Llama 3.2 API Preise: Alles, was Sie wissen müssen!
Mit dem rasanten Anstieg der KI ist die Notwendigkeit für leistungsstarke, skalierbare Modelle für Unternehmen jeder Größe essenziell geworden. Die Llama 3.2 API von Meta bietet eines der effizientesten und anpassungsfähigsten Sprachmodelle auf dem Markt, das sowohl textbasierte als auch multimodale Funktionen (Text und Bild) bietet. Egal, ob Sie
Mit dem rasanten Anstieg der KI ist die Notwendigkeit für leistungsstarke, skalierbare Modelle für Unternehmen jeder Größe essenziell geworden. Die Llama 3.2 API von Meta bietet eines der effizientesten und anpassungsfähigsten Sprachmodelle auf dem Markt, das sowohl textbasierte als auch multimodale Funktionen (Text und Bild) bietet. Egal, ob Sie konversationelle Agenten, Datenverarbeitungssysteme oder multimodale Anwendungen entwickeln, die Llama 3.2 API bietet erstklassige Leistung. Das Verständnis der Preisstruktur ist jedoch entscheidend, um den Wert für Ihren spezifischen Anwendungsfall zu maximieren.
In diesem Artikel werden wir das Llama 3.2 API Preis Modell aufschlüsseln, regionale Beispiele bereitstellen und Einblicke in den Tokenverbrauch für spezifische Eingaben und Ausgaben bieten.
Besonderer Hinweis: Llama 3.2 auf Anakin.ai: Entfalten Sie das KI-Potenzial mit flexibler Zugangsmöglichkeit
Die Llama 3.2 API Preisgestaltung basiert auf der Token-Nutzung. Tokens sind Teile von Wörtern, typischerweise zwischen 1 und 4 Zeichen in Englisch. Die Preisgestaltung wird in Eingabetoken und Ausgabetoken unterteilt, wobei je nach Modellgröße und Region, in der Sie tätig sind, unterschiedliche Tarife gelten.
Eingabetoken sind die Tokens, die Sie in einer Anfrage an das Modell senden.
Ausgabetoken sind die vom Modell als Antwort auf Ihre Anfrage generierten Tokens.
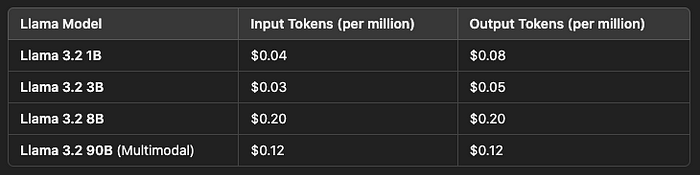
Meta und seine Partner bieten Preise in Form von USD pro Million Tokens an. Die Preisstruktur unterscheidet sich je nach Llama-Modellen, basierend auf deren Größen und Funktionen.
Hier ist die Preisaufschlüsselung für einige der Modelle:
Für Unternehmen, die Llama 3.2 in ihre Anwendungen integrieren möchten, macht dieses flexible Preismodell es skalierbar für die Anwendungen im kleinen Maßstab und im Unternehmensmaßstab.
Regionale Preisvariationen
API-Preise können je nach Region variieren, hauptsächlich aufgrund von Infrastrukturkosten, Rechenzentren und Betriebskosten. Anbieter wie Together AI und Amazon Bedrock bieten die Llama 3.2 API mit regionsspezifischen Preisen an.
Hier sind einige Beispiele für regionale Preise:
Together AI Preise:
Llama 3.2 Turbo (3B):
Eingabe- und Ausgabetokens: 0,06 $ pro Million Tokens
Llama 3.2 Referenz (8B):
Eingabe- und Ausgabetokens: 0,20 $ pro Million Tokens
Region: Nordamerika, Europa, Asien-Pazifik
Amazon Bedrock Preise:
Llama 3.2 API Modelle sind in mehreren AWS-Regionen verfügbar. Die Preise können je nach Region schwanken, und die Inferenz über Regionen kann möglicherweise Latenz und Kosten beeinflussen.
AWS US East: Es gelten Standardpreise.
AWS EU West: Die Preise können aufgrund höherer Infrastrukturkosten zusätzliche Gebühren beinhalten.
Obwohl die Tokenpreise für Llama-Modelle im Allgemeinen innerhalb eines ähnlichen Rahmens bleiben, können die regionalen Kosten aufgrund von Infrastrukturinvestitionen und anderen Faktoren wie Datenaufenthaltsanforderungen variieren.
Anbieterspezifische Funktionen
Verschiedene Cloud-Anbieter und API-Plattformen bieten Llama 3.2 mit einzigartigen Funktionen an, die über die grundlegende Token-Preisgestaltung hinausgehen. Diese zusätzlichen Dienste können Ihre Kosten beeinflussen, bieten jedoch auch wertvolle Vorteile wie Skalierbarkeit und geringere Latenz.
Together AI:
Skalierbarkeit: Together AI unterstützt bis zu 9.000 Anfragen pro Minute und 5 Millionen Tokens pro Minute für große Sprachmodelle.
Flexible Nutzung: Es gibt keine täglichen Ratebeschränkungen, was es ideal für Anwendungen mit hohem Durchsatz macht, wie Chatbots oder KI-gestützten Kundenservice.
Amazon Bedrock:
Cross-Region Inferenz: Bedrock ermöglicht Entwicklern, Llama-Modelle über verschiedene AWS-Regionen hinweg auszuführen, was globale Skalierbarkeit ermöglicht.
Unternehmensintegration: Llama-Modelle auf AWS können leicht in bestehende cloudbasierte Anwendungen integriert werden, mit Werkzeugen für Feinabstimmung und maßgeschneiderte Bereitstellung.
Anbieter können auch zusätzliche Dienste wie erweiterte Sicherheit, benutzerdefinierte SLAs (Service Level Agreements) und dedizierte Endpunkte für Unternehmenskunden anbieten.
Beispiele für den Tokenverbrauch
Um besser zu verstehen, wie die Preisgestaltung der Llama 3.2 API funktioniert, betrachten wir einige Beispiele für den Tokenverbrauch. Dies kann helfen, zu veranschaulichen, wie viel Sie basierend auf der Verwendung von Eingabe-/Ausgabetoken in verschiedenen Anwendungen ausgeben können.
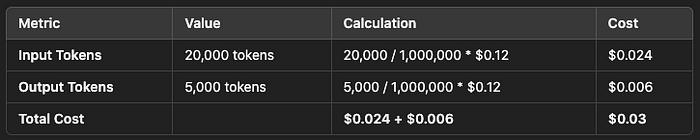
Beispiel 1: Textzusammenfassung
Länge des Eingabetexts: 1.500 Wörter (~6.000 Tokens)
Länge der Ausgabezusammenfassung: 250 Wörter (~1.000 Tokens)
Für eine Anwendung, die 10.000 Chargen pro Monat verarbeitet:
Gesamtkosten: 0,03 $ * 10.000 = 300 $
Unternehmens- und Großpreismodelle
Große Unternehmen oder Firmen, die eine langfristige, hochvolumige Nutzung anstreben, können benutzerdefinierte Preismodelle mit Meta oder Drittanbietern aushandeln. Diese Vereinbarungen bieten häufig ermäßigte Tarife, dedizierte Infrastruktur oder erweiterte Support-Pakete.
Zum Beispiel könnte ein Unternehmen, das täglich 10 Millionen Tokens verarbeitet, einen benutzerdefinierten Tarif aushandeln, um die Kosten zu senken, insbesondere bei der Verwendung großer Modelle wie dem Llama 3.2 Referenz (8B) Modell oder dem Llama 3.2 90B multimodalen Modell für Sichtaufgaben. Entdecken Sie hier mehr über die Unternehmenspreise für Llama-Modelle.
Kostenloses Kontingent und Credits
Viele Anbieter bieten kostenlose Kontingente oder erstattungsfähige Credits an, um Entwickler zu ermutigen, mit der Llama 3.2 API zu experimentieren. Zum Beispiel:
Together AI bietet einen kostenlosen Nutzungstarif an, der Entwicklern erlaubt, das Modell für eine begrenzte Anzahl von Tokens zu testen, bevor sie auf kostenpflichtige Dienste umsteigen.
AWS bietet neuen Benutzern Credits an, die auf die Ausführung von Llama 3.2 Modellen auf Amazon Bedrock angerechnet werden können.
Diese kostenlosen Kontingente sind eine großartige Möglichkeit für kleine Unternehmen oder Entwickler, die Leistung von Llama 3.2 zu testen, bevor sie sich für ein größeres Budget entscheiden. Erfahren Sie mehr über verfügbare kostenlose Kontingente.
Multimodale Fähigkeiten und Token-Preisgestaltung
Es ist wichtig zu beachten, dass multimodale Modelle (wie solche, die sowohl Text als auch Bild unterstützen) tendenziell etwas höhere Preise im Vergleich zu rein textbasierten Modellen haben. Dies liegt an der erhöhten rechnerischen Komplexität, die mit Bilderkennung und visuellen Denkaufgaben verbunden ist.
Zum Beispiel könnte das Llama 3.2 90B multimodale Modell kosten:
Eingabe- und Ausgabetokens: 0,12 $ pro Million Tokens (regionsspezifisch)
Diese Preisgestaltung ist im Vergleich zu anderen multimodalen Modellen wie den multimodalen Fähigkeiten von GPT-4, die oft teurer sind aufgrund von geschlossenen APIs und begrenzten Anpassungsoptionen, immer noch wettbewerbsfähig. Erfahren Sie mehr über die Preisunterschiede.
Fazit
Das Verständnis der Llama 3.2 API Preisgestaltung ermöglicht es Entwicklern, effektiv für KI-Projekte basierend auf der Token-Nutzung zu budgetieren. Egal, ob Sie kleine Anwendungen oder großangelegte multimodale Systeme betreiben, Llama 3.2 bietet flexible und wettbewerbsfähige Preise. Wichtige Überlegungen sind der Standort, an dem die API gehostet wird, die Tokenanforderungen Ihres spezifischen Anwendungsfalls und ob Sie textbasierte oder multimodale Verarbeitung benötigen.
Für kleine Anwendungen bieten die Llama 3.2 1B und 3B Modelle einen erschwinglichen Einstieg. Unternehmen hingegen könnten von benutzerdefinierten Preismodellen für größere Modelle wie 8B oder 90B profitieren.
Indem Unternehmen diese Faktoren berücksichtigen, können sie die Kosten optimieren und gleichzeitig die volle Macht von Llama 3.2 für verschiedene KI-gesteuerte Anwendungen nutzen. Erforschen Sie mehr über die Preisgestaltung der Llama API.
So verwenden Sie Llama 3.2 mit Anakin AI: Schritt-für-Schritt-Anleitung
Jetzt, da Sie wissen, was Llama 3.2 kann, lassen Sie uns untersuchen, wie und wo Sie es verwenden können. Befolgen Sie diese Schritte, um mit Llama 3.2 auf Anakin AI zu beginnen:
Schritt 1: Besuchen Sie Anakin AI
Gehen Sie zuerst zur Chat-Plattform von Anakin AI. Hier können Sie auf Meta's Llama 3.2 neben anderen führenden KI-Modellen zugreifen.
Schritt 2: Erstellen Sie ein Konto
Wenn Sie es noch nicht getan haben, müssen Sie sich registrieren für ein Konto. Der Registrierungsprozess ist schnell und erfordert lediglich eine E-Mail-Adresse und ein Passwort. Sobald Sie drin sind, haben Sie Zugriff auf alle KI-Modelle auf der Plattform.
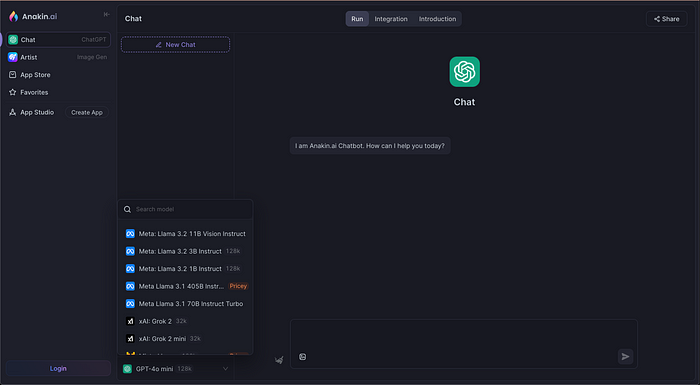
Schritt 3: Wählen Sie Ihr KI-Modell
Im Modell-Auswahlfeld sehen Sie eine Liste der verfügbaren Modelle wie ChatGPT, Gemini, Claude und natürlich Llama 3.2. Die Modelle kommen in verschiedenen Varianten, wie Llama 3.2 Vision Instruct oder Llama 3.2 Turbo Instruct, je nach Komplexität Ihres Projekts.