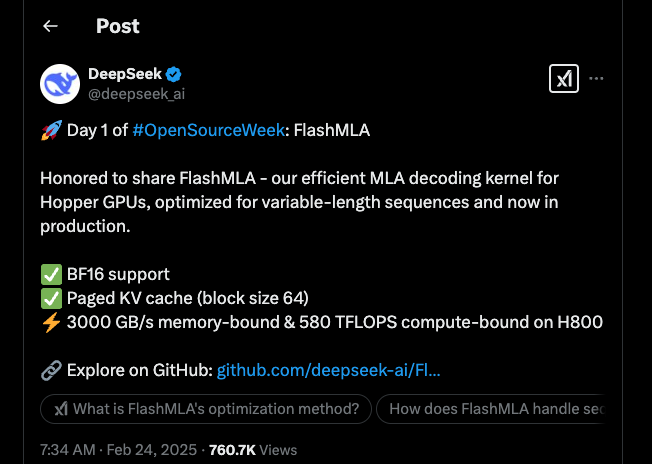
أطلقت DeepSeek أسبوع المصدر المفتوح لديها بشكل مثير، حيث كشفت عن FlashMLA — نواة فك تشفير MLA متطورة مصممة لوحدات معالجة الرسوميات من NVIDIA من نوع Hopper. لقد أثار هذا الإعلان حماس مجتمع التكنولوجيا، ويتحمس الناس لمعرفة ما تعنيه هذه التحديثات لمعالجة الذكاء الاصطناعي.
هل ترغب في استغلال قوة الذكاء الاصطناعي لإنشاء وتحرير الفيديو بسلاسة؟ Anakin AI هي منصتك المفضلة! مع مجموعة شاملة من مولدات الفيديو الذكية المتطورة — بما في ذلك Runway M، Minimax Video 01، Tencent Hunyuan Video، والمزيد — يمكنك بكل سهولة تحويل رؤيتك الإبداعية إلى حقيقة. سواء كنت تقوم بتحويل المشاهد، أو إنشاء تسلسلات سينمائية، أو تحسين التعديلات باستخدام نماذج الذكاء الاصطناعي المتقدمة، فـ Anakin AI لديه كل ما تحتاجه.
🚀 ابدأ في الإبداع اليوم! استكشف أدوات الفيديو بالذكاء الاصطناعي هنا: توليد فيديو Anakin AI


ما هو FlashMLA؟

FlashMLA هي نواة متخصصة مصممة لتسريع عملية فك التشفير لـ Multi-head Latent Attention (MLA). بعبارات بسيطة، فهي تساعد نماذج الذكاء الاصطناعي على التعامل مع التسلسلات ذات الطول المتغير بشكل أكثر كفاءة. سواء كنت مهتمًا بمعالجة اللغة الطبيعية أو مهام الذكاء الاصطناعي الأخرى، فإن هذه الأداة ستحدث تأثيرًا كبيرًا.
الميزات الرئيسية والأداء
دعم BF16
واحدة من الميزات البارزة لـ FlashMLA هي دعمها لدقة BF16 (Brain Float 16). باستخدام BF16، تقلل النواة من استخدام الذاكرة دون التضحية بالدقة التي تتطلبها نماذج الذكاء الاصطناعي واسعة النطاق. لقد أشاد المستخدمون بها، مشيرين إلى أنها تغير قواعد اللعبة بالفعل في التعامل مع الحسابات الثقيلة.
ذاكرة مؤقتة مفتاحية موجهة
جانب آخر رائع هو الذاكرة المؤقتة المفتاحية الموجهة، التي تأتي بحجم كتلة يبلغ 64. هذا الإعداد يدير الذاكرة بكفاءة ويساعد على تعزيز أداء الاستدلال. إنه مثل وجود صندوق أدوات منظم جيدًا حيث كل أداة بالضبط حيث تحتاج إليها.
مقاييس مثيرة للإعجاب
من الناحية الأداء، لا يخيب FlashMLA الآمال. على وحدة معالجة الرسوميات H800 SXM5، يسجل 3000 جيجابايت/ثانية في السيناريوهات التي تستند إلى الذاكرة ويدفع حتى 580 TFLOPS عندما تكون المهمة مستندة إلى الحساب. هذه الأرقام ليست مثيرة للإعجاب فحسب — بل هي شهادة على الهندسة الرائعة وراء النواة.
كيف يبرز FlashMLA
يستمد FlashMLA إلهامه من مشاريع معروفة مثل FlashAttention وCUTLASS من NVIDIA. تم بناءه مع التركيز على الكفاءة والاستعداد للإنتاج، مما يضمن أن المطورين يمكنهم دمجه بسلاسة في سير عملهم. لقد كان لدى أفراد المجتمع ملاحظات سريعة بأن هذه الأداة ضرورة لكل من يأمل في دفع حدود أداء الذكاء الاصطناعي.
الدمج والإعداد
لأولئك الذين يتطلعون إلى البدء، فإن التثبيت سهل للغاية. مع وحدة معالجة الرسوميات Hopper، CUDA 12.3 أو أعلى، وPyTorch 2.0 أو أعلى، يمكنك تثبيت FlashMLA باستخدام أمر بسيط: python setup.py install
بمجرد تثبيته، يمكنك تشغيل الاختبارات مع: python tests/test_flash_mla.py
كانت هذه العملية المباشرة ناجحة بين المطورين، العديد منهم يشاركون بالفعل شهادات صارخة حول كيفية إعادة تشكيل FlashMLA لمشاريعهم.
الصورة الأكبر
إن إطلاق DeepSeek لـ FlashMLA يمثل بداية أسبوع مثير من الابتكار في المصدر المفتوح. الشركة لا تتوقف هنا — بل تدعو المطورين من جميع أنحاء العالم للتعاون والبناء على هذه التكنولوجيا الجديدة. مع استمرار تطور الذكاء الاصطناعي، تلعب أدوات مثل FlashMLA دورًا حاسمًا في جعل الذكاء الاصطناعي المتقدم أكثر وصولًا وكفاءة.
يواصل المطورون وعشاق التقنية متابعة هذا المشروع عن كثب. مع FlashMLA، أظهرت DeepSeek التزامها الواضح بدفع الحدود، وهذا الإعلان ليس سوى قمة الجليد خلال أسبوع المصدر المفتوح.
الأفكار النهائية
لقد أثار تقديم DeepSeek لـ FlashMLA حديث الجميع. مع دعمها القوي لـ BF16، وذاكرة مؤقتة مفتاحية موجهة مبتكرة، ومقاييس أداء استثنائية، من الواضح أن هذه الأداة ستعيد تعريف الكفاءة في معالجة الذكاء الاصطناعي. إذا كنت تعمل في مجال الذكاء الاصطناعي، فالوقت مناسب لاستكشاف ما يمكن أن يفعله FlashMLA من أجلك. ترقبوا المزيد من التحديثات حيث تواصل DeepSeek طرح ميزات جديدة مثيرة طوال أسبوع المصدر المفتوح.