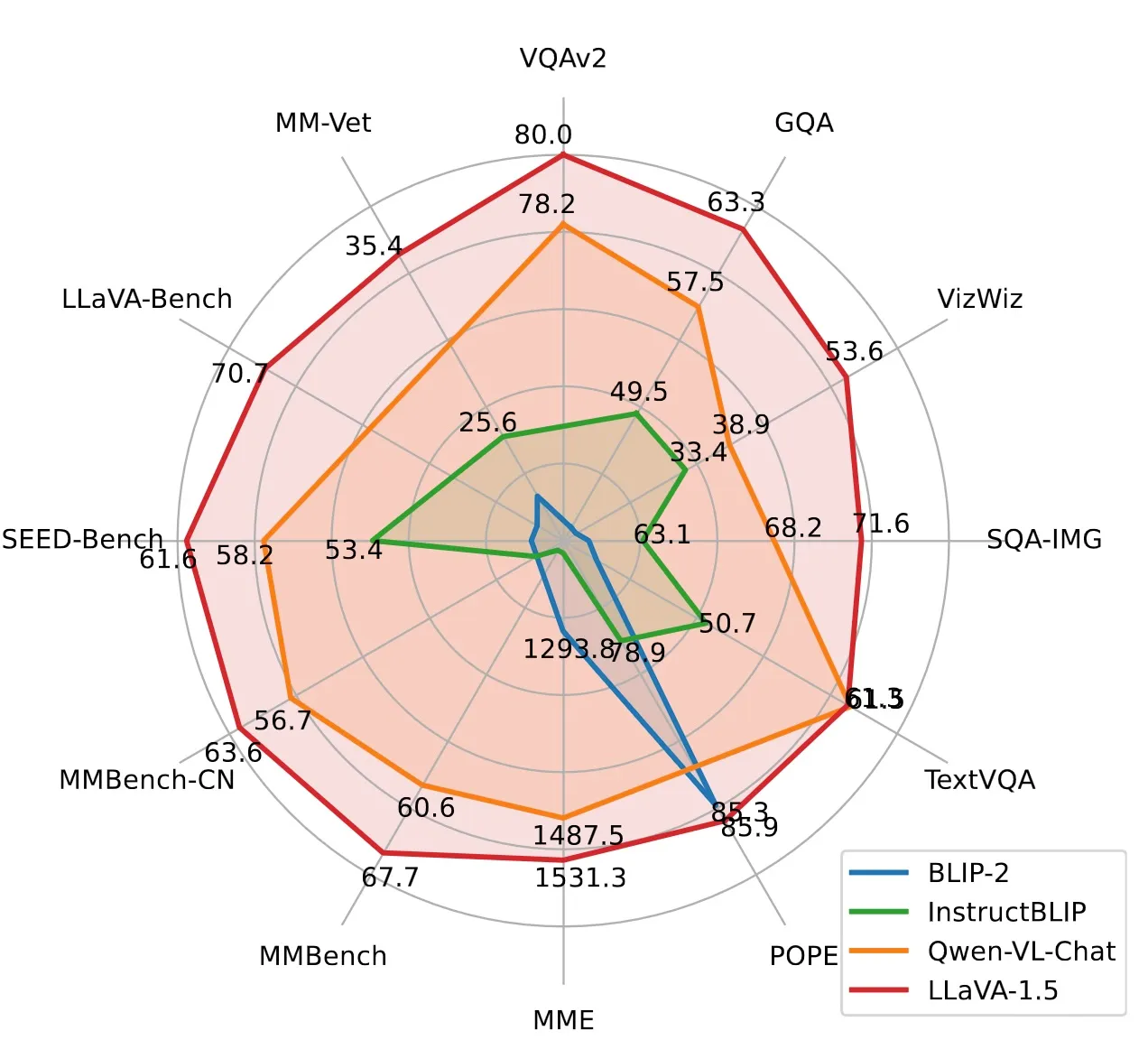
LLaVA Benchmarks
How to Run LLaVA Locally
Prerequisites to Run LlaVA Locally
System Requirements: To run LLaVA on a local machine, you typically need:
At least 8GB of RAM.
Around 4GB of free disk space.
A CPU with decent processing power; for enhanced performance, a GPU is recommended but not mandatory.
LLaVA can also run on a Raspberry Pi, showcasing its efficiency and adaptability.
Installation Steps:
Ensure Python 3.6 or later is installed on your machine.
It's likely that LLaVA, like other AI models, would be available via Python packages. Installation might involve a simple pip command:
pip install llava
For specific dependencies or additional setup, refer to LLaVA's official GitHub repository or documentation for accurate commands and additional setup instructions.
Running the Model:
Once installed, running LLaVA could involve executing a Python script or using a command-line interface, specifying parameters like the model version or the task (e.g., image-to-text conversion).
Detailed Examples to Run LlaVA Locally
To run LLaVA locally, integrate it using the Transformers library in Python. First, install the library and then load LLaVA with a specific model ID, applying quantization for efficiency. Here's a concise guide:
Install Necessary Libraries:
!pip install transformers
import torch
from transformers import pipeline, BitsAndBytesConfig
This streamlined approach allows you to interact with LLaVA efficiently, even on machines with limited resources, such as consumer-grade hardware or a Raspberry Pi.
How to Run LLaVA on Google Colab
Creating a Chatbot with HuggingFace and Gradio
Set Up Your Colab Environment:
Import necessary libraries and install Gradio and HuggingFace Transformers.
!pip install gradio transformers
import gradio as gr
from transformers import pipeline
Load LLaVA Model:
Utilize the model ID to load LLaVA through the HuggingFace pipeline.
Once everything is set up, you can interact with your LLaVA chatbot directly in the Colab notebook. Upload an image, ask a question, and receive a response.
This example provides a basic framework for training and applying LLaVA for image-based conversations. The actual implementation will depend on the LLaVA library's specifics and the current APIs provided by HuggingFace and Gradio. Always refer to the latest documentation for each library to ensure compatibility and access to the latest features.
Do you want to run Local LLMs with an API instead of wasting time configuring them on your local laptop?
No worries, you can try out the latest Open Source LLM Online with Anakin AI! Here is a complete list of all the available open source models that you can test out right now within your browser:
Exploring LLaVA offers a glimpse into the future of AI, blending visual comprehension with conversational capabilities. Through detailed guides, we've uncovered how to harness LLaVA's power locally, delved into its architecture, and demonstrated its practical applications. As LLaVA continues to evolve, it promises to democratize AI further, making sophisticated tools accessible to all. This journey through LLaVA's capabilities illustrates the model's potential not just for developers but for anyone curious about the intersection of AI, language, and vision.