Тогда вам не стоит упускать Anakin AI!
Anakin AI — это универсальная платформа для автоматизации ваших рабочих процессов, создание мощного ИИ-приложения с помощью простого в использовании конструктора приложений без кодирования, с Deepseek, o3-mini-high от OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
Создайте свое идеальное ИИ-приложение за считанные минуты, а не недели с Anakin AI!

Искусственный интеллект добился значительных успехов в понимании человеческой коммуникации, но точное распознавание эмоций в разных модальностях по-прежнему представляет собой сложную задачу. Недавно представленный модель R1-Omni от Alibaba представляет собой значительный прорыв в этой области, став первой в отрасли реализацией Обучения с подкреплением с проверяемой наградой (RLVR) для многомодальной большой языковой модели.
Новый подход к распознаванию эмоций
Человеческие эмоции сложны и выражаются через множество каналов одновременно – мимику, тон голоса, язык тела и вербальное содержание. Традиционные системы распознавания эмоций испытывают трудности с эффективной интеграцией этих разнообразных сигналов, часто не в состоянии уловить тонкое взаимодействие между визуальными и слуховыми сигналами, которые люди обрабатывают инстинктивно.
R1-Omni решает эту проблему, используя сложный подход к обучению с подкреплением, который позволяет модели развивать более тонкое понимание того, как разные модальности влияют на эмоциональные состояния. Построенная на основе открытого исходного кода HumanOmni-0.5B, эта инновационная модель демонстрирует превосходные способности в рассуждении, понимании и обобщении по сравнению с традиционно обученными системами.
«Мы сосредоточены на распознавании эмоций, задаче, в которой как визуальные, так и аудио модальности играют ключевую роль, чтобы подтвердить потенциал комбинирования RLVR с многомодальной моделью», отмечают исследователи, стоящие за R1-Omni в своей технической документации.
Техническая архитектура и инновации
В своей основе R1-Omni сочетает передовую многомодальную обработку с методами обучения с подкреплением для создания более объяснимой и точной системы распознавания эмоций. Модель обрабатывает визуальные данные с использованием SigLIP-base-patch16-224 и обрабатывает аудио с помощью Whisper-large-v3, мощной модели аудиообработки, способной уловить тонкие голосовые сигналы, которые передают эмоциональную информацию.
Что отличает R1-Omni от предыдущих подходов, так это методология его обучения. В то время как традиционная операторная тонкая настройка (SFT) обучает модели предсказывать метки эмоций на основе аннотированных примеров, R1-Omni использует структуру обучения с подкреплением, где модель получает награду не только за правильные предсказания, но и за демонстрацию проверяемых путей рассуждений, которые ведут к этим предсказаниям.
Этот новый подход способствует объяснимым связям между многомодальными входами и эмоциональными выходами. Вместо простого обозначения эмоции как «злой», R1-Omni может формулировать конкретные визуальные сигналы (намеченные брови, напряженные лицевые мышцы) и аудиохарактеристики (высокий голос, быстрая речь), которые способствуют его оценке — это важная способность для создания доверия к ИИ-системам, используемым в чувствительных контекстах.
Ключевые возможности и производительность
R1-Omni демонстрирует три ключевых достижения по сравнению с предыдущими системами распознавания эмоций:
- Повышенная способность к рассуждению: Модель предоставляет подробные объяснения своих классификаций, связывая конкретные многомодальные наблюдения с эмоциональными выводами. Эта прозрачность представляет собой значительное улучшение по сравнению с «черными ящиками», которые предлагают классификации без объяснений.
- Улучшенная способность к пониманию: По сравнению с моделями, обученными через операторную тонкую настройку, R1-Omni демонстрирует гораздо большую точность в задачах распознавания эмоций. Это предполагает, что подход обучения с подкреплением помогает разработать более тонкие представления об эмоциональных состояниях, которые лучше соответствуют человеческим суждениям.
- Сильная способность к обобщению: Возможно, наиболее впечатляющим является то, что R1-Omni демонстрирует замечательную производительность на данных, не входящих в распределение — сценариях, отличающихся от примеров, на которых он обучался. Эта способность обобщать за пределами конкретных тренировочных контекстов имеет важное значение для реальных приложений.
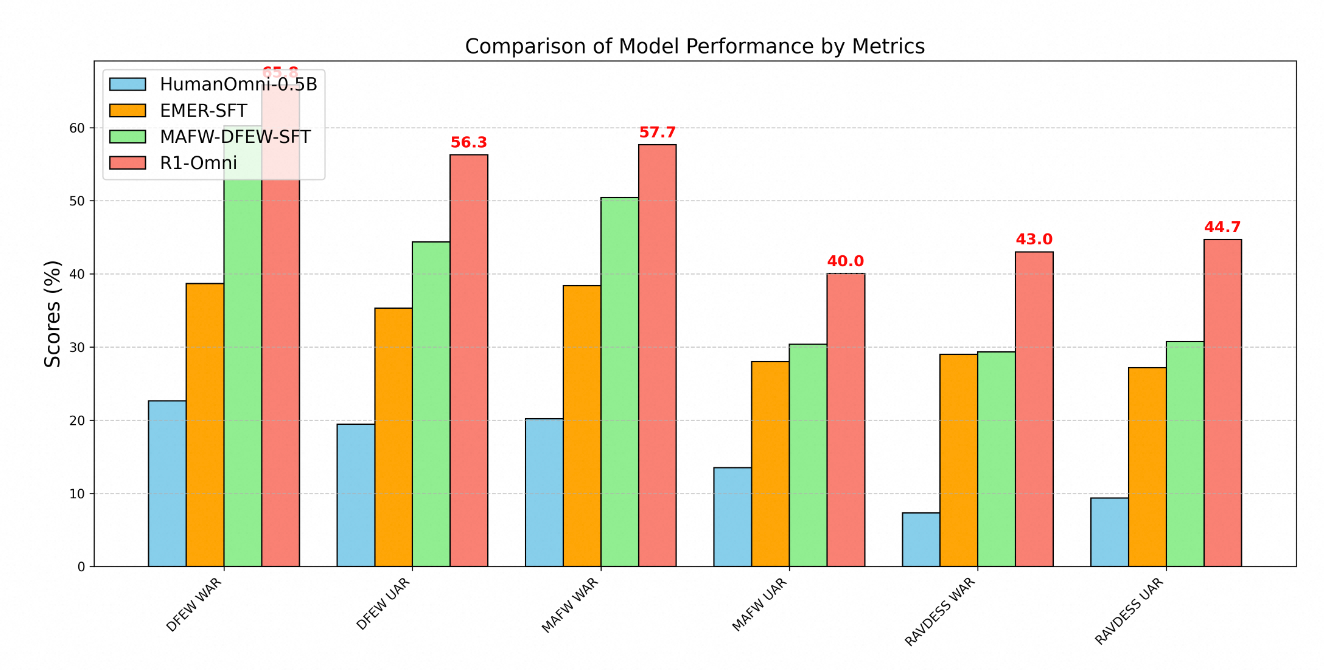
Техническое превосходство R1-Omni четко демонстрируется через метрики производительности на нескольких бенчмарках распознавания эмоций. Тестирование на трех ключевых наборах данных — DFEW, MAFW и RAVDESS — обеспечивает всестороннюю оценку возможностей модели как на данных, входящих в распределение, так и на данных, не входящих в распределение.
На наборе данных DFEW R1-Omni достиг средневзвешенной точности (WAR) 65.83% и не взвешенной средней точности (UAR) 56.27%, значительно превзойдя как базовую модель HumanOmni-0.5B (22.64% WAR), так и модель MAFW-DFEW-SFT (60.23% WAR), которая была непосредственно настроена на обучающих наборах.
Еще более показательной является производительность модели на данных, не входящих в распределение. При тестировании на наборе данных RAVDESS, который не использовался во время обучения, R1-Omni достиг 43% WAR и 44.69% UAR — это значительно лучше, чем у базовой модели (7.33% WAR) и существенно выше, чем у альтернатив, обученных с помощью тонкой настройки (29.33% WAR).
Методология обучения
Разработка R1-Omni прошла через сложный процесс обучения в два этапа:
Во-первых, на этапе «холодного старта» исследователи инициализировали модель, используя HumanOmni-0.5B, и донастраивали ее на тщательно подобранном наборе данных, состоящем из 232 образцов из набора данных Explainable Multimodal Emotion Reasoning и 348 образцов из набора данных HumanOmni. Это обеспечивало базовые возможности, акцентируя внимание на объяснимых процессах рассуждения.
На втором этапе было использовано Обучение с Подкреплением с Проверяемой Наградой, используя значительно больший набор данных, состоящий из 15,306 видеообразцов из наборов данных MAFW и DFEW. Этот этап обучения с подкреплением был критически важен для разработки продвинутых способностей модели к рассуждению и обобщению.
В ходе обучения процесс ставил в приоритет не только точную классификацию, но и развитие проверяемых путей рассуждений. Обычно примеры для обучения включали как метки эмоций, так и структурированные мыслительные процессы, соединяющие наблюдения с выводами. Этот подход побуждал модель развивать объяснимые связи, а не просто изучать статистические корреляции.
Применение в реальном мире
Возможности, продемонстрированные R1-Omni, открывают множество возможностей в различных областях:
- Поддержка психического здоровья: Модель может помогать терапевтам, предоставляя объективные оценки эмоциональных состояний пациентов, потенциально выявляя тонкие эмоциональные сигналы, которые в противном случае могут быть упущены.
- Образование: Похожие системы могут помогать учителям оценивать вовлеченность учащихся и эмоциональные реакции на учебные материалы, позволяя более гибкий подход к обучению.
- Обслуживание клиентов: Технология R1-Omni может улучшить автоматизированные системы обслуживания клиентов, распознавая и адекватно реагируя на эмоции клиентов, повышая уровень удовлетворенности.
- Анализ контента: Модель может анализировать эмоциональное содержание в видеозаписях и аудиозаписях для маркетинговых исследований, медиа-анализа и модерации контента.
Объяснимость модели особенно ценна в этих контекстах, поскольку она позволяет оператору понимать и проверять рассуждения, стоящие за эмпирическими оценками эмоций, генерируемыми ИИ. Эта прозрачность создает доверие и содействует эффективному сотрудничеству человека и ИИ, что необходимо для широкого внедрения в чувствительных областях.
Будущее развитие
Согласно дорожной карте проекта, будущие разработки для R1-Omni включают интеграцию исходного кода HumanOmni, публикацию более детального процесса воспроизводства, открытие всех обучающих данных, разработку возможностей вывода для данных с единичным видео и единичным аудио и публикацию результатов от более крупной версии модели на 7B.
Эти запланированные улучшения furtherповысят доступность и полезность модели для исследователей и разработчиков, потенциально ускоряя прогресс в области многомодального распознавания эмоций.
Заключение
Модель R1-Omni от Alibaba представляет собой значительное достижение в распознавании эмоций на основе ИИ благодаря инновационному применению техник обучения с подкреплением для многомодального понимания. Улучшая способности к рассуждению, повышая точность и демонстрируя превосходное обобщение в новых сценариях, R1-Omni расширяет границы возможного в эмоциональном ИИ.
По мере того как мы движемся к более естественному взаимодействию между человеком и компьютером, такие системы, как R1-Omni, которые могут точно распознавать и реагировать на человеческие эмоции через различные коммуникационные каналы, будут играть все более важную роль. Акцент модели на объяснимости и обобщении отвечает важным ограничениям предыдущих подходов, устанавливая новый стандарт для ответственной и эффективной технологии распознавания эмоций.
Объединив сильные стороны обучения с подкреплением и многомодальной обработки, Alibaba создала не просто улучшенную систему распознавания эмоций, но потенциально новую парадигму того, как ИИ-системы могут учиться понимать тонкие сложности человеческой коммуникации.