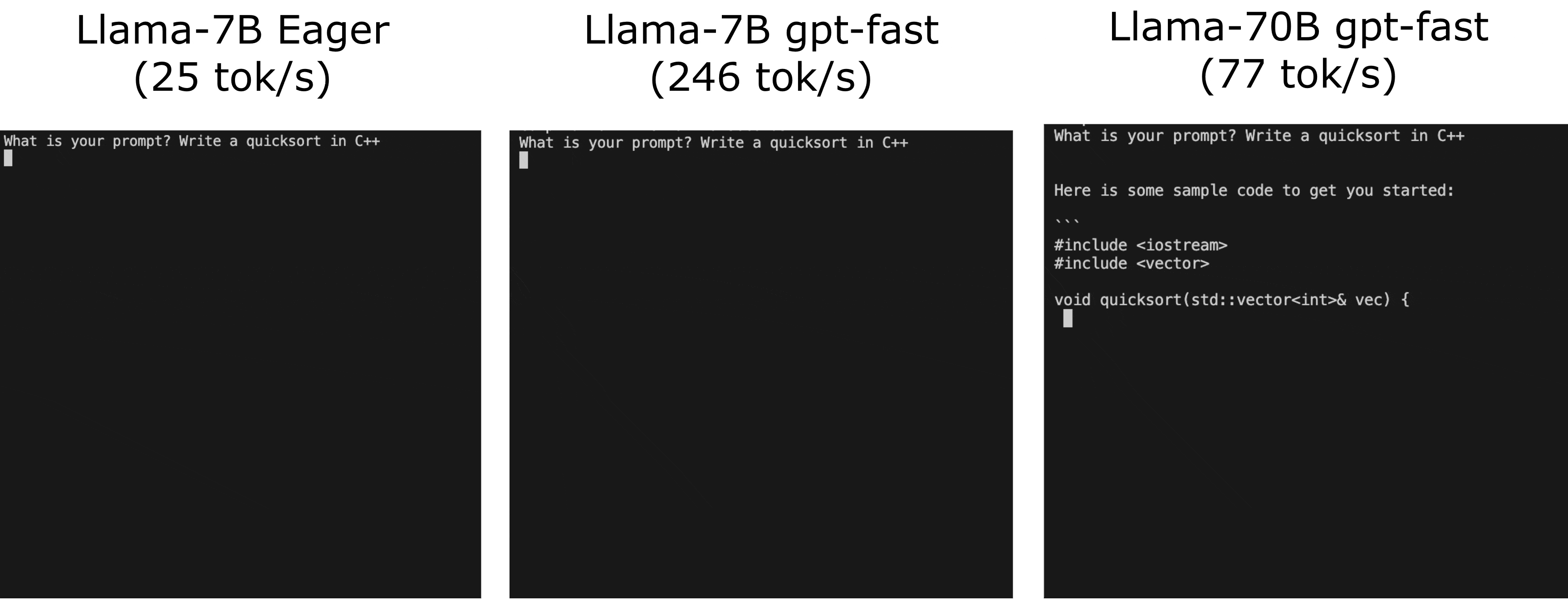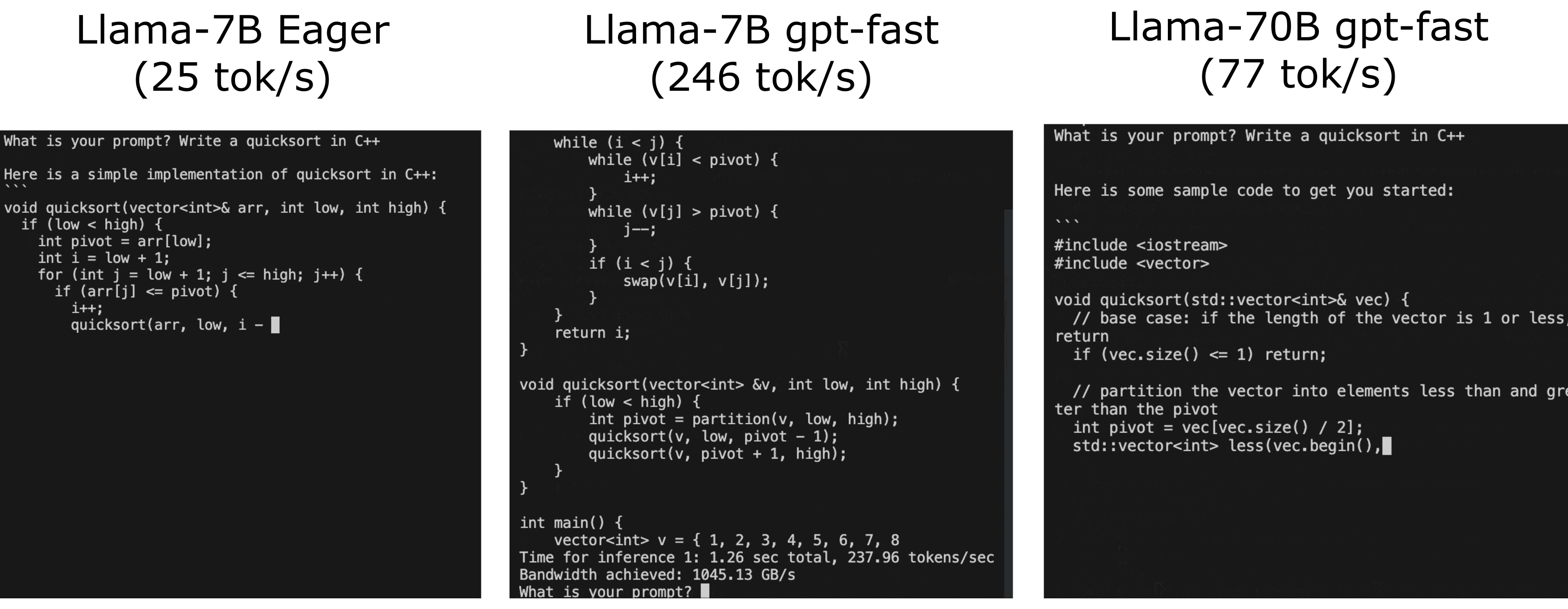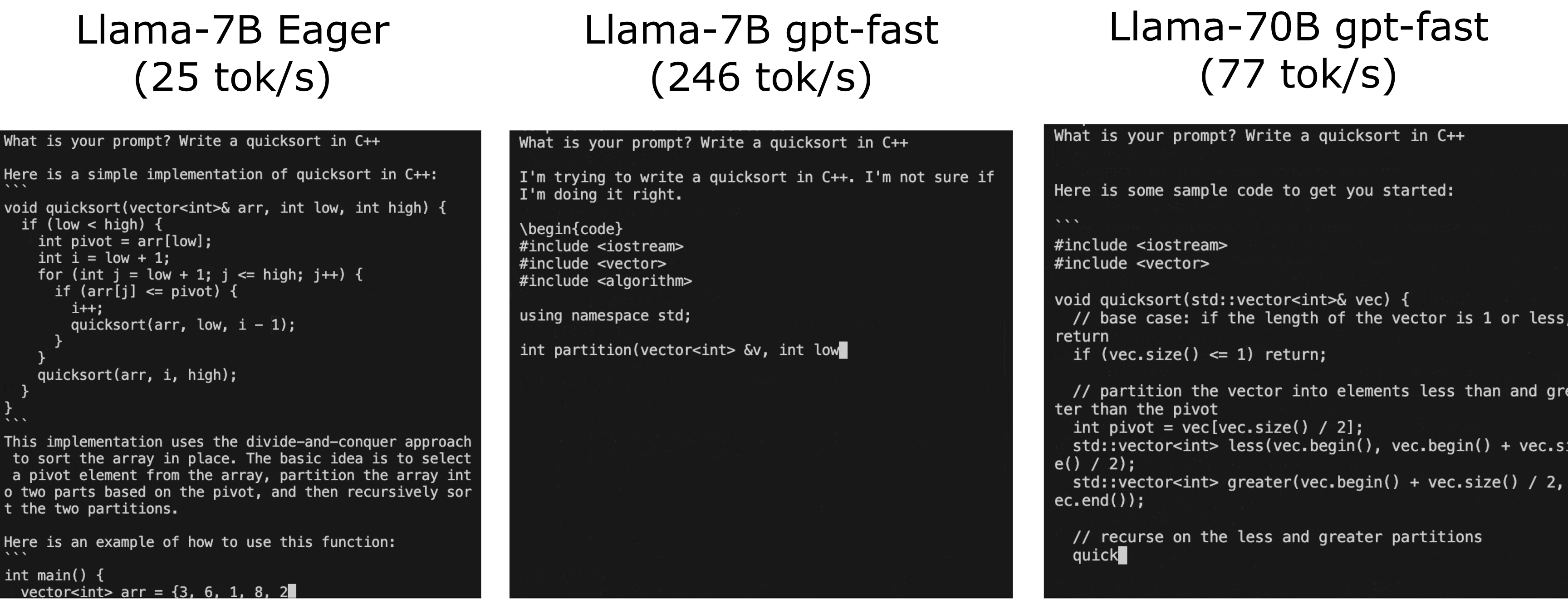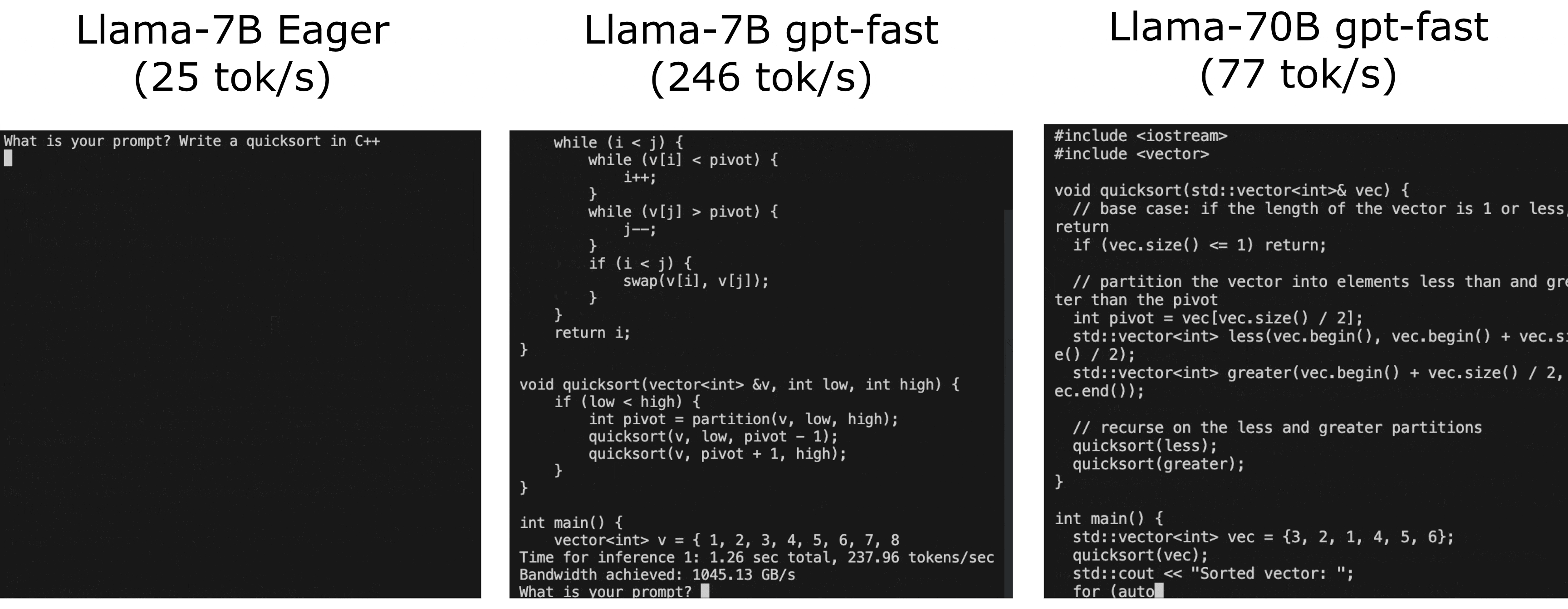
You might have heard about GPT-Fast, especially if you follow the latest AI trends. GPT-Fast is like a turbocharger for AI models, making them faster and more efficient, and give LLMs a serious performance boost.
Think of it as putting a powerful engine in a classic car – the same great model, but now it runs way faster! Take a look at the real-life performance boost of GPT-Fast in the following GIF:
So, how does GPT-Fast work? What is GPT-Fast?
What is GPT-Fast?
GPT-Fast is a state-of-the-art tool specifically designed for enhancing the performance of large language models. It stands as a testament to the innovative strides in AI, primarily focusing on speed and efficiency without compromising on the model's core capabilities. GPT-Fast is engineered to optimize AI processing, harnessing the power of advanced computing to deliver faster, more efficient results.
The objectives of GPT-Fast are twofold:
Performance Enhancement: GPT-Fast elevates the operational speed of AI models. It's engineered to handle extensive data sets and complex computations swiftly, effectively cutting down processing times and enhancing overall efficiency.
Efficiency Optimization: Beyond speed, GPT-Fast prioritizes efficient resource utilization. It achieves remarkable results without the need for extensive computational power, thus ensuring a balanced approach between performance and resource consumption.
How to Install GPT-Fast
To run GPT-Fast effectively, follow these steps:
Step 1. Installation:
Download PyTorch nightly. Install sentencepiece and huggingface_hub:
pip install sentencepiece huggingface_hub
To use specific models like Llama-2-7b, visit Hugging Face for access, then login with huggingface-cli login.
Step 2. Downloading Weights:
Supported models include openlm-research/open_llama_7b, meta-llama/Llama-2-7b-chat-hf, etc.
python generate.py --compile --checkpoint_path checkpoints/$MODEL_REPO/model.pth --prompt "Hello, my name is"
For additional performance, compile the prefill with --compile_prefill (note this may increase compilation times).
💡
Liking the latest AI News? Want to boost your productivity with a No-Code AI Tool?
Anakin AI can help you easily create any AI app with highly customized workflow, with access to Many, Many AI models such as GPT-4-Turbo, Claude-2-100k, API for Midjourney & Stable Diffusion, and much more!
Interested? Check out Anakin AI and test it out for free!👇👇👇
Benchmarks for GPT-Fast, running on an A100-80GB GPU, are summarized in the following table:
Model
Technique
Tokens/Second
Memory Bandwidth (GB/s)
Llama-2-7B
Base
104.9
1397.31
8-bit
155.58
1069.20
4-bit (G=32)
196.80
862.69
Llama-2-70B
Base
OOM
-
8-bit
19.13
1322.58
4-bit (G=32)
25.25
1097.66
How to Evaluate GPT-Fast
You can evaluate GPT-Fast easily with these steps: Install the EleutherAI evaluation harness as per instructions here. Evaluate the model accuracy using:
By following these steps and understanding the quantization techniques, users can effectively run and evaluate GPT-Fast, harnessing its advanced capabilities for efficient and powerful AI model optimization.
Why Is GPT-Fast So Fast? Let' Review GPT-Fast's Technical Details
When you first dive into using GPT-Fast, it's essential to recognize the starting point of its performance and the challenges you might face. Initially, GPT-Fast's basic implementation may yield a performance rate of about 25.5 tokens per second (TOK/S). While this might sound decent, it's actually not the full potential of the tool. The primary hurdle here is what's known as CPU overhead.
What is CPU Overhead for GPT-Fast?
CPU overhead in GPT-Fast refers to the lag or delay in communication between the CPU (Central Processing Unit) and the GPU (Graphics Processing Unit).
The CPU is responsible for sending instructions to the GPU. In an ideal scenario, this process should be quick and seamless. However, in the basic implementation of GPT-Fast, there's a significant delay.
This delay means the GPU, which is capable of handling massive computations, isn’t being fully utilized. It's like having a powerful sports car but only driving it in first gear.
Why Does This Matter?
The CPU overhead is a critical factor because it limits how fast and efficiently GPT-Fast can process data.
Understanding this limitation is the first step in optimizing GPT-Fast’s performance. Knowing that the issue lies in CPU-GPU communication allows you to focus on solutions that directly address this bottleneck.
How to Make GPT-Fast Faster with torch.compile
After understanding the initial performance limitations due to CPU overhead, the next step in effectively utilizing GPT-Fast involves leveraging torch.compile for significant performance improvements.
Utilizing torch.compile for Performance Boost
Reducing CPU Overhead: By employing torch.compile, especially in "reduce-overhead" mode, you can drastically cut down the CPU overhead. This optimization allows for capturing larger operational regions into a single compiled segment.
Performance Enhancement: This strategic implementation bumps up the performance significantly, from the initial 25.5 TOK/S to an impressive 107.0 TOK/S.
Overcoming Optimization Challenges
Handling KV-cache Dynamics: A primary challenge encountered is the dynamic nature of the KV-cache, which tends to expand with increasing token generations. GPT-Fast addresses this by adopting a static KV-cache allocation, thus stabilizing the cache size.
Prefill Phase Optimization: During transformer text generation, the prefill phase – where the entire prompt is processed – presents variability in prompt lengths. This requires diverse compilation strategies, which GPT-Fast adeptly handles, ensuring efficient processing.
Leveraging Int8 Quantization
To further alleviate the performance bottlenecks, particularly those associated with memory bandwidth, GPT-Fast incorporates int8 weight-only quantization.
Boosting to 157.4 TOK/S: This quantization technique reduces the size of the data that needs to be loaded into memory, thereby enhancing the processing speed to an impressive 157.4 TOK/S.
Speculative Decoding in GPT-Fast
Moving forward, GPT-Fast implements speculative decoding, a key technique that greatly accelerates the token generation process.
The Challenge of Repetitive Loading
A notable issue in earlier stages of GPT-Fast is the repetitive and time-consuming process of loading weights for each token generation. This repetitive loading significantly slows down the overall operation.
Introducing Speculative Decoding
Parallel Processing of Outcomes: Speculative decoding is an innovative solution that allows GPT-Fast to process multiple potential outcomes in parallel. Instead of a linear, one-by-one token generation, this technique speculates multiple possible tokens at once.
Speeding Up Generation: By doing so, speculative decoding dramatically speeds up the generation process. It essentially reduces the time spent waiting for each token to be processed, leading to a quicker and more efficient generation of text.
How Speculative Decoding Works in GPT-Fast
GPT-Fast uses speculative decoding to predict several possible next tokens based on the current state.
These predicted tokens are then processed simultaneously, and the most likely outcome is chosen, thus saving time that would otherwise be spent in sequential processing.
And eventually, this is the final optimized performance for GPT-Fast:
In conclusion, GPT-Fast is not just a breakthrough; it's a revolution in AI performance. With its advanced quantization techniques, speculative decoding, and tensor parallelism, GPT-Fast has done something phenomonal.
GPT-Fast isn't just another tool; it's a playground for AI enthusiasts and professionals to experiment, adapt, and evolve. So, dive into GPT-Fast, explore its capabilities, and perhaps even contribute to its ongoing evolution. The future of AI is exciting, and GPT-Fast is at the forefront, leading the charge!
💡
Liking the latest AI News? Want to boost your productivity with a No-Code AI Tool?
Anakin AI can help you easily create any AI app with highly customized workflow, with access to Many, Many AI models such as GPT-4-Turbo, Claude-2-100k, API for Midjourney & Stable Diffusion, and much more!
Interested? Check out Anakin AI and test it out for free!👇👇👇