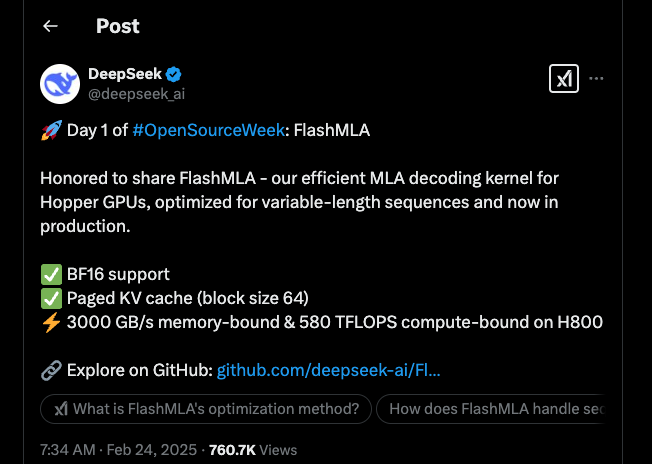
DeepSeek presenta FlashMLA: ¡Día 1 de OpenSourceWeek!
DeepSeek ha inaugurado su Semana de Código Abierto con un gran impacto, presentando FlashMLA, un núcleo de decodificación de MLA de vanguardia construido para las GPU Hopper de NVIDIA. Este anuncio ha puesto a la comunidad tecnológica en plena efervescencia, y la gente está ansiosa por sumergirse en lo que
DeepSeek ha inaugurado su Semana de Código Abierto con un gran impacto, presentando FlashMLA, un núcleo de decodificación de MLA de vanguardia construido para las GPU Hopper de NVIDIA. Este anuncio ha puesto a la comunidad tecnológica en plena efervescencia, y la gente está ansiosa por sumergirse en lo que esta actualización significa para el procesamiento de IA.
¿Buscas aprovechar el poder de la IA para la creación y edición de videos sin interrupciones? ¡Anakin AI es tu plataforma ideal! Con un conjunto integral de generadores de video de IA de vanguardia — incluyendo Runway ML, Minimax Video 01, Tencent Hunyuan Video, y más — puedes dar vida a tu visión creativa sin esfuerzo. Ya sea que estés transformando escenas, generando secuencias cinematográficas, o refinando ediciones con modelos avanzados de IA, Anakin AI tiene todo lo que necesitas.
FlashMLA es un núcleo especializado diseñado para acelerar el proceso de decodificación para la Atención Latente de Múltiples Cabezas (MLA). En términos simples, ayuda a los modelos de IA a manejar secuencias de longitud variable de manera más eficiente. Ya sea que te interese el procesamiento de lenguaje natural o otras tareas de IA, esta herramienta está lista para causar un gran impacto.
Características Clave y Rendimiento
Soporte para BF16
Una de las características más destacadas de FlashMLA es su soporte para precisión BF16 (Brain Float 16). Al usar BF16, el núcleo reduce el uso de memoria sin sacrificar la precisión que los modelos de IA a gran escala exigen. Los usuarios han elogiado sus virtudes, señalando que es un verdadero cambio de juego en el manejo de cálculos pesados.
Cache de Clave-Valor Paginada
Otro aspecto interesante es la cache de clave-valor paginada, que viene con un tamaño de bloque de 64. Esta configuración gestiona la memoria de manera eficiente y ayuda a mejorar el rendimiento de inferencia. Es como tener una caja de herramientas bien organizada donde cada herramienta está exactamente donde la necesitas.
Métricas Impresionantes
En términos de rendimiento, FlashMLA no decepciona. En la GPU H800 SXM5, alcanza la asombrosa cifra de 3000 GB/s en escenarios limitados por memoria y llega hasta 580 TFLOPS cuando la tarea está limitada por la computación. Estos números no son solo impresionantes — son un testimonio de la increíble ingeniería detrás del núcleo.
Cómo Destaca FlashMLA
FlashMLA se inspira en proyectos bien conocidos como FlashAttention y CUTLASS de NVIDIA. Ha sido construido con un enfoque en la eficiencia y la preparación para producción, asegurando que los desarrolladores puedan integrarlo sin problemas en sus flujos de trabajo. La gente en la comunidad ha sido rápida en señalar que esta es una herramienta indispensable para cualquiera que tome en serio superar los límites del rendimiento de IA.
Integración y Configuración
Para aquellos que desean comenzar, la instalación es tan fácil como un pastel. Con una GPU Hopper, CUDA 12.3 o superior y PyTorch 2.0 o más, puedes instalar FlashMLA usando un simple comando:python setup.py install
Una vez instalado, puedes ejecutar pruebas de rendimiento con:python tests/test_flash_mla.py
Este proceso sencillo ha sido un éxito entre los desarrolladores, muchos de los cuales ya están compartiendo testimonios entusiastas sobre cómo FlashMLA está transformando sus proyectos.
El Panorama General
El lanzamiento de FlashMLA por parte de DeepSeek marca el comienzo de una emocionante semana de innovación de código abierto. La empresa no se detiene aquí; está invitando a desarrolladores de todo el mundo a colaborar y construir sobre esta nueva tecnología. A medida que la IA continúa evolucionando, herramientas como FlashMLA juegan un papel crucial en hacer que la IA avanzada sea más accesible y eficiente.
Desarrolladores y entusiastas tecnológicos están observando de cerca este proyecto. Con FlashMLA, DeepSeek ha demostrado un claro compromiso con empujar los límites, y este anuncio es solo la punta del iceberg durante la Semana de Código Abierto.
Pensamientos Finales
La introducción de FlashMLA por parte de DeepSeek ha hecho que todos hablen. Con su sólido soporte para BF16, una innovadora cache de clave-valor paginada y métricas de rendimiento excepcionales, está claro que esta herramienta está destinada a redefinir la eficiencia en el procesamiento de IA. Si estás en el juego de la IA, ahora es el momento de explorar lo que FlashMLA puede hacer por ti. Mantente atento a más actualizaciones mientras DeepSeek continúa lanzando nuevas y emocionantes características a lo largo de la Semana de Código Abierto.