Modelo R1-Omni da Alibaba: Pioneirismo no Reconhecimento Emocional Multimodal com Aprendizado por Reforço
💡Está interessado na última tendência em IA?
Então, você não pode perder Anakin AI!
Anakin AI é uma plataforma tudo-em-um para toda a automação do seu fluxo de trabalho, crie poderosos aplicativos de IA com um construtor de aplicativos fácil de usar e sem código, com Deepseek, o modelo o3-mini-high
Anakin AI é uma plataforma tudo-em-um para toda a automação do seu fluxo de trabalho, crie poderosos aplicativos de IA com um construtor de aplicativos fácil de usar e sem código, com Deepseek, o modelo o3-mini-high da OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
Construa seu aplicativo de IA dos sonhos em minutos, não em semanas, com Anakin AI!
Construa facilmente fluxos de trabalho agenticos de IA com Anakin AI
A inteligência artificial fez avanços notáveis na compreensão da comunicação humana, mas reconhecer com precisão as emoções através de diferentes modalidades continua desafiador. O modelo R1-Omni, recentemente revelado pela Alibaba, representa um avanço significativo neste domínio, estabelecendo-se como a primeira aplicação da indústria de Aprendizado por Reforço com Recompensa Verificável (RLVR) em um modelo de linguagem multimodal Omni de grande porte.
Uma Nova Abordagem para Reconhecimento de Emoções
As emoções humanas são complexas e se manifestam através de múltiplos canais simultaneamente – expressões faciais, tons vocais, linguagem corporal e conteúdo verbal. Sistemas tradicionais de reconhecimento de emoções lutaram para integrar esses sinais diversos de forma eficaz, frequentemente falhando em capturar a interação sutil entre as dicas visuais e auditivas que os humanos processam instintivamente.
O R1-Omni aborda esse desafio aproveitando uma abordagem sofisticada de aprendizado por reforço que permite ao modelo desenvolver uma compreensão mais refinada de como diferentes modalidades contribuem para estados emocionais. Baseado na fundação de código aberto HumanOmni-0.5B, este modelo inovador demonstra capacidades superiores em raciocínio, compreensão e generalização em comparação com sistemas treinados convencionalmente.
"Focamos no reconhecimento de emoções, uma tarefa onde tanto as modalidades visuais quanto as auditivas desempenham papéis cruciais, para validar o potencial de combinar RLVR com o modelo Omni," observam os pesquisadores por trás do R1-Omni em sua documentação técnica.
Arquitetura Técnica e Inovação
No seu núcleo, o R1-Omni combina processamento multimodal avançado com técnicas de aprendizado por reforço para criar um sistema de reconhecimento de emoções mais explicável e preciso. O modelo processa entradas visuais usando a torre de visão SigLIP-base-patch16-224 e manipula áudio através do Whisper-large-v3, um poderoso modelo de processamento de áudio capaz de capturar dicas vocais sutis que transmitem informações emocionais.
O que distingue o R1-Omni de abordagens anteriores é sua metodologia de treinamento. Enquanto o ajuste fino supervisionado tradicional (SFT) treina modelos para prever rótulos de emoções com base em exemplos anotados, o R1-Omni emprega uma estrutura de aprendizado por reforço onde o modelo é recompensado não apenas por previsões corretas, mas por demonstrar caminhos de raciocínio verificáveis que levam a essas previsões.
Essa abordagem inovadora promove conexões explicáveis entre entradas multimodais e saídas emocionais. Em vez de simplesmente rotular uma emoção como "irritado", o R1-Omni pode articular dicas visuais específicas (sobrancelhas franzidas, músculos faciais tensos) e características auditivas (voz elevada, fala rápida) que contribuem para sua avaliação – uma capacidade crucial para construir confiança em sistemas de IA implantados em contextos sensíveis.
Principais Capacidades e Desempenho
O R1-Omni demonstra três avanços principais sobre os sistemas de reconhecimento de emoções anteriores:
Capacidade de Raciocínio Aprimorada: O modelo fornece explicações detalhadas para suas classificações, conectando observações multimodais específicas a conclusões emocionais. Essa transparência representa uma melhora significativa em relação a abordagens de "caixa preta" que oferecem classificações sem explicações.
Capacidade de Compreensão Aprimorada: Em comparação com modelos treinados através de ajuste fino supervisionado, o R1-Omni demonstra uma precisão substancialmente melhor em tarefas de reconhecimento de emoções. Isso sugere que a abordagem de aprendizado por reforço ajuda a desenvolver representações mais sutis dos estados emocionais que se alinham melhor com os julgamentos humanos.
Capacidade de Generalização Mais Forte: Talvez o mais impressionante, o R1-Omni exibe um desempenho notável em dados fora da distribuição – cenários que diferem de seus exemplos de treinamento. Essa habilidade de generalizar além de contextos de treinamento específicos é crucial para aplicações do mundo real.
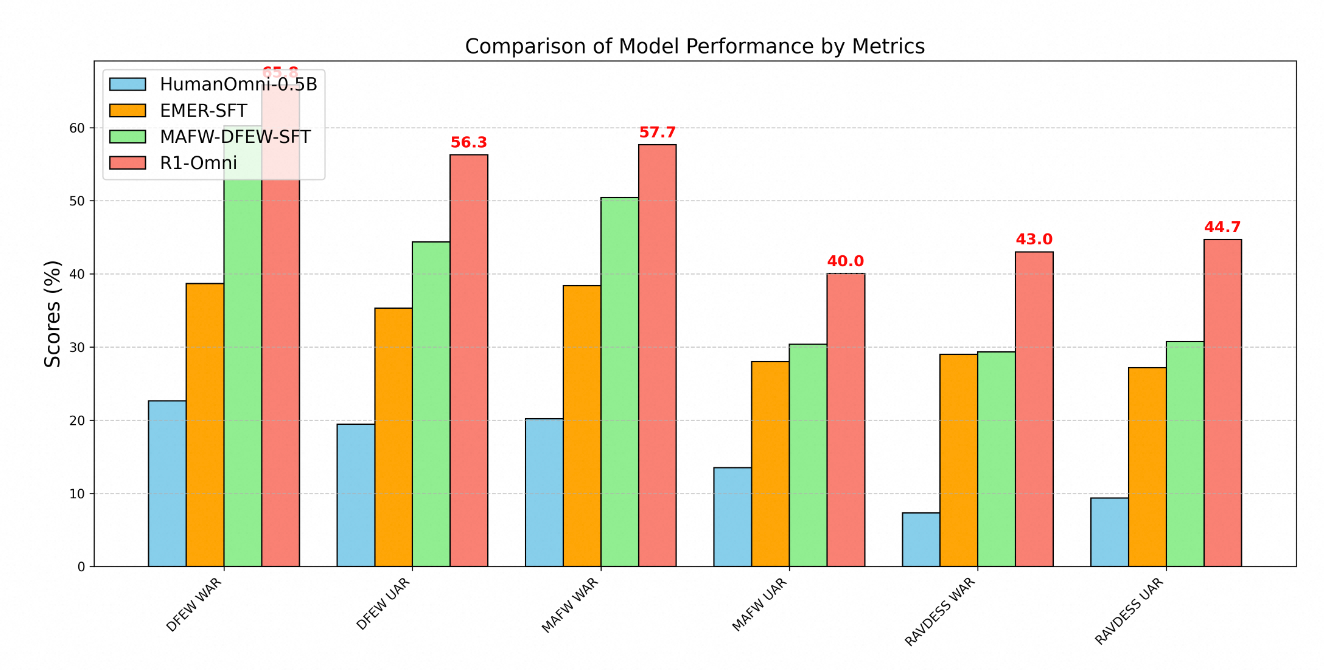
A superioridade técnica do R1-Omni é claramente demonstrada através de métricas de desempenho em múltiplos benchmarks de reconhecimento de emoções. Testes em três conjuntos de dados chave – DFEW, MAFW e RAVDESS – fornecem uma avaliação abrangente das capacidades do modelo tanto em dados dentro da distribuição quanto fora dela.
No conjunto de dados DFEW, o R1-Omni alcançou um recall médio ponderado (WAR) de 65,83% e um recall médio não ponderado (UAR) de 56,27%, superando substancialmente o modelo base HumanOmni-0.5B (22,64% WAR) e o modelo MAFW-DFEW-SFT (60,23% WAR) que foi ajustado diretamente nos conjuntos de treinamento.
Ainda mais revelador é o desempenho do modelo em dados fora da distribuição. Quando testado no conjunto de dados RAVDESS, que não foi utilizado durante o treinamento, o R1-Omni alcançou 43% WAR e 44,69% UAR – dramaticamente melhor que o modelo base (7,33% WAR) e substancialmente mais alto que alternativas de ajuste fino supervisionado (29,33% WAR).
Metodologia de Treinamento
O desenvolvimento do R1-Omni seguiu um processo de treinamento sofisticado em duas etapas:
Primeiro, na fase de "início frio", os pesquisadores inicializaram o modelo usando HumanOmni-0.5B e o ajustaram em um conjunto de dados cuidadosamente selecionado, composto por 232 amostras do conjunto de dados de Raciocínio Multimodal Explicável e 348 amostras do conjunto de dados HumanOmni. Isso forneceu capacidades fundamentais enquanto enfatizava processos de raciocínio explicáveis.
A segunda etapa empregou Aprendizado por Reforço com Recompensa Verificável usando um conjunto de dados substancialmente maior, composto por 15.306 amostras de vídeo dos conjuntos de dados MAFW e DFEW. Esta fase de aprendizado por reforço foi crítica para desenvolver as capacidades avançadas de raciocínio e generalização do modelo.
Durante o treinamento, o processo priorizou não apenas a classificação precisa, mas também o desenvolvimento de caminhos de raciocínio verificáveis. Exemplos de treinamento normalmente incluíam tanto rótulos de emoções quanto processos de pensamento estruturados conectando observações a conclusões. Essa abordagem incentivou o modelo a desenvolver conexões explicáveis em vez de simplesmente aprender correlações estatísticas.
Aplicações no Mundo Real
As capacidades demonstradas pelo R1-Omni abrem inúmeras possibilidades em diversos domínios:
Suporte à Saúde Mental: O modelo poderia ajudar terapeutas fornecendo avaliações objetivas dos estados emocionais dos pacientes, potencialmente identificando dicas emocionais sutis que poderiam passar despercebidas.
Educação: Sistemas semelhantes poderiam ajudar professores a avaliar o envolvimento dos alunos e as respostas emocionais aos materiais de aprendizagem, permitindo abordagens educacionais mais responsivas.
Atendimento ao Cliente: A tecnologia do R1-Omni poderia melhorar sistemas automatizados de atendimento ao cliente reconhecendo e respondendo de forma apropriada às emoções dos clientes, aumentando as taxas de satisfação.
Análise de Conteúdo: O modelo poderia analisar o conteúdo emocional em vídeos e gravações de áudio para pesquisa de mercado, análise de mídia e moderação de conteúdo.
A explicabilidade do modelo é particularmente valiosa nesses contextos, pois permite que operadores humanos entendam e validem o raciocínio por trás das avaliações emocionais geradas pela IA. Essa transparência constrói confiança e facilita uma colaboração eficaz entre humanos e IA, essencial para uma adoção ampla em domínios sensíveis.
Desenvolvimento Futuro
De acordo com o roteiro do projeto, os desenvolvimentos futuros para o R1-Omni incluem a integração do código fonte do HumanOmni, a liberação de um processo de reprodução mais detalhado, a disponibilização de todos os dados de treinamento como código aberto, o desenvolvimento de capacidades de inferência para dados de vídeo e áudio individuais, e a liberação de resultados de uma versão maior de 7B do modelo.
Esses aprimoramentos planejados aumentarão ainda mais a acessibilidade e a utilidade do modelo para pesquisadores e desenvolvedores, potencialmente acelerando o progresso no campo do reconhecimento de emoções multimodal.
Conclusão
O R1-Omni da Alibaba representa um avanço significativo no reconhecimento de emoções baseado em IA por meio de sua aplicação inovadora de técnicas de aprendizado por reforço à compreensão multimodal. Ao aprimorar as capacidades de raciocínio, melhorar a precisão e demonstrar uma generalização superior a cenários novos, o R1-Omni empurra os limites do que é possível na IA emocional.
À medida que avançamos em direção a uma interação mais natural entre humanos e computadores, sistemas como o R1-Omni, que podem reconhecer e responder com precisão às emoções humanas através de diferentes canais de comunicação, desempenharão um papel cada vez mais importante. A ênfase do modelo em explicabilidade e generalização aborda limitações críticas de abordagens anteriores, estabelecendo um novo padrão para a tecnologia responsável e eficaz de reconhecimento de emoções.
Ao combinar as forças do aprendizado por reforço com as capacidades de processamento multimodal, a Alibaba criou não apenas um sistema de reconhecimento de emoções aprimorado, mas potencialmente um novo paradigma de como os sistemas de IA podem aprender a entender as sutis complexidades da comunicação humana.