In the ever-evolving landscape of artificial intelligence, Llama 2 stands out as a beacon of innovation. As an advanced Large Language Model (LLM), Llama 2 has captured the imagination of tech enthusiasts, developers, and AI aficionados alike. Its ability to understand and generate human-like text has paved the way for a multitude of applications, from crafting compelling content to providing coding assistance and beyond. Yet, the true magic of Llama 2 unfolds when it is run locally, offering users unparalleled privacy, control, and offline accessibility. Enter LM Studio, a game-changer in the realm of AI, making the local deployment of Llama 2 and other LLMs a breeze for both Mac and Windows users. This fusion of cutting-edge AI with user-friendly software heralds a new era in personal and professional AI utilization.
Llama 2: A cutting-edge LLM that's revolutionizing content creation, coding assistance, and more with its advanced AI capabilities.
Local Deployment: Harness the full potential of Llama 2 on your own devices using tools like Llama.cpp, Ollama, and MLC LLM, ensuring privacy and offline access.
LM Studio: This user-friendly platform simplifies running Llama 2 and other LLMs locally on Mac and Windows, making advanced AI more accessible than ever.
Anakin AI: For those keen on exploring Llama models without the commitment of local installation, Anakin AI offers a convenient online platform for testing and experimentation.
What are Llama 2 Models?
Llama 2 models, developed and released by Meta AI, represent a significant advancement in the realm of Large Language Models (LLMs). These models range in size from 7 billion to 70 billion parameters, offering a spectrum of capabilities tailored to both general and specific applications. Llama 2 is designed as an auto-regressive language model optimized for generating human-like text responses, making it an essential tool for a wide array of natural language processing tasks.
Technical Specifications and Capabilities
Variations: Llama 2 is available in several versions, including both pretrained and fine-tuned variations, catering to different needs and use cases.
Architecture: The core of Llama 2 is based on an optimized transformer architecture, utilizing techniques like supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align the model's outputs with human preferences for helpfulness and safety.
Training Data: The models are trained on a diverse dataset comprising 2 trillion tokens from publicly available online sources, ensuring a broad understanding of various subjects and contexts.
Specialized Models within Llama 2
Llama Chat: A fine-tuned version of Llama 2, Llama Chat is optimized for conversational use cases, having been trained on over 1 million human-annotated examples to enhance its dialogue capabilities.
Code Llama: Tailored for code generation, Code Llama is built upon the Llama 2 architecture and trained on 500 billion tokens of code, supporting common programming languages like Python, C++, Java, and more.
Significance in AI Development
Llama 2 models stand out in the AI landscape for their open-source nature, high performance across various benchmarks, and their adaptability to both commercial and research purposes. Their ability to understand and generate contextually relevant text, combined with the ethical considerations in their development, positions Llama 2 as a pivotal development in AI, pushing forward the capabilities and applications of language models in technology.
For more detailed insights into Llama 2 models and their applications, you can explore the resources provided by Meta AI on their official website.
Based on a quick search, here's what I discovered.
1. How to Run Llama 2 with Anakin AI
One of the easiest way of intergrating Llama 2 Models into your workflow, is using Anakin AI.
Want to build AI Apps powered by any AI model? No worries, simply create a new chatbot, or workflow, and select your desired AI model as the option. Say, you want to try out the Llama 13B, Llama 70B models right now, simply use Anakin AI and build your app with one click:
Llama.cpp is a library developed by Georgi Gerganov, designed to run Large Language Models (LLMs) efficiently on CPUs, especially beneficial for those without access to GPUs. It offers high-speed inference for a variety of LLMs and can be integrated with Python through the llama-cpp-python package, allowing users to leverage Python's extensive libraries in their projects.
Setting Up Llama.cpp
Installation: The first step is to install the llama-cpp-python package, which provides Python bindings for the llama.cpp library, making it easier to use in Python environments. You can install it using pip:
Downloading and Loading the LLM: You need to download the model in GGML format from a source like Hugging Face. Ensure the model has been quantized to reduce memory requirements without significantly impacting performance. Here's an example code snippet for downloading and loading a model:
import os
import urllib.request
from llama_cpp import Llama
def download_file(file_link, filename):
if not os.path.isfile(filename):
urllib.request.urlretrieve(file_link, filename)
print("File downloaded successfully.")
else:
print("File already exists.")
ggml_model_path = "MODEL_LINK_HERE"
filename = "MODEL_FILENAME_HERE"
download_file(ggml_model_path, filename)
llm = Llama(model_path=filename, n_ctx=512, n_batch=126)
Replace "MODEL_LINK_HERE" and "MODEL_FILENAME_HERE" with the actual link and filename of your GGML model.
Generating Text: Once the model is loaded, you can generate text by passing a prompt to the model. Here’s a simple function to generate text:
This function allows customization of the generation process, including setting the maximum number of tokens, temperature for randomness, and stopping conditions.
3. How to Run Llama 2 Locally on Mac with Ollama
Ollama stands out for its simplicity, cost-effectiveness, privacy, and versatility, making it an attractive alternative to cloud-based LLM solutions. It eliminates latency and data transfer issues associated with cloud models and allows for extensive customization.
Pull Ollama Docker Image: With Docker set up, pull the Ollama image by running the following command in your terminal:
docker pull ollama/ollama
Run Ollama: To start Ollama, execute:
docker run -it ollama/ollama
This command launches Ollama, and you can begin interacting with the models.
Interacting with Models in Ollama
Listing Models: Use ollama list to view available models.
Running a Model: To interact with a specific model, use ollama run <model_name>.
Stopping a Model: If you need to stop the model, ollama stop <model_name> will do the trick.
Ollama on Different Platforms
Ollama's cross-platform support extends beyond Linux, catering to Windows and macOS users as well, thus broadening its appeal.
Setting Up Ollama on Windows
Download the Windows Executable: Visit Ollama's GitHub repository to download the latest executable for Windows.
Install Ollama: Run the downloaded executable and follow the prompts to complete the installation.
Run Ollama: Open Command Prompt, navigate to the Ollama installation directory, and initiate Ollama with ollama.exe run.
Leveraging GPU with Ollama
For tasks demanding extensive computation, Ollama harnesses GPU acceleration to enhance performance, supporting both NVIDIA and AMD GPUs. Ensure you have the right drivers installed for your GPU, and activate GPU support by adding a --gpu flag to your command:
ollama run --gpu <model_name>
This command enables GPU acceleration, significantly boosting model inference speeds.
Ollama and Python Integration
Ollama's compatibility with Python amplifies its utility in data science and machine learning projects. After installing the Ollama Python package (pip install ollama), you can easily incorporate Ollama models into your Python scripts, enabling direct interactions and inferences within your codebase.
Incorporating the provided instructions for running Llama 2 on Windows into your article, here is how you could structure and detail this section:
4. How to Run Llama 2 on Windows (Using Llama.cpp)
How to Run Llama 2 on Windows
For those in the Windows ecosystem, setting up Llama 2 locally involves a few preparatory steps but results in a powerful AI tool right at your fingertips. Here's a detailed guide to get you started:
Pre-installation Requirements
Nvidia GPU Users: If you have an Nvidia GPU, your first step should be to install the CUDA toolkit to leverage GPU acceleration, enhancing Llama 2's performance. The toolkit can be downloaded from the official Nvidia website at CUDA Toolkit Download.
Model Download: Next, you'll need the Llama 2 model itself. The model can be downloaded from Hugging Face at the following link: Llama 2-13B Model Download. Ensure you save the model in a location that's easily accessible for later steps.
Instal Llama 2 on Windows (Step-by-Step Guide)
Open your Windows Terminal and use PowerShell for the following commands:
Clone the Llama.cpp repository:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
Prepare the build environment:
mkdir build
cd build
Generate the build files with CMake, enabling CUDA if you have an Nvidia GPU:
This function allows you to run Llama 2 prompts more conveniently by typing llama "your prompt here" in the PowerShell terminal.
By following these steps, Windows users can enjoy the capabilities of Llama 2 locally, leveraging the power of AI for a variety of tasks without the need for an internet connection. This setup not only democratizes access to advanced AI models but also provides a personal, customizable AI experience.
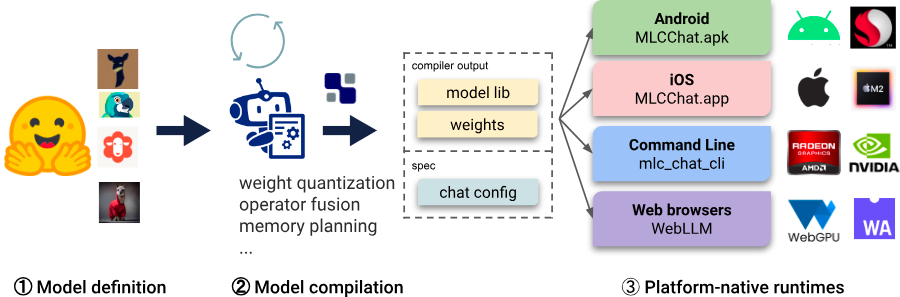
5. Running Llama 2 Locally with MLC LLM
MLC LLM: Running Llama 2 Locally
MLC LLM offers a streamlined approach for serving Llama 2 models locally, leveraging pre-compiled binaries for efficient inference. Here's a simplified step-by-step guide:
Choose Your GPU: Decide on the GPU type you'll be using, for example, "a10g" for NVIDIA's A10G GPUs.
Select Llama Model Size: Determine the size of the Llama model you wish to use, such as "7b" or "13b" for 7 billion or 13 billion parameters, respectively.
Set Up Environment: Use an NVIDIA CUDA image compatible with MLC's CUDA requirements, for instance, "nvidia/cuda:12.2.2-cudnn8-runtime-ubuntu22.04".
Install Dependencies: Install necessary packages and libraries, including git, curl, and Python packages like mlc-ai-nightly-cu122 and mlc-chat-nightly-cu122.
Download Model and Libraries: Clone the required libraries and the specific Llama model you've chosen from GitHub or another source.
Implement Inference Function: Use the ChatModule from mlc_chat to load the model and libraries, and create a function to handle input prompts and generate responses.
Run the Model: Execute your setup to start interacting with Llama 2 locally on your chosen GPU.
LM Studio simplifies running various LLMs, including Llama 2, on your local machine. Unfortunately, I couldn't find specific steps for LM Studio in the immediate search results. Generally, using LM Studio would involve:
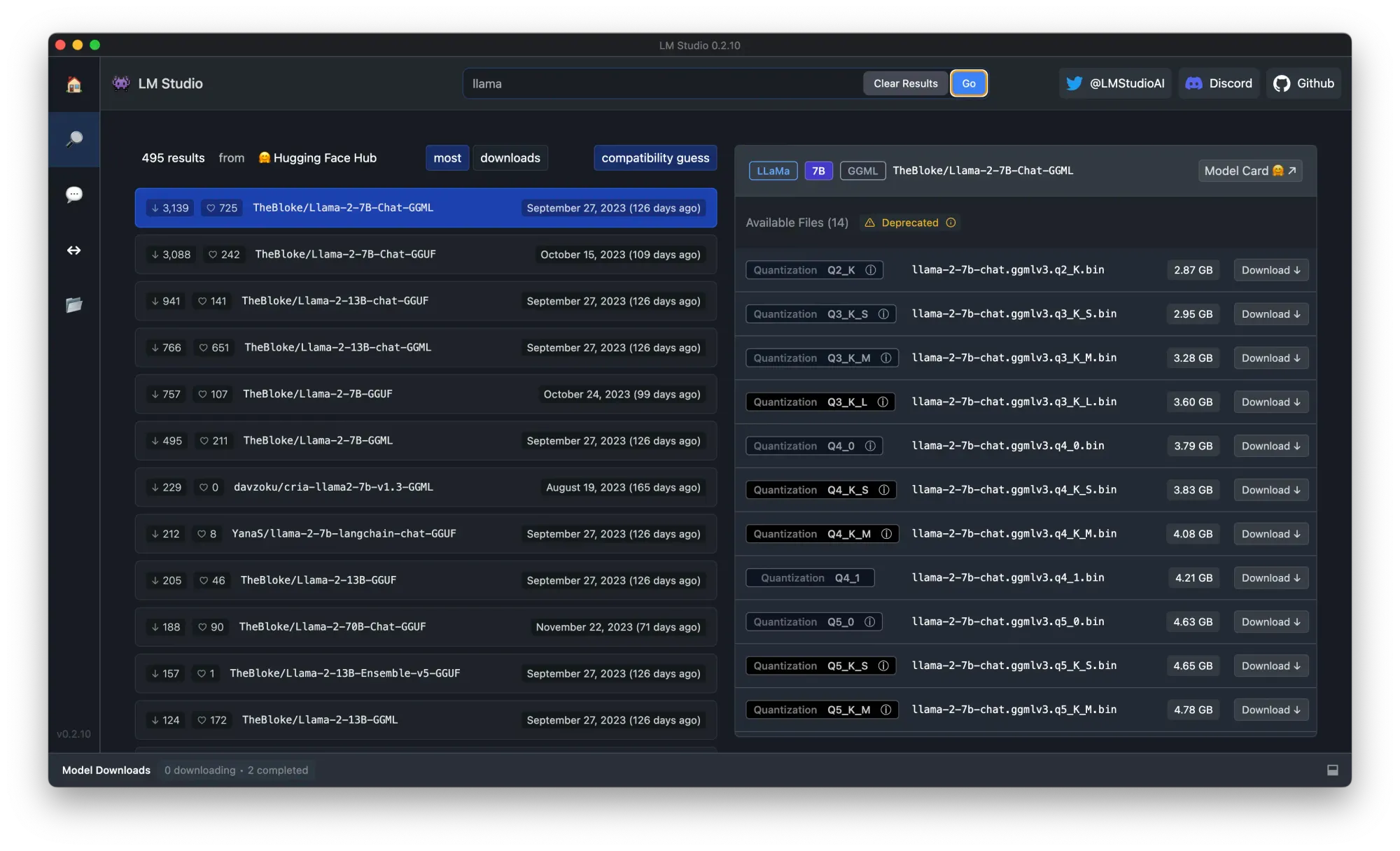
Step 2. Search "llama" in the search bar, choose a quantized version, and click on the Download button. In this case, I choose to download "The Block, llama 2 chat 7B Q4_K_M gguf".
Running Llama 2 Locally with LM Studio
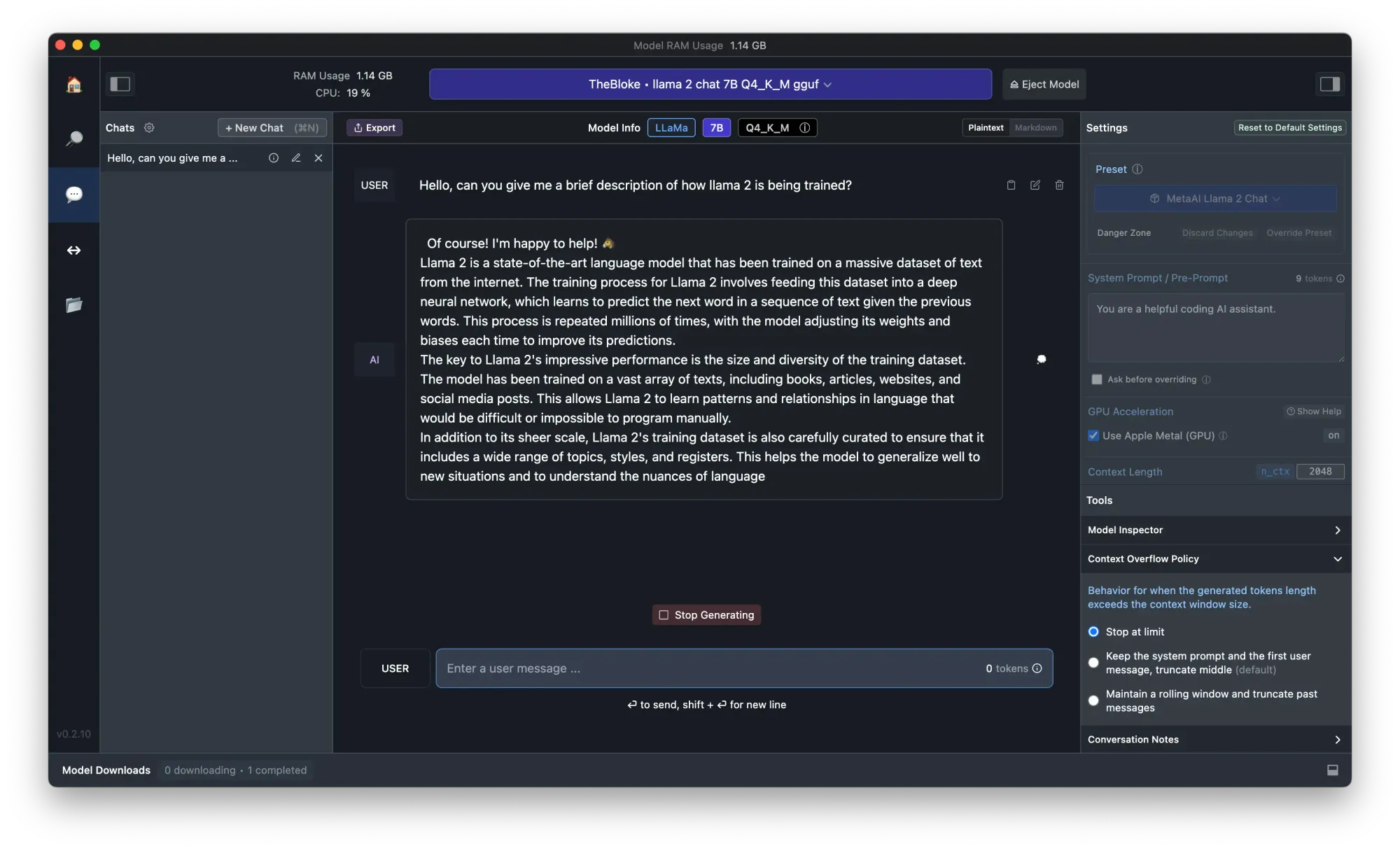
Step 3. After the downloading process is completed, click on the "Chat" button on the left panel, and load the downloaded model
Step 4. Now you can chat with Llama 2 Now! Don't forget to turn on the "Use Apple Metal (GPU) Option on the right-side panel for faster experience.
Conclusion
The Llama 2 models represent a pivotal advancement in AI, offering sophisticated language processing capabilities. Running these models locally, using tools like Llama.cpp, OLLAMA, MLC LLM, and LM Studio, provides flexibility, enhances privacy, and can be more cost-effective than cloud-based solutions. Each method varies in technical complexity and system requirements, catering to different user needs. I encourage readers to explore both local and online options for engaging with Llama 2 and other LLMs. Your choice should align with your technical expertise, resource availability, and specific requirements. This exploration into local deployment of LLMs opens doors to innovative applications and a deeper understanding of AI's potential.