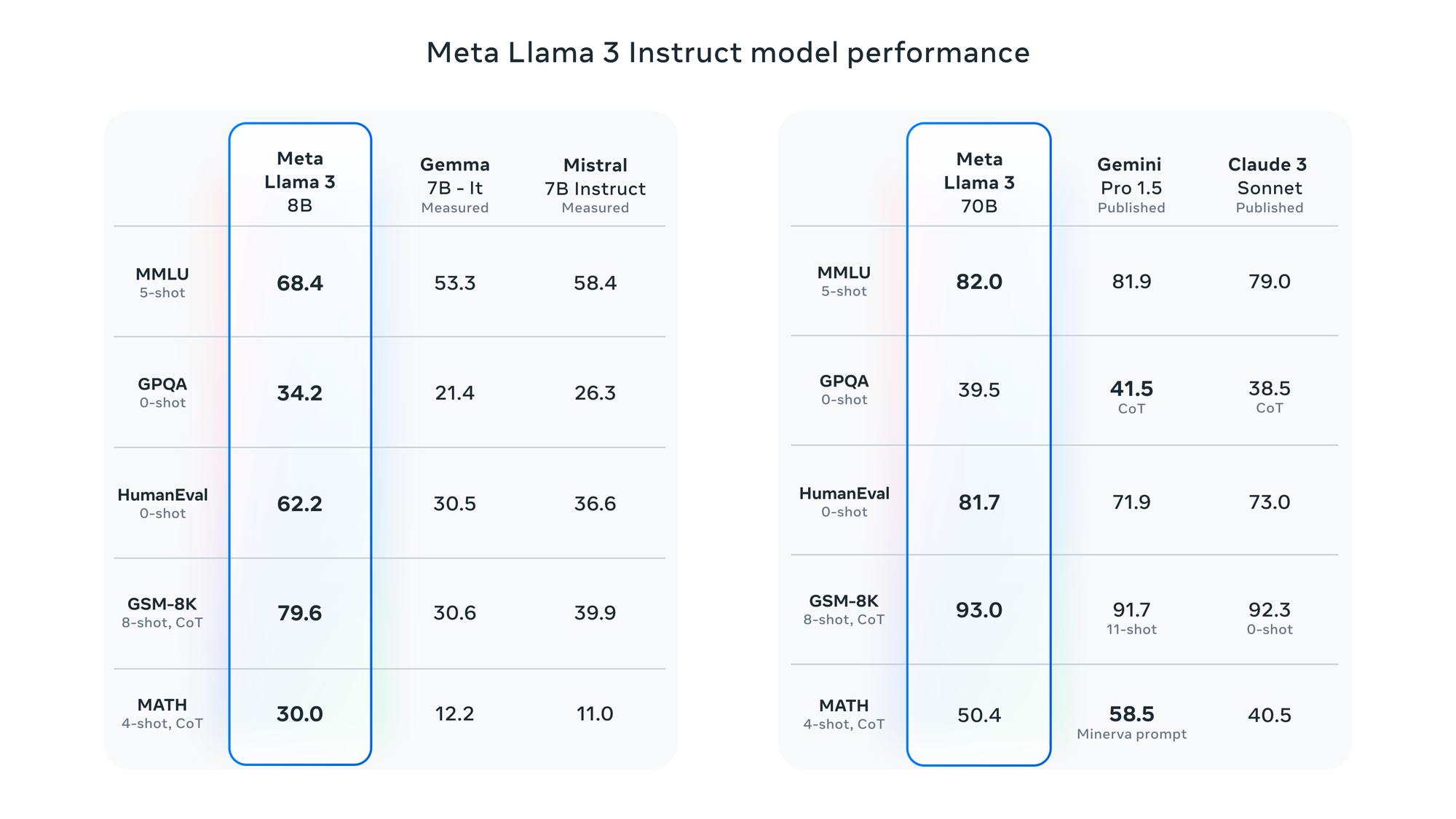
Llama 3 ist der neueste Durchbruch in großen Sprachmodellen, entwickelt von Meta AI. Zu den herausragenden Varianten gehören der 8 Milliarden Parameter Llama 3 8B und das massive 70 Milliarden Parameter Llama 3 70B. Diese Modelle haben aufgrund ihrer beeindruckenden Leistung in verschiedenen Aufgaben der natürlichen Sprachverarbeitung erhebliche Aufmerksamkeit erregt.
Llama 3 ist der neueste Durchbruch in großen Sprachmodellen, entwickelt von Meta AI. Zu den herausragenden Varianten gehören der 8 Milliarden Parameter Llama 3 8B und das massive 70 Milliarden Parameter Llama 3 70B. Diese Modelle haben aufgrund ihrer beeindruckenden Leistung in verschiedenen Aufgaben der natürlichen Sprachverarbeitung erhebliche Aufmerksamkeit erregt. Wenn Sie daran interessiert sind, ihre Leistung vor Ort zu nutzen, wird Sie dieser Leitfaden Schritt für Schritt durch den Prozess mit dem Tool ollama führen.
Was ist Llama 3?
Bevor wir uns in die technischen Details stürzen, wollen wir uns kurz die wichtigsten Unterschiede zwischen den Modellen Llama 3 8B und 70B ansehen.
Llama 3 8B
Das Llama 3 8B-Modell vereint Leistung und Ressourcenanforderungen. Mit 8 Milliarden Parametern bietet es beeindruckende Sprachverständnis- und Generierungsfähigkeiten und bleibt dabei relativ leichtgewichtig. Dadurch eignet es sich für Systeme mit bescheidener Hardware-Konfiguration.
Das Llama 3 70B-Modell hingegen ist ein wahres Ungetüm mit erstaunlichen 70 Milliarden Parametern. Diese erhöhte Komplexität führt zu einer verbesserten Leistung in einer Vielzahl von NLP-Aufgaben, einschließlich Code-Generierung, kreativem Schreiben und sogar multimodalen Anwendungen. Es erfordert jedoch auch deutlich mehr Rechenressourcen und erfordert daher einen robusten Hardware-Setup mit ausreichend Speicher und GPU-Leistung.
Interessiert an den neuesten Trends in der KI? Dann dürfen Sie Anakin AI nicht verpassen!
Mit Anakin AI können Sie mit All-in-One-Plattform für die Automatisierung Ihrer Workflows leistungsstarke KI-Apps erstellen. Erstellen Sie mit dem benutzerfreundlichen No-Code-App-Builder Claude, GPT-4, Uncensored LLMs, Stable Diffusion und vielem mehr.
Erstellen Sie Ihre Traum-KI-App innerhalb von Minuten, nicht Wochen, mit Anakin AI!
Um Ihnen eine fundierte Entscheidung zu ermöglichen, sind hier einige Leistungsbenchmarks, die die Modelle Llama 3 8B und 70B in verschiedenen NLP-Aufgaben vergleichen:
Aufgabe
Llama 3 8B
Llama 3 70B
Textgenerierung
4.5
4.9
Fragebeantwortung
4.2
4.8
Code-Vervollständigung
4.1
4.7
Sprachübersetzung
4.4
4.9
Zusammenfassung
4.3
4.8
Hinweis: Die Bewertungen basieren auf einer Skala von 1 bis 5, wobei 5 die höchste Leistung darstellt.
Wie Sie sehen können, übertrifft das Llama 3 70B-Modell in allen Aufgaben konsequent die 8B-Variante, allerdings mit höheren Rechenanforderungen. Das 8B-Modell liefert jedoch immer noch beeindruckende Ergebnisse und kann eine praktischere Wahl für diejenigen sein, die über begrenzte Hardware-Ressourcen verfügen.
Voraussetzungen für die lokale Ausführung von Llama 3
Um Llama 3-Modelle lokal auszuführen, muss Ihr System die folgenden Voraussetzungen erfüllen:
Hardware-Anforderungen
RAM: Mindestens 16 GB für Llama 3 8B, 64 GB oder mehr für Llama 3 70B.
GPU: Leistungsstarke GPU mit mindestens 8 GB VRAM, vorzugsweise eine NVIDIA-GPU mit CUDA-Unterstützung.
Festplattenspeicher: Llama 3 8B benötigt rund 4 GB, während Llama 3 70B über 20 GB hinausgeht.
Software-Anforderungen
Docker: Ollama setzt zur Bereitstellung auf Docker-Container.
CUDA: Wenn Sie eine NVIDIA-GPU verwenden, muss die entsprechende CUDA-Version installiert und konfiguriert sein.
Verwendung von Ollama zur lokalen Ausführung von Llama 3
.@MistralAI's Mixtral 8x22B Instruct ist jetzt auf Ollama verfügbar!
ollama run mixtral:8x22b
Wir haben die Tags aktualisiert, um das Instruct-Modell standardmäßig widerzuspiegeln. Wenn Sie das Basismodell gezogen haben, aktualisieren Sie es bitte durch Ausführen des Befehls `ollama pull`. pic.twitter.com/WcWHLkVPIK
Ollama ist ein leistungsstarkes Tool, das den Prozess der lokalen Ausführung von Llama-Modellen vereinfacht. Befolgen Sie diese Schritte, um es zu installieren:
Öffnen Sie ein Terminal oder eine Befehlszeile.
Führen Sie den folgenden Befehl aus, um das ollama-Installationsskript herunterzuladen und auszuführen:
curl -fsSL https://ollama.com/install.sh | sh
Dieses Skript kümmert sich um den Installationsprozess, einschließlich des Herunterladens von Abhängigkeiten und der Einrichtung der erforderlichen Umgebung.
Herunterladen von Llama 3-Modellen
Wenn ollama installiert ist, können Sie die Llama 3-Modelle, die Sie lokal ausführen möchten, herunterladen. Verwenden Sie die folgenden Befehle:
Für Llama 3 8B:
ollama download llama3-8b
Für Llama 3 70B:
ollama download llama3-70b
Beachten Sie, dass das Herunterladen des 70B-Modells aufgrund seiner enormen Größe zeitaufwändig und ressourcenintensiv sein kann.
Ausführen von Llama 3-Modellen
Nach Abschluss des Modell-Downloads können Sie mit ollama die Llama 3-Modelle lokal ausführen.
Für Llama 3 8B:
ollama run llama3-8b
Für Llama 3 70B:
ollama run llama3-70b
Dadurch wird das jeweilige Modell in einem Docker-Container gestartet, sodass Sie über eine Befehlszeilenschnittstelle damit interagieren können. Sie können dann Eingabeaufforderungen oder Texteingaben bereitstellen und das Modell generiert entsprechende Antworten.
Erweiterte Verwendung von Llama 3-Modellen
Ollama bietet eine Reihe von erweiterten Optionen und Konfigurationen, um Ihr Erlebnis zu verbessern, darunter:
Feinabstimmung: Feinabstimmung der Llama-Modelle auf eigenen Daten, um ihr Verhalten und ihre Leistung für bestimmte Aufgaben oder Bereiche anzupassen.
Quantisierung: Reduzierung des Speicherbedarfs und Verbesserung der Inferenzgeschwindigkeit durch Quantisierung der Modelle.
Mehr-GPU-Unterstützung: Nutzung mehrerer GPUs zur Beschleunigung von Inferenz- und Feinabstimmungsprozessen.
Containerisierung: Export containerisierter Versionen Ihrer feinabgestimmten oder quantisierten Modelle, um sie einfach für verschiedene Systeme freizugeben und bereitzustellen.
Feinabstimmung von Llama 3-Modellen
Bei der Feinabstimmung handelt es sich um den Vorgang, bei dem ein vortrainiertes Sprachmodell wie Llama 3 an eine bestimmte Aufgabe oder Domäne angepasst wird, indem es mit einem relevanten Datensatz weiter trainiert wird. Dadurch kann die Leistung und Genauigkeit des Modells für den Zielanwendungsfall erheblich verbessert werden.
Der Feinabstimmungsprozess
Datensatz vorbereiten: Sammeln Sie einen qualitativ hochwertigen Datensatz, der für Ihre Zielaufgabe oder -domäne relevant ist. Der Datensatz sollte in der richtigen Form vorliegen, normalerweise als Sammlung von Eingabe-Ausgabe-Paaren oder Anfragen und erwarteten Antworten.
Vortrainiertes Modell laden: Laden Sie das vortrainierte Llama 3-Modell (8B oder 70B), das Sie feinabstimmen möchten.
Hyperparameter festlegen: Bestimmen Sie die geeigneten Hyperparameter für den Feinabstimmungsprozess, wie Lernrate, Batch-Größe und Anzahl der Epochen.
Feinabstimmung durchführen: Führen Sie den Feinabstimmungsprozess durch, bei dem die Parameter des Modells mit Ihrem Datensatz und den angegebenen Hyperparametern aktualisiert werden.
Auswerten: Bewerten Sie die Leistung des feinabgestimmten Modells anhand eines abgesonderten Testsatzes oder relevanter Benchmarks.
Bereitstellen: Stellen Sie das feinabgestimmte Modell für Ihre Zielanwendung oder Ihren Anwendungsfall bereit.
Feinabstimmung mit Ollama
Ollama bietet eine bequeme Möglichkeit, Llama 3-Modelle lokal feinabzustimmen. Hier ist ein Beispielbefehl:
Dieser Befehl führt eine Feinabstimmung des Llama 3 8B-Modells auf dem angegebenen Datensatz durch, verwendet eine Lernrate von 1e-5, eine Batch-Größe von 8 und führt für 5 Epochen aus. Sie können diese Hyperparameter je nach Ihren spezifischen Anforderungen anpassen.
Ersetzen Sie llama3-8b durch llama3-70b, um das größere 70B-Modell feinabzustimmen.
Verwendung von Llama 3 auf Azure
Obwohl Ollama Ihnen ermöglicht, Llama 3-Modelle lokal auszuführen, können Sie auch auf Cloud-Ressourcen wie Microsoft Azure zurückgreifen, um auf diese Modelle zuzugreifen und sie feinzustimmen.
Azure OpenAI Service
Microsoft Azure bietet den Azure OpenAI Service, der Zugriff auf verschiedene Sprachmodelle, einschließlich Llama 3, bietet. Dieser Dienst ermöglicht es Ihnen, Llama 3 in Ihre Anwendungen zu integrieren und seine Fähigkeiten zu nutzen, ohne dass lokal Hardware-Ressourcen erforderlich sind.
Um Llama 3 in Azure zu verwenden, müssen Sie:
Ein Azure-Konto erstellen: Registrieren Sie sich für ein Microsoft Azure-Konto, wenn Sie noch keines haben.
Den Azure OpenAI Service abonnieren: Navigieren Sie zum Azure OpenAI Service im Azure-Portal und abonnieren Sie den Dienst.
API-Keys erhalten: Generieren Sie API-Keys, um sich beim Azure OpenAI Service zu authentifizieren und auf die Llama 3-Modelle zuzugreifen.
Integration in Ihre Anwendung: Verwenden Sie die bereitgestellten SDKs und APIs, um Llama 3 in Ihre Anwendung zu integrieren und so seine Fähigkeiten zur natürlichen Sprachverarbeitung zu nutzen.
Azure Machine Learning
Alternativ können Sie Azure Machine Learning verwenden, um Llama 3-Modelle auf den skalierbaren Rechenressourcen von Azure feinzustimmen. Auf diese Weise können Sie die leistungsstarke Infrastruktur von Azure für das Training und die Feinabstimmung großer Sprachmodelle wie Llama 3 nutzen.
Richten Sie eine Azure Machine Learning-Arbeitsbereich ein: Erstellen Sie einen Azure Machine Learning-Arbeitsbereich im Azure-Portal.
Laden Sie den Datensatz hoch: Laden Sie Ihren Feinabstimmungsdatensatz in ein Azure-Speicherkonto oder in den Azure Machine Learning-Datenspeicher hoch.
Erstellen Sie einen Compute-Cluster: Richten Sie einen Compute-Cluster mit den erforderlichen GPU-Ressourcen für die Feinabstimmung von Llama 3 ein.
Feinabstimmung von Llama 3: Verwenden Sie die integrierten Tools oder benutzerdefinierten Codes von Azure Machine Learning, um das Llama 3-Modell mit Ihrem Datensatz zu feinabzustimmen und nutzen Sie den Compute-Cluster für das verteilte Training.
Bereitstellen des feinabgestimmten Modells: Sobald die Feinabstimmung abgeschlossen ist, stellen Sie das feinabgestimmte Llama 3-Modell als Webdienst bereit oder integrieren Sie es in Ihre Anwendung mit den Bereitstellungsmöglichkeiten von Azure Machine Learning.
Durch die Nutzung der Cloud-Ressourcen von Azure können Sie auf Llama 3-Modelle zugreifen und sie feinabstimmen, ohne dass lokale Hardware erforderlich ist. Dadurch können Sie von skalierbarer Rechenleistung und vereinfachten Bereitstellungsoptionen profitieren.
Fazit
Die lokale Ausführung großer Sprachmodelle wie Llama 3 8B und 70B ist dank Tools wie ollama zunehmend zugänglich geworden. Durch Befolgung der in diesem Leitfaden beschriebenen Schritte können Sie die Leistung dieser modernen Modelle auf Ihrer eigenen Hardware nutzen und so neue Möglichkeiten für Aufgaben der natürlichen Sprachverarbeitung, Forschung und Experimente eröffnen.
Ob Sie nun Entwickler, Forscher oder Enthusiast sind: Die Möglichkeit, Llama 3-Modelle lokal auszuführen, eröffnet neue Wege für Erkundung und Innovation. Mit der richtigen Hardware- und Softwarekonfiguration können Sie die Grenzen dessen, was mit Sprachmodellen möglich ist, erweitern und zum stetig wachsenden Bereich der künstlichen Intelligenz beitragen.
Obwohl das 70B-Modell eine unübertroffene Leistung bietet, bietet die 8B-Variante eine gute Balance zwischen Leistungsfähigkeit und Ressourcenanforderungen und ist daher eine hervorragende Wahl für diejenigen mit bescheidener Hardware-Konfiguration. Letztendlich hängt die Entscheidung zwischen den beiden Modellen von Ihren spezifischen Anforderungen, verfügbaren Ressourcen und den gewünschten Abwägungen ab.
💡
Interessiert an den neuesten Trends in der KI? Dann dürfen Sie Anakin AI nicht verpassen!
Mit Anakin AI können Sie mit All-in-One-Plattform für die Automatisierung Ihrer Workflows leistungsstarke KI-Apps erstellen. Erstellen Sie mit dem benutzerfreundlichen No-Code-App-Builder Claude, GPT-4, Uncensored LLMs, Stable Diffusion und vielem mehr.
Erstellen Sie Ihre Traum-KI-App innerhalb von Minuten, nicht Wochen, mit Anakin AI!