💡
สนใจแนวโน้มล่าสุดใน AI หรือไม่?
แล้วคุณจะพลาดไม่ได้
Anakin AI !
Anakin AI เป็นแพลตฟอร์มแบบ All-in-one สำหรับการทำงานอัตโนมัติในกระบวนการของคุณ สามารถสร้างแอป AI ที่ทรงพลังด้วยเครื่องมือสร้างแอป No Code ที่ใช้งานง่าย พร้อมด้วย Deepseek, OpenAI's o3-mini-high, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
สร้างแอป AI ที่คุณใฝ่ฝันภายในไม่กี่นาที ไม่ใช่หลายสัปดาห์กับ Anakin AI!
สร้างเวิร์กโฟลว์ตัวแทน AI ได้อย่างง่ายดายด้วย Anakin AI ปัญญาประดิษฐ์ได้ก้าวหน้าอย่างน่าทึ่งในการเข้าใจการสื่อสารของมนุษย์ แต่การรับรู้ถึงอารมณ์อย่างแม่นยำในรูปแบบต่าง ๆ ยังคงเป็นเรื่องที่ท้าทาย โมเดล R1-Omni ที่ Alibaba เพิ่งเปิดตัวแสดงถึงการพัฒนาอย่างมากในด้านนี้ โดยกำหนดให้เป็นแอปพลิเคชันแรกในอุตสาหกรรมของ Reinforcement Learning with Verifiable Reward (RLVR) ต่อโมเดลภาษาขนาดใหญ่แบบ Omni-multimodal.
วิธีการใหม่ในการรับรู้ถึงอารมณ์ อารมณ์ของมนุษย์ซับซ้อนและแสดงออกผ่านช่องทางหลายช่องทางในเวลาเดียวกัน – การแสดงอารมณ์ทางใบหน้า, โทนเสียง, ภาษาใบหน้า, และเนื้อหารายการพูด ระบบการรับรู้อารมณ์แบบดั้งเดิมได้ต่อสู้ในการรวมสัญญาณที่หลากหลายเหล่านี้อย่างมีประสิทธิภาพ มักจะล้มเหลวในการจับปฏิสัมพันธ์ที่ซับซ้อนระหว่างสัญญาณทางสายตาและเสียงที่มนุษย์ประมวลผลโดยสัญชาตญาณ.
R1-Omni แก้ปัญหานี้โดยใช้วิธีการเรียนรู้แบบเสริมกำลังที่ซับซ้อน ซึ่งช่วยให้โมเดลพัฒนาความเข้าใจที่ละเอียดมากขึ้นเกี่ยวกับวิธีที่รูปแบบต่าง ๆ มีส่วนร่วมต่อสถานะอารมณ์ โดยสร้างขึ้นจากพื้นฐาน HumanOmni-0.5B ที่เป็นโอเพนซอร์ส โมเดลนวัตกรรมนี้แสดงความสามารถที่เหนือกว่าในการให้เหตุผล, ความเข้าใจ, และการทั่วถึงเมื่อเปรียบเทียบกับระบบที่ฝึกด้วยวิธีการทั่วไป.
"เรามุ่งเน้นไปที่การรับรู้ถึงอารมณ์ ซึ่งเป็นงานที่ทั้งรูปแบบภาพและเสียงมีบทบาทสำคัญ เพื่อยืนยันศักยภาพของการรวม RLVR กับโมเดล Omni," บันทึกนักวิจัยที่อยู่เบื้องหลัง R1-Omni ในเอกสารทางเทคนิคของพวกเขา.
สถาปัตยกรรมทางเทคนิคและนวัตกรรม ในแกนหลัก R1-Omni ผสมผสานการประมวลผลหลายรูปแบบขั้นสูงเข้ากับเทคนิคการเรียนรู้แบบเสริมกำลังเพื่อสร้างระบบการรับรู้ถึงอารมณ์ที่อธิบายได้และแม่นยำมากขึ้น โมเดลนี้ประมวลผลข้อมูลภาพด้วยหอคอยการมองเห็น SigLIP-base-patch16-224 และจัดการเสียงผ่าน Whisper-large-v3 ซึ่งเป็นโมเดลการประมวลผลเสียงที่ทรงพลังที่สามารถจับสัญญาณเสียงที่ละเอียดที่สื่อถึงข้อมูลอารมณ์.
สิ่งที่ทำให้ R1-Omni แตกต่างจากวิธีการก่อนหน้านี้คือวิธีการฝึกอบรมของมัน ในขณะที่การปรับแต่งโดยการดูแลแบบดั้งเดิม (SFT) ได้ฝึกโมเดลให้คาดการณ์ฉลากอารมณ์จากตัวอย่างที่ได้รับการระบุ R1-Omni ใช้กรอบการเรียนรู้แบบเสริมกำลังที่ซึ่งโมเดลจะได้รับรางวัลไม่เฉพาะจากคาดการณ์ที่ถูกต้อง แต่ยังจากการแสดงเส้นทางการให้เหตุผลที่สามารถตรวจสอบได้ซึ่งนำไปสู่การคาดการณ์เหล่านั้น.
วิธีการใหม่นี้ส่งเสริมการเชื่อมโยงที่อธิบายได้ระหว่างข้อมูลเข้าแบบหลายรูปแบบและการนำเสนออารมณ์ แทนที่จะเรียกอารมณ์ว่า "โกรธ" R1-Omni สามารถระบุสัญญาณภาพเฉพาะ (คิ้วขมวด, กล้ามเนื้อใบหน้าตึง) และลักษณะเสียง (เสียงที่ดังขึ้น, การพูดอย่างรวดเร็ว) ที่มีส่วนในการประเมินของมัน – ความสามารถที่สำคัญในการสร้างความไว้วางใจในระบบ AI ที่ใช้งานในบริบทที่ละเอียดอ่อน.
ความสามารถและประสิทธิภาพหลัก R1-Omni แสดงให้เห็นถึงการพัฒนาสามประการที่สำคัญเมื่อเปรียบเทียบกับระบบการรับรู้อารมณ์ก่อนหน้า:
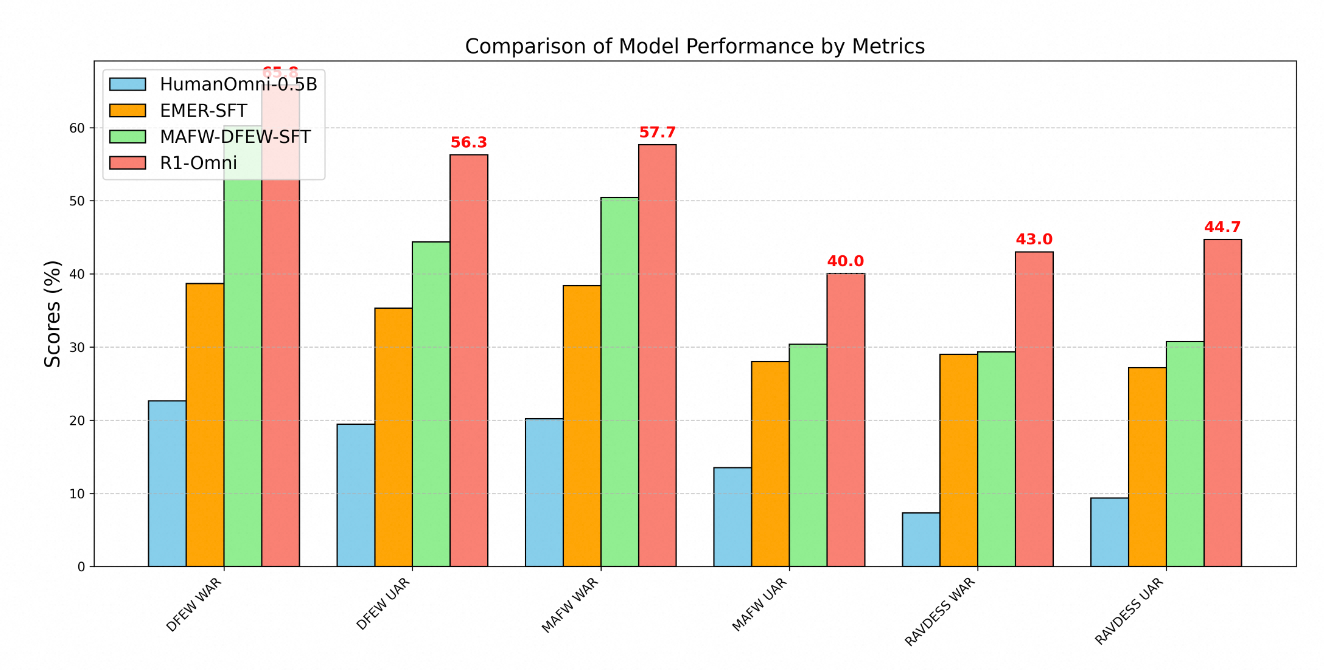
ความสามารถในการให้เหตุผลที่เสริมขึ้น : โมเดลนี้ให้คำอธิบายรายละเอียดสำหรับการจำแนกประเภทของมัน โดยเชื่อมโยงการสังเกตแบบหลายรูปแบบเฉพาะเข้ากับข้อสรุปทางอารมณ์ ความโปร่งใสนี้แสดงถึงการปรับปรุงที่สำคัญเมื่อเปรียบเทียบกับวิธีการ "กล่องดำ" ที่เสนอการจำแนกประเภทโดยไม่มีคำอธิบาย.ความสามารถในการเข้าใจที่ดีขึ้น : เมื่อเปรียบเทียบกับโมเดลที่ฝึกโดยวิธีการปรับแต่งโดยการดูแล R1-Omni แสดงความถูกต้องที่ดีขึ้นอย่างมากในงานการรับรู้อารมณ์ นี้บ่งชี้ว่าหลักการการเรียนรู้แบบเสริมกำลังช่วยพัฒนาแบบจำลองการแสดงออกของสถานะอารมณ์ที่มีความละเอียดมากขึ้นซึ่งตรงกับการตัดสินใจของมนุษย์ได้ดียิ่งขึ้น.ความสามารถในการทั่วไปที่แข็งแกร่งขึ้น : อาจจะน่าประทับใจที่สุด R1-Omni แสดงให้เห็นถึงประสิทธิภาพที่โดดเด่นในข้อมูลที่อยู่นอกการแจกแจง – สถานการณ์ที่แตกต่างจากตัวอย่างการฝึกของมัน ความสามารถในการทั่วไปนอกกรอบการฝึกเฉพาะนี้มีความสำคัญต่อการใช้งานในชีวิตจริง.ความเหนือกว่าทางเทคนิคของ R1-Omni ได้รับการแสดงอย่างชัดเจนผ่านมาตรวัดประสิทธิภาพในหลาย ๆ เกณฑ์การรับรู้อารมณ์ การทดสอบจากสามชุดข้อมูลหลัก – DFEW, MAFW และ RAVDESS – ให้การประเมินที่ครอบคลุมเกี่ยวกับความสามารถของโมเดลทั้งในข้อมูลการแจกแจงและนอกการแจกแจง.
ในชุดข้อมูล DFEW R1-Omni มีการบรรลุค่าเฉลี่ยของการเรียกคืนที่ถ่วงน้ำหนัก (WAR) ที่ 65.83% และค่าเฉลี่ยการเรียกคืนที่ไม่ถ่วงน้ำหนัก (UAR) ที่ 56.27% โดย outperforming ทั้งโมเดล HumanOmni-0.5B (22.64% WAR) และโมเดล MAFW-DFEW-SFT (60.23% WAR) ซึ่งได้รับการปรับแต่งโดยตรงในชุดการฝึก.
ยิ่งไปกว่านั้นประสิทธิภาพของโมเดลในข้อมูลที่อยู่นอกการแจกแจงคือสิ่งที่น่าสังเกต เมื่อทดสอบในชุดข้อมูล RAVDESS ซึ่งไม่ถูกใช้ในระหว่างการฝึก R1-Omni ได้คะแนน 43% WAR และ 44.69% UAR – ดีกว่าโมเดลพื้นฐาน (7.33% WAR) และสูงกว่าทางเลือกที่ปรับแต่งโดยการดูแลอย่างมาก (29.33% WAR).
วิธีการฝึกอบรม การพัฒนา R1-Omni ปฏิบัติตามกระบวนการฝึกอบรมที่ซับซ้อนในสองขั้นตอน:
เริ่มแรกในขั้นตอน "เริ่มต้นเย็น" นักวิจัยตั้งค่าโมเดลโดยใช้ HumanOmni-0.5B และปรับแต่งมันในชุดข้อมูลที่คัดสรรอย่างระมัดระวังที่ประกอบด้วย 232 ตัวอย่างจากชุดข้อมูลการให้เหตุผลทางอารมณ์ที่อธิบายได้และ 348 ตัวอย่างจากชุดข้อมูล HumanOmni สิ่งนี้ให้ความสามารถพื้นฐานในขณะที่เน้นไปที่กระบวนการให้เหตุผลที่อธิบายได้.
ในขั้นตอนที่สองใช้การเรียนรู้แบบเสริมกำลังที่มีรางวัลที่ตรวจสอบได้โดยใช้ชุดข้อมูลที่มีขนาดใหญ่กว่าอย่างมีนัยสำคัญ ประกอบด้วย 15,306 ตัวอย่างวิดีโอจากชุดข้อมูล MAFW และ DFEW ขั้นตอนการเรียนรู้แบบเสริมกำลังนี้มีความสำคัญในการพัฒนาความสามารถในการให้เหตุผลและทั่วไปขั้นสูงของโมเดล.
ตลอดการฝึกอบรมกระบวนการได้ให้ความสำคัญกับไม่เพียงแต่การจำแนกประเภทที่ถูกต้อง แต่ยังการพัฒนาเส้นทางการให้เหตุผลที่สามารถตรวจสอบได้ ตัวอย่างการฝึกมักรวมไปถึงทั้งฉลากอารมณ์และกระบวนการคิดที่มีโครงสร้างที่เชื่อมโยงการสังเกตเข้ากับข้อสรุป วิธีการนี้กระตุ้นให้โมเดลพัฒนาการเชื่อมโยงที่อธิบายได้แทนที่จะเรียนรู้เพียงความสัมพันธ์ทางสถิติ.
การใช้งานในชีวิตจริง ความสามารถที่แสดงโดย R1-Omni เปิดหนทางมากมายในหลากหลายโดเมน:
การสนับสนุนด้านสุขภาพจิต : โมเดลนี้สามารถช่วยนักบำบัดโดยให้การประเมินที่เป็นกลางเกี่ยวกับสถานะอารมณ์ของผู้ป่วย อาจช่วยในการระบุสัญญาณอารมณ์ที่ละเอียดซึ่งอาจถูกมองข้ามได้.การศึกษา : ระบบที่คล้ายกันสามารถช่วยครูในการประเมินการมีส่วนร่วมและการตอบสนองทางอารมณ์ของนักเรียนต่อสื่อการเรียนรู้ ทำให้สามารถนำเสนอวิธีการศึกษาที่ตอบสนองได้มากขึ้น.บริการลูกค้า : เทคโนโลยีของ R1-Omni สามารถปรับปรุงระบบบริการลูกค้าอัตโนมัติด้วยการรับรู้และตอบสนองต่ออารมณ์ของลูกค้าอย่างเหมาะสม ช่วยเพิ่มอัตราความพึงพอใจ.การวิเคราะห์เนื้อหา : โมเดลนี้สามารถวิเคราะห์เนื้อหาอารมณ์ในวิดีโอและการบันทึกเสียงสำหรับการวิจัยตลาด, การวิเคราะห์สื่อ, และการกลั่นกรองเนื้อหา.ความสามารถในการอธิบายของโมเดลเป็นสิ่งที่มีค่าโดยเฉพาะอย่างยิ่งในบริบทเหล่านี้ เนื่องจากช่วยให้ผู้ปฏิบัติงานมนุษย์เข้าใจและตรวจสอบเหตุผลเบื้องหลังการประเมินอารมณ์ที่สร้างขึ้นโดย AI ความโปร่งใสนี้สร้างความไว้วางใจและสนับสนุนความร่วมมือที่มีประสิทธิผลระหว่างมนุษย์และ AI ซึ่งเป็นสิ่งจำเป็นสำหรับการนำไปใช้อย่างกว้างขวางในโดเมนที่มีความละเอียดอ่อน.
การพัฒนาในอนาคต ตามแผนงานของโครงการ การพัฒนาในอนาคตสำหรับ R1-Omni รวมถึงการบูรณาการรหัสต้นทางของ HumanOmni, การปล่อยกระบวนการผลิตที่มีรายละเอียดมากขึ้น, การเปิดแหล่งข้อมูลการฝึกอบรมทั้งหมด, การพัฒนาความสามารถในการอนุมานข้อมูลจากวิดีโอและเสียงเดียว และการปล่อยผลลัพธ์จากเวอร์ชัน 7B ที่ใหญ่กว่า.
การปรับปรุงเหล่านี้จะช่วยเพิ่มการเข้าถึงและการใช้งานของโมเดลสำหรับนักวิจัยและนักพัฒนา ซึ่งอาจเร่งความก้าวหน้าในสาขาการรับรู้อารมณ์ที่หลายรูปแบบ.
บทสรุป R1-Omni ของ Alibaba แสดงถึงความก้าวหน้าอย่างมากในการรับรู้อารมณ์ที่อิงจาก AI ผ่านการประยุกต์ใช้เทคนิคการเรียนรู้แบบเสริมกำลังที่เป็นนวัตกรรมในการทำความเข้าใจแบบหลายรูปแบบ โดยการเพิ่มความสามารถในการให้เหตุผล, การปรับปรุงความแม่นยำ และการแสดงการทั่วไปที่เหนือกว่าสำหรับสถานการณ์ใหม่ R1-Omni ได้ขยายขอบเขตของสิ่งที่เป็นไปได้ใน AI ทางอารมณ์.
เมื่อเราก้าวไปสู่การตอบสนองในเชิงธรรมชาติระหว่างมนุษย์กับคอมพิวเตอร์ ระบบต่าง ๆ เช่น R1-Omni ที่สามารถรับรู้และตอบสนองต่ออารมณ์ของมนุษย์ได้อย่างแม่นยำในช่องทางการสื่อสารที่แตกต่างกันจะมีบทบาทที่สำคัญยิ่งขึ้น ความสำคัญของโมเดลในการอธิบายและการทั่วไปช่วยให้สามารถแก้ไขข้อจำกัดที่สำคัญของวิธีการก่อนหน้านี้ และสร้างมาตรฐานใหม่สำหรับเทคโนโลยีการรับรู้อารมณ์ที่มีความรับผิดชอบและมีประสิทธิภาพ.
โดยการรวมความแข็งแกร่งของการเรียนรู้แบบเสริมกำลังกับความสามารถในการประมวลผลหลายรูปแบบ Alibaba ได้สร้างระบบการรับรู้อารมณ์ที่ไม่เพียงแต่พัฒนาแล้ว แต่ยังอาจเป็นแนวทางใหม่ในการที่ระบบ AI สามารถเรียนรู้ที่จะเข้าใจความซับซ้อนที่ละเอียดอ่อนของการสื่อสารของมนุษย์.