คุณเคยฝันถึงการสร้างวิดีโอที่น่าทึ่งจาก AI แต่รู้สึกถูกจำกัดด้วยเครื่องมือที่มีราคาสูงและเป็นกรรมสิทธิ์อย่าง OpenAI’s Sora หรือเปล่า? คุณไม่ได้อยู่คนเดียว การเปิดตัวล่าสุดของ Open-Sora ซึ่งเป็นโมเดลการสร้างวิดีโอ AI แบบโอเพนซอร์สที่พัฒนาโดย HPC-AI Tech (ทีม Colossal-AI) ได้สร้างความตื่นเต้นให้กับชุมชนนักสร้างสรรค์และเทคโนโลยีอย่างมาก โดยมีความสามารถที่ทรงพลังเทียบเคียงกับทางเลือกเชิงพาณิชย์ Open-Sora กำลังกลายเป็นทางเลือกที่ยอดเยี่ยมในการสร้างวิดีโอ AI ที่เข้าถึงได้และมีคุณภาพสูง
ในบทความนี้ เราจะลงลึกถึงสิ่งที่ทำให้ Open-Sora เป็นเครื่องมือที่เปลี่ยนแปลงวงการ สำรวจการพัฒนา ฟีเจอร์ทางเทคนิค มาตรฐานประสิทธิภาพ และวิธีที่มันเปรียบเทียบกับ Sora ของ OpenAI ไม่ว่าคุณจะเป็นนักสร้างเนื้อหา นักพัฒนา หรือเพียงแค่คนที่หลงใหลใน AI คุณจะพบเหตุผลมากมายที่จะตื่นเต้นเกี่ยวกับ Open-Sora
พร้อมที่จะสำรวจเครื่องมือวิดีโอ AI ที่มีนวัตกรรมมากขึ้นหรือยัง? ตรวจสอบโมเดลการสร้างวิดีโอที่ทรงพลังของ Anakin AI เช่น Minimax Video, Tencent Hunyuan และ Runway ML — ทั้งหมดนี้มีให้บริการในแพลตฟอร์มที่มีประสิทธิภาพ เปลี่ยนโปรเจกต์สร้างสรรค์ของคุณวันนี้: สำรวจ Anakin AI Video Generator วิวัฒนาการของ Open-Sora: จากการเริ่มต้นที่มีแนวโน้มสู่ผู้ท้าชิงในอุตสาหกรรม Open-Sora ไม่ได้กลายเป็นที่พูดถึงในทันที มันได้รับการพัฒนาอย่างมีนัยสำคัญตั้งแต่การเปิดตัวครั้งแรก โดยมีการปรับปรุงความสามารถและประสิทธิภาพอย่างต่อเนื่อง:
ประวัติรุ่นในแวบเดียว: Open-Sora 1.0: การเปิดตัวครั้งแรก กระบวนการฝึกอบรมและสถาปัตยกรรมโมเดลแบบโอเพนซอร์สทั้งหมด Open-Sora 1.1: แนะนำการสร้างวิดีโอหลายความละเอียด หลายความยาว และอัตราส่วนภาพหลายแบบ พร้อมกับการปรับสภาพและการแก้ไขภาพ/วิดีโอ Open-Sora 1.2: เพิ่มการไหลที่แก้ไขได้, 3D-VAE, และเมตริกการประเมินที่พัฒนา Open-Sora 1.3: นำเสนอการปรับความสนใจแบบ Shift-window และ VAE ที่รวมกันในเชิงพื้นที่-เวลา ขยายไปถึง 1.1 พันล้านพารามิเตอร์ Open-Sora 2.0: รุ่นล่าสุดและมีความก้าวหน้ามากที่สุด มีพารามิเตอร์ 11 พันล้านและเกือบเทียบเคียงกับโมเดลที่เป็นกรรมสิทธิ์เช่น Sora ของ OpenAI แต่ละรุ่นได้นำ Open-Sora เข้าใกล้ความเท่าเทียมกับโมเดลเชิงพาณิชย์ที่เป็นผู้นำในอุตสาหกรรม ทำให้การเข้าถึงเทคโนโลยีการสร้างวิดีโอ AI ที่ทรงพลังเป็นเรื่องที่เข้าถึงได้มากขึ้น
ใต้ฝากระโปรง: สถาปัตยกรรมทางเทคนิคและฟีเจอร์หลัก อะไรทำให้ Open-Sora 2.0 เป็นทางเลือกที่น่าสนใจสำหรับ Sora ของ OpenAI? มาดูสถาปัตยกรรมที่เป็นนวัตกรรมและความสามารถอันทรงพลัง:
สถาปัตยกรรมโมเดลที่เป็นนวัตกรรม: Masked Motion Diffusion Transformer (MMDiT): ใช้กลไกความสนใจที่ครบถ้วน 3D ขั้นสูง ช่วยเพิ่มการสร้างโมเดลฟังชั่นเชิงพื้นที่และเวลาอย่างมาก Spatio-Temporal Diffusion Transformer (ST-DiT-2): รองรับระยะเวลาวิดีโอที่หลากหลาย ความละเอียดต่างกัน อัตราส่วนภาพและอัตราเฟรม ทำให้มีความหลากหลายสูง High-Compression Video Autoencoder (Video DC-AE): ลดเวลาการอนุมานอย่างมากผ่านการบีบอัดที่มีประสิทธิภาพ ทำให้สามารถสร้างวิดีโอได้เร็วขึ้น ความสามารถในการสร้างที่น่าประทับใจ: Open-Sora 2.0 มีวิธีการสร้างวิดีโอที่หลากหลายและเข้าใจง่าย:
Text-to-Video: สร้างวิดีโอที่น่าสนใจจากคำบรรยายข้อความโดยตรง Image-to-Video: ปฏิญญารูปภาพนิ่งให้มีชีวิตชีวาด้วยการเคลื่อนไหวที่พลัดพราก Video-to-Video: ปรับเนื้อหาวิดีโอที่มีอยู่ได้อย่างราบรื่น Motion Intensity Control: ปรับความเข้มของการเคลื่อนไหวด้วยพารามิเตอร์ "Motion Score" ที่ง่าย (ตั้งแต่ 1 ถึง 7) ฟีเจอร์เหล่านี้ช่วยให้นักสร้างสรรค์สามารถผลิตเนื้อหาที่ปรับแต่งได้สูงและมีสภาพวิสัยสวยงามได้อย่างง่ายดาย
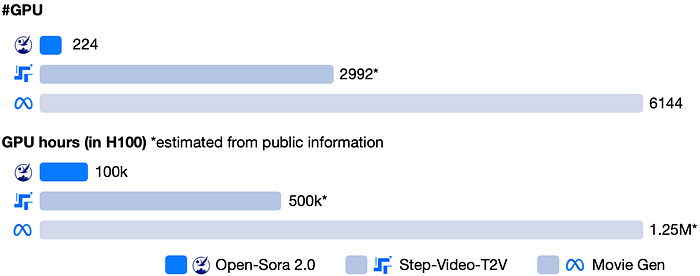
กระบวนการฝึกอบรมที่มีประสิทธิภาพ: ประสิทธิภาพสูงในราคาที่ถูกลงมาก หนึ่งในความสำเร็จที่โดดเด่นของ Open-Sora คือวิธีการฝึกอบรมที่คุ้มค่า ด้วยการใช้กลยุทธ์ที่เป็นนวัตกรรม ทีม Open-Sora ได้ลดค่าใช้จ่ายในการฝึกอบรมอย่างมากเมื่อเปรียบเทียบกับมาตรฐานในอุตสาหกรรม:
กลยุทธ์การฝึกอบรมที่ชาญฉลาด: การฝึกอบรมหลายขั้นตอน: เริ่มต้นด้วยเฟรมความละเอียดต่ำ จากนั้นค่อยๆ ปรับแต่งเพื่อให้ได้ผลลัพธ์ความละเอียดสูง กลยุทธ์การตั้งค่าให้ความสำคัญกับความละเอียดต่ำ: ให้ความสำคัญกับการเรียนรู้คุณลักษณะการเคลื่อนไหวก่อน แล้วค่อยปรับปรุงคุณภาพ ประหยัดทรัพยากรการคอมพิวเตอร์ได้สูงสุดถึง 40 เท่า การกรองข้อมูลอย่างเข้มงวด: รับรองว่ามีข้อมูลการฝึกอบรมที่มีคุณภาพ เพิ่มประสิทธิภาพโดยรวม การประมวลผลแบบขนาน: ใช้ ColossalAI เพื่อเพิ่มประสิทธิภาพการใช้ GPU ในสภาพแวดล้อมการฝึกอบรมที่กระจาย ความคุ้มค่าทางต้นทุนที่โดดเด่น: Open-Sora 2.0: พัฒนาขึ้นโดยใช้งบประมาณประมาณ 200,000 ดอลลาร์ (เทียบเท่ากับ 224 GPUs) Step-Video-T2V: ประมาณ 2992 GPUs (500k ชั่วโมง GPU) Movie Gen: ต้องการประมาณ 6144 GPUs (1.25M ชั่วโมง GPU) นี่แสดงถึงการลดต้นทุนที่เหลือเชื่อถึง 5–10 เท่าเมื่อเปรียบเทียบกับโมเดลการสร้างวิดีโอที่เป็นกรรมสิทธิ์ ทำให้ Open-Sora เข้าถึงได้มากขึ้นสำหรับกลุ่มผู้ใช้และนักพัฒนาที่กว้างขึ้น
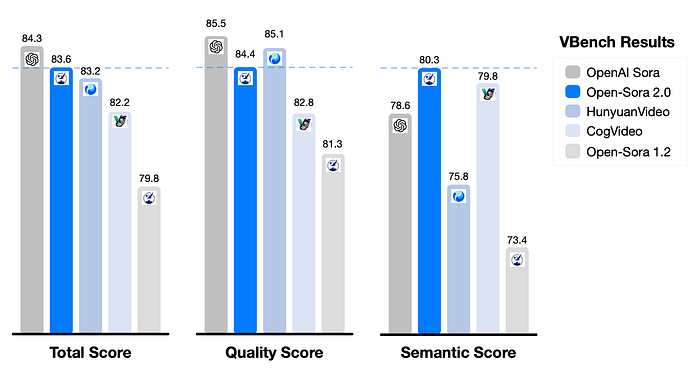
มาตรฐานประสิทธิภาพ: Open-Sora ทำงานได้ดีแค่ไหน? เมื่อประเมินโมเดล AI มาตรฐานประสิทธิภาพมีความสำคัญอย่างยิ่ง Open-Sora 2.0 แสดงผลลัพธ์ที่น่าประทับใจ ใกล้เคียงกับ Sora ของ OpenAI ในมาตรฐานสำคัญ:
ผลการประเมิน VBench: คะแนนรวม: Open-Sora 2.0 ได้คะแนน 83.6 เมื่อเปรียบเทียบกับ 84.3 ของ OpenAI Sora คะแนนคุณภาพ: 84.4 (Open-Sora) เทียบกับ 85.5 (OpenAI Sora) คะแนนความหมาย: 80.3 (Open-Sora) เทียบกับ 78.6 (OpenAI Sora) ช่องว่างด้านประสิทธิภาพระหว่าง Open-Sora และ Sora ของ OpenAI ได้แคบลงอย่างมาก — จาก 4.52% ในรุ่นก่อนหน้าเหลือเพียง 0.69% ในปัจจุบัน
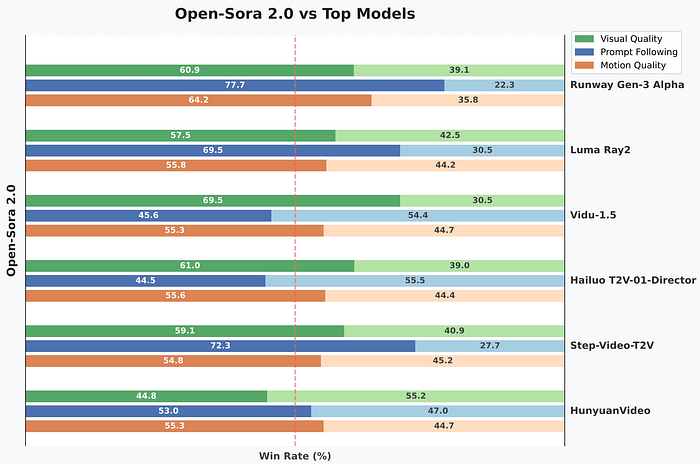
อัตราการชนะความชื่นชอบของผู้ใช้: ในการเปรียบเทียบแบบเผชิญหน้า Open-Sora 2.0 มักจะดีกว่าโมเดลชั้นนำอื่น ๆ:
คุณภาพภาพ: อัตราการชนะ 69.5% ต่อ Vidu-1.5, 61.0% ต่อ Hailuo T2V-01-Director การติดตามคำสั่ง: อัตราการชนะ 77.7% ต่อ Runway Gen-3 Alpha, 72.3% ต่อ Step-Video-T2V คุณภาพการเคลื่อนไหว: อัตราการชนะ 64.2% ต่อ Runway Gen-3 Alpha, 55.8% ต่อ Luma Ray2 ผลลัพธ์เหล่านี้แสดงให้เห็นถึงความได้เปรียบการแข่งขันของ Open-Sora ทำให้เป็นทางเลือกที่น่าเชื่อถือแทนที่ทางเลือกที่แพงกว่า
สเปคการสร้างวิดีโอ: คาดหวังอะไรได้บ้าง? Open-Sora 2.0 เสนอความสามารถในการสร้างวิดีโอที่มีความแข็งแกร่งเหมาะสำหรับความต้องการสร้างสรรค์ที่หลากหลาย:
ความละเอียดและความยาว: รองรับความละเอียดหลายระดับ (256px, 768px) และอัตราส่วนภาพ (16:9, 9:16, 1:1, 2.39:1) สร้างวิดีโอได้สูงสุดถึง 16 วินาทีในคุณภาพสูง (720p) อัตราเฟรมและเวลาในการประมวลผล: ส่งออก 24 FPS ที่สม่ำเสมอเพื่อคุณภาพที่ราบรื่นและมีความเป็นภาพยนตร์ เวลาในการประมวลผลแตกต่างกัน: ความละเอียด 256×256: ประมาณ 60 วินาทีบน GPU ระดับสูงหนึ่งตัว ความละเอียด 768×768: ประมาณ 4.5 นาทีด้วย 8 GPUs แบบขนาน GPU RTX 3090: 30 วินาทีสำหรับวิดีโอ 240p 2 วินาที, 60 วินาทีสำหรับวิดีโอ 4 วินาที ข้อกำหนดด้านฮาร์ดแวร์และการติดตั้ง: เริ่มต้น ในการเริ่มใช้ Open-Sora คุณจะต้องมีข้อกำหนดด้านฮาร์ดแวร์และซอฟต์แวร์เฉพาะ:
ข้อกำหนดของระบบ: Python: เวอร์ชัน 3.8 หรือสูงกว่า PyTorch: เวอร์ชัน 2.1.0 หรือสูงกว่า CUDA: เวอร์ชัน 11.7 หรือสูงกว่า ข้อกำหนดหน่วยความจำ GPU: GPU สำหรับผู้บริโภค (เช่น RTX 3090 ที่มี VRAM 24GB): เหมาะสำหรับวิดีโอสั้นและความละเอียดต่ำ GPU มืออาชีพ (เช่น RTX 6000 Ada ที่มี VRAM 48GB): แนะนำสำหรับความละเอียดสูงและวิดีโอยาว GPU H100/H800: เหมาะสำหรับความละเอียดสูงสุดและภาพลำดับยาว ขั้นตอนการติดตั้ง: คลอนรีโพซิทอรี: git clone https://github.com/hpcaitech/Open-Sora
ตั้งค่าสภาพแวดล้อม Python: conda create -n opensora python=3.8 -y
ติดตั้งแพ็กเกจที่จำเป็น: pip install -e .
ดาวน์โหลดน้ำหนักของโมเดลจากที่เก็บ Hugging Face ปรับใช้หน่วยความจำโดยใช้งาน --save_memory flag ระหว่างการอนุมาน ข้อจำกัดและการพัฒนาที่จะเกิดขึ้น: อนาคตของ Open-Sora? แม้ว่าความสามารถของ Open-Sora 2.0 จะน่าประทับใจ แต่ยังมีข้อจำกัดบางประการ:
ความยาววิดีโอ: ปัจจุบันจำกัดอยู่ที่ 16 วินาทีสำหรับการออกผลคุณภาพสูง ข้อจำกัดความละเอียด: ความละเอียดสูงต้องการ GPU ระดับสูงหลายตัว ข้อจำกัดด้านหน่วยความจำ: GPU สำหรับผู้บริโภคมีขีดความสามารถจำกัด อย่างไรก็ตาม ทีมงาน Open-Sora กำลังทำงานอย่างมุ่งมั่นในด้านการพัฒนา เช่น การแทรกหลายเฟรมและการปรับปรุงความสอดคล้องของข้อมูลเชิงเวลา ทำให้สัญญาว่าจะมีวิดีโอ AI ที่สร้างขึ้นได้เรียบง่ายและยาวนานยิ่งขึ้นในอนาคต
ความคิดสุดท้าย: การทำให้การสร้างวิดีโอ AI เป็นประชาธิปไตย Open-Sora 2.0 เป็นการก้าวที่สำคัญในการทำให้เทคโนโลยีการสร้างวิดีโอ AI เป็นประชาธิปไตย โดยมีประสิทธิภาพเกือบเทียบเคียงกับโมเดลที่เป็นกรรมสิทธิ์อย่าง Sora ของ OpenAI — แต่ในราคาที่ลดลงอย่างมาก — Open-Sora ทำให้ผู้สร้าง นักพัฒนา และธุรกิจสามารถใช้พลังของการสร้างวิดีโอ AI โดยไม่มีค่าใช้จ่ายที่สูง
เมื่อ Open-Sora ยังคงพัฒนา มันยืนอยู่ในที่ที่สามารถปฏิวัติอุตสาหกรรมสร้างสรรค์ มอบเครื่องมือการสร้างวิดีโอที่เข้าถึงได้และมีคุณภาพสูงให้กับทุกคน
พร้อมที่จะสำรวจเครื่องมือการสร้างวิดีโอ AI ที่มีพลังมากขึ้นหรือยัง? ค้นพบ Minimax Video, Tencent Hunyuan, Runway ML และอื่นๆ — ทั้งหมดนี้มีให้บริการบน Anakin AI ปลดปล่อยความคิดสร้างสรรค์ของคุณวันนี้: สำรวจ Anakin AI Video Generator