เมื่อสภาพแวดล้อมของ AI กำลังพัฒนาอย่างรวดเร็ว DeepSeek ได้แนะนำโซลูชันที่มีแนวโน้มจะเปลี่ยนแปลงหนึ่งในอุปสรรคที่สำคัญที่สุดในการฝึกและการอนุมานโมเดล AI ขนาดใหญ่ DeepEP ไลบรารีการสื่อสาร Expert Parallelism (EP) ที่เปิดให้ใช้งานสาธารณะตัวแรก จะเปลี่ยนแปลงวิธีการที่โมเดล Mixture-of-Experts (MoE) ถูกปรับใช้และขยายขนาด
การสร้างภาพ วิดีโอ หรือข้อความFlux 1.1 Pro Ultra, Stable Diffusion XL และ Minimax Video 01 ผสานรวมโมเดล AI อย่าง GPT-4o, Claude 3, และ Gemini สำหรับการอนุมานรุ่นถัดไป. เพิ่มประสิทธิภาพทรัพยากรการประมวลผลด้วย AI pipelines อัตโนมัติและการแจกจ่ายตัวแทนอัจฉริยะ. ใช้โมเดลการสร้างภาพ วิดีโอ และข้อความที่มีความก้าวหน้าเพื่อเร่งนวัตกรรม AI ของคุณ. เพิ่มพลังการทำงานของ AI ของคุณวันนี้! สำรวจ Anakin AI Anakin.ai - One-Stop AI App Platform
Generate Content, Images, Videos, and Voice; Craft Automated Workflows, Custom AI Apps, and Intelligent Agents. Your exclusive AI app customization workstation.
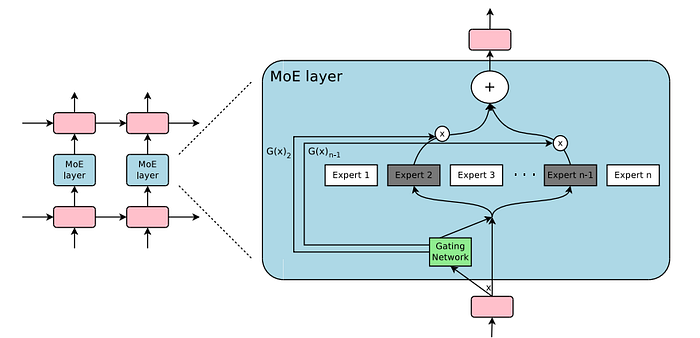
ทำไมโมเดล MoE ถึงสำคัญ โมเดล MoE กำลังกลายเป็นที่นิยมในงานวิจัย AI อย่างรวดเร็ว แทนที่จะทำให้เครือข่ายหนึ่งมีภาระมากเกินไป สถาปัตยกรรมเหล่านี้จะเปิดใช้งานเฉพาะเครือข่ายประสาท “ผู้เชี่ยวชาญ” ที่จำเป็นสำหรับงานเฉพาะ ทำให้มีความมีประสิทธิภาพอย่างมหาศาล ลองนึกภาพว่ามีทีมผู้เชี่ยวชาญแต่ละคนรับผิดชอบในส่วนของพวกเขา แทนที่จะเป็นแค่คนเดียวทำทุกอย่าง นั่นคือเวทมนตร์ของ MoE — ช่วยให้โมเดลขนาดใหญ่สามารถขยายไปสู่พารามิเตอร์หลายล้านโดยไม่ทำให้ค่าใช้จ่ายในการคำนวณพุ่งสูงขึ้น
ความท้าทายในการสื่อสาร อย่างไรก็ตาม ทุกอย่างมีข้อเสียเช่นกัน เมื่อโมเดล MoE เติบโตขึ้น ความจำเป็นในการกำหนดเส้นทางโทเค็นไปยังผู้เชี่ยวชาญที่ถูกต้องก็เติบโตตามไปด้วย ไม่ว่าจะอยู่บน GPU เดียวกันหรือกระจายอยู่ในโหนดต่างๆ ไลบรารีการสื่อสารแบบดั้งเดิมไม่เหมาะสมกับการแลกเปลี่ยนข้อมูลประเภทนี้ ผลลัพธ์? การฝึกอบรมช้าลง ความหน่วงในกระบวนการอนุมานเพิ่มขึ้น และฮาร์ดแวร์ไม่ได้รับการใช้ประโยชน์อย่างเต็มที่ เมื่อคุณแข่งกับเวลาและค่าใช้จ่าย ทุกไมโครวินาทีมีค่า
DeepSeek DeepEP อัดแน่น: มันคืออะไร มันทำอะไร และมันทำงานอย่างไร คุณอาจถามว่า “DeepSeek DeepEP คืออะไร?” มาลงรายละเอียดกันในภาษาอังกฤษที่เรียบง่าย DeepEP เป็นไลบรารีการสื่อสารแบบโอเพนซอร์สที่สร้างโดย DeepSeek มันถูกออกแบบมาโดยเฉพาะเพื่อช่วยในงานหนักที่เกิดขึ้นในโมเดล MoE — โมเดลที่แบ่งงานระหว่างผู้เชี่ยวชาญที่มีความเชี่ยวชาญหลายคน โดยสรุป DeepEP ตรวจสอบให้แน่ใจว่าข้อมูลทุกชิ้นจะเดินทางไปยังผู้เชี่ยวชาญที่ถูกต้องอย่างรวดเร็วและราบรื่น
DeepEP ทำอะไร? กล่าวง่ายๆ ว่า DeepEP ทำให้การสลับข้อมูลระหว่างผู้เชี่ยวชาญมีความคล่องตัว มันดูแลการจัดส่งโทเค็นข้อมูลไปยังผู้เชี่ยวชาญที่เหมาะสมและจากนั้นเก็บผลลัพธ์อย่างมีประสิทธิภาพ โดยการทำเช่นนี้ มันช่วยลดความล่าช้าและอุปสรรคที่มักชะลอการฝึกอบรมและการอนุมานในระบบ AI ขนาดใหญ่
มันทำงานอย่างไร? DeepEP ใช้เทคโนโลยีการสื่อสารความเร็วสูง:
ภายในเครื่อง: 153 GB/s ข้ามเครื่อง: 47 GB/s การจัดการความแม่นยำ: ตัวอย่างในสถานการณ์จริง: ลองนึกว่าคุณกำลังทำงานในร้านอาหารในช่วงเวลาเร่งด่วน ออเดอร์ (โทเค็นข้อมูล) เข้ามาและต้องส่งไปยังเชฟที่ถูกต้อง (ผู้เชี่ยวชาญ) สำหรับเมนูพิเศษของเขา ระบบแบบดั้งเดิมอาจทำให้ออเดอร์ผิดพลาดหรือทำให้การส่งล่าช้า ส่งผลให้บริการช้าและลูกค้ารู้สึกไม่พอใจ ด้วย DeepEP ออเดอร์แต่ละรายการจะถูกส่งไปยังเชฟที่ถูกต้องอย่างรวดเร็ว และจานที่เสร็จแล้วจะถูกส่งกลับไปยังบริกร (ผลรวม) โดยตรง เพื่อให้แน่ใจว่าลูกค้าแต่ละคนจะได้รับอาหารตรงเวลา กระบวนการที่มีความคล่องตัวนี้คือสิ่งที่ DeepEP ทำสำหรับโมเดล MoE — ทำให้แน่ใจว่าข้อมูลทุกชิ้นถูกจัดการอย่างรวดเร็วและถูกต้อง ผลกระทบในโลกแห่งความเป็นจริง ผลประโยชน์ของ DeepEP ไม่ได้เป็นเพียงทฤษฎี — มันกำลังสร้างคลื่นในแอปพลิเคชันในโลกแห่งความเป็นจริง ผู้ใช้เบื้องต้นได้รายงานว่า:
กระบวนการโทเค็นเร็วขึ้น 55% ลดเวลาการวนรอบลง 30% ประสิทธิภาพการใช้พลังงานที่ดีขึ้น การปรับปรุงเหล่านี้ไม่ได้เป็นเพียงตัวเลขในหน้า; มันแปลไปสู่การประหยัดที่จับต้องได้ในค่าใช้จ่ายของคลาวด์ รอบการทดลองที่เร็วขึ้น และการเพิ่มขึ้นอย่างมีนัยสำคัญในความสามารถในการขยายขนาด ไม่ว่าคุณจะฝึกโมเดลภาษาใหญ่หรือขับเคลื่อนการวิเคราะห์วิดีโอแบบเรียลไทม์ DeepEP กำลังแสดงความคุ้มค่าทั่วทั้งระบบ
มองไปข้างหน้า DeepEP ไม่ได้นั่งเฉยๆ แผนงานมีความน่าตื่นเต้น:
การเชื่อมต่อแบบออพติคัล การปรับความแม่นยำอัตโนมัติ บางคนยังบอกใบ้ถึง การกำหนดเส้นทางที่ได้รับแรงบันดาลใจจากควอนตัม คำตัดสิน ดังนั้น คำสุดท้ายเกี่ยวกับ DeepEP คืออะไร? มันเป็นลมที่โปร่งสบายสำหรับทุกคนที่ทำงานกับโมเดล MoE โดยการแก้ไขหนึ่งในอุปสรรคที่ยากที่สุดในการฝึกและอนุมาน AI DeepEP ไม่เพียงแต่เพิ่มความเร็วและประสิทธิภาพ แต่ยังเปิดโอกาสในการเข้าถึงเครื่องมือการสื่อสารที่มีประสิทธิภาพสูงผ่านธรรมชาติของการเปิดใช้งานสาธารณะ ผู้เชี่ยวชาญทางด้านต่างๆ ร่วมชมเชยความสามารถของมันในการสร้างความสมดุลระหว่างความเข้มงวดด้านเทคนิคกับประโยชน์ในโลกแห่งความเป็นจริง
โดยสรุป DeepEP กำลังพลิกโฉมความท้าทายในการสื่อสารแบบดั้งเดิมใน AI มันเป็นเครื่องมือที่ไม่เพียงแต่ผลักดันขอบเขตของสิ่งที่เป็นไปได้ แต่ยังทำให้กระบวนการทั้งหมดราบรื่น เร็วขึ้น และประหยัดพลังงานมากขึ้น สำหรับผู้ที่อยู่ในชุมชน AI นี่เป็นการค้นพบหนึ่งที่คุณต้องติดตามให้ดี
ตามคำกล่าวที่ว่า เมื่อใดก็ตามที่มีข้อท้าทายที่หนักหน่วง คนที่เข้มแข็งจะก้าวหน้า — และด้วย DeepEP อนาคตของ AI ที่กระจายดูสดใสขึ้นกว่าเดิม