Allora non puoi perderti Anakin AI!
Anakin AI è una piattaforma all-in-one per tutta la tua automazione del flusso di lavoro, crea potenti app di IA con un costruttore di app No Code facile da usare, con Deepseek, l'o3-mini-high di OpenAI, Claude 3.7 Sonnet, FLUX, Minimax Video, Hunyuan...
Costruisci la tua app IA dei sogni in pochi minuti, non in settimane con Anakin AI!

L'intelligenza artificiale ha fatto progressi notevoli nella comprensione della comunicazione umana, ma riconoscere accuratamente le emozioni in diverse modalità rimane una sfida. Il modello R1-Omni recentemente svelato da Alibaba rappresenta un passo avanti significativo in questo campo, stabilendosi come il primo applicativo dell'industria di Reinforcement Learning con Ricompensa Verificabile (RLVR) applicato a un modello di linguaggio multimodale Omni.
Un Nuovo Approccio al Riconoscimento delle Emozioni
Le emozioni umane sono complesse e si esprimono attraverso più canali simultaneamente – espressioni facciali, toni vocali, linguaggio del corpo e contenuto verbale. I sistemi tradizionali di riconoscimento delle emozioni hanno lottato per integrare efficacemente questi segnali diversi, spesso fallendo nel catturare l'interazione sfumata tra segnali visivi e uditivi che gli esseri umani elaborano istintivamente.
R1-Omni affronta questa sfida sfruttando un approccio sofisticato di apprendimento per rinforzo che consente al modello di sviluppare una comprensione più raffinata di come diverse modalità contribuiscono agli stati emotivi. Costruito sulla base open-source HumanOmni-0.5B, questo modello innovativo dimostra capacità superiori nel ragionamento, comprensione e generalizzazione rispetto ai sistemi addestrati convenzionalmente.
"Ci concentriamo sul riconoscimento delle emozioni, un compito in cui sia le modalità visive che quelle audio giocano ruoli cruciali, per convalidare il potenziale di combinare RLVR con il modello Omni," osservano i ricercatori dietro R1-Omni nella loro documentazione tecnica.
Architettura Tecnica e Innovazione
Al suo interno, R1-Omni combina l'elaborazione multimodale avanzata con tecniche di apprendimento per rinforzo per creare un sistema di riconoscimento delle emozioni più spiegabile e preciso. Il modello elabora input visivi utilizzando la torre di visione SigLIP-base-patch16-224 e gestisce l'audio tramite Whisper-large-v3, un potente modello di elaborazione audio capace di catturare sfumature vocali che trasmettono informazioni emotive.
Ciò che distingue R1-Omni dai metodi precedenti è la sua metodologia di addestramento. Mentre il fine-tuning supervisionato tradizionale (SFT) addestra i modelli a prevedere etichette emotive basate su esempi annotati, R1-Omni impiega un framework di apprendimento per rinforzo in cui il modello è premiato non solo per previsioni corrette, ma per dimostrazioni di percorsi di ragionamento verificabili che portano a quelle previsioni.
Questo approccio innovativo promuove connessioni spiegabili tra input multimodali e output emotivi. Piuttosto che limitarsi a etichettare un'emozione come "arrabbiata," R1-Omni può articolare specifici segnali visivi (sopracciglia aggrottate, muscoli facciali tesi) e caratteristiche audio (voce alta, discorsi veloci) che contribuiscono alla sua valutazione – una capacità cruciale per costruire fiducia nei sistemi IA impiegati in contesti sensibili.
Capacità Chiave e Prestazioni
R1-Omni dimostra tre progressi chiave rispetto ai precedenti sistemi di riconoscimento delle emozioni:
- Capacità di Ragionamento Migliorata: Il modello fornisce spiegazioni dettagliate per le sue classificazioni, collegando osservazioni multimodali specifiche a conclusioni emotive. Questa trasparenza rappresenta un miglioramento significativo rispetto agli approcci "scatola nera" che offrono classificazioni senza spiegazioni.
- Capacità di Comprensione Migliorata: Rispetto ai modelli addestrati tramite fine-tuning supervisionato, R1-Omni dimostra un'accuratezza sostanzialmente migliore nei compiti di riconoscimento delle emozioni. Questo suggerisce che l'approccio di apprendimento per rinforzo aiuta a sviluppare rappresentazioni più sfumate degli stati emotivi che si allineano meglio con i giudizi umani.
- Capacità di Generalizzazione Più Forte: Forse più impressionante, R1-Omni mostra prestazioni straordinarie su dati fuori distribuzione – scenari che differiscono dagli esempi di addestramento. Questa capacità di generalizzare oltre contesti di addestramento specifici è cruciale per le applicazioni nel mondo reale.
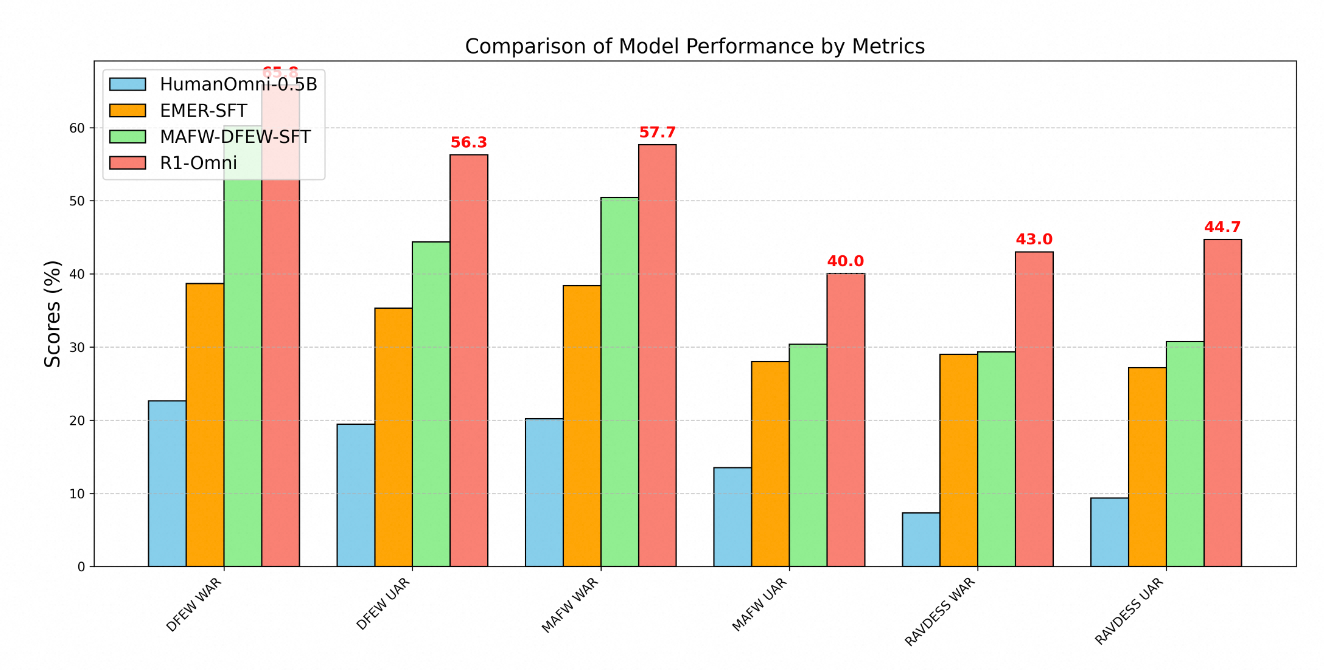
La superiorità tecnica di R1-Omni è chiaramente dimostrata attraverso metriche di prestazione su più benchmark di riconoscimento delle emozioni. Testando su tre dataset chiave – DFEW, MAFW e RAVDESS – si ottiene una valutazione completa delle capacità del modello su dati sia in distribuzione che fuori distribuzione.
Nel dataset DFEW, R1-Omni ha raggiunto un richiamo medio ponderato (WAR) del 65.83% e un richiamo medio non ponderato (UAR) del 56.27%, superando notevolmente sia il modello di base HumanOmni-0.5B (22.64% WAR) che il modello MAFW-DFEW-SFT (60.23% WAR) che è stato direttamente fine-tunato sui set di addestramento.
Ancora più significativo è il rendimento del modello su dati fuori distribuzione. Quando testato sul dataset RAVDESS, non utilizzato durante l'addestramento, R1-Omni ha ottenuto 43% WAR e 44.69% UAR – dramaticamente migliore rispetto al modello base (7.33% WAR) e sostanzialmente superiore rispetto alle alternative a fine-tuning supervisionato (29.33% WAR).
Metodologia di Addestramento
Lo sviluppo di R1-Omni ha seguito un sofisticato processo di addestramento in due fasi:
Per prima cosa, nella fase di "cold start", i ricercatori hanno inizializzato il modello utilizzando HumanOmni-0.5B e l'hanno fine-tunato su un dataset accuratamente curato composto da 232 campioni del dataset di Ragionamento Emotivo Multimodale Spiegabile e 348 campioni del dataset HumanOmni. Questo ha fornito capacità fondamentali enfatizzando i processi di ragionamento spiegabili.
La seconda fase ha impiegato l'Apprendimento per Rinforzo con Ricompensa Verificabile utilizzando un dataset sostanzialmente più grande composto da 15,306 campioni video dai dataset MAFW e DFEW. Questa fase di apprendimento per rinforzo è stata critica nello sviluppare le capacità avanzate di ragionamento e generalizzazione del modello.
Durante l'addestramento, il processo ha prioritizzato non solo la classificazione accurata, ma anche lo sviluppo di percorsi di ragionamento verificabili. Gli esempi di addestramento includevano tipicamente sia etichette emotive che processi di pensiero strutturati che collegano osservazioni a conclusioni. Questo approccio ha incoraggiato il modello a sviluppare connessioni spiegabili piuttosto che imparare semplicemente correlazioni statistiche.
Applicazioni nel Mondo Reale
Le capacità dimostrate da R1-Omni aprono numerose possibilità in diversi ambiti:
- Supporto per la Salute Mentale: Il modello potrebbe assistere i terapeuti fornendo valutazioni oggettive degli stati emotivi dei pazienti, identificando potenzialmente segnali emotivi sottili che altrimenti potrebbero essere trascurati.
- Istruzione: Sistemi simili potrebbero aiutare gli insegnanti a valutare il coinvolgimento degli studenti e le risposte emotive ai materiali didattici, consentendo approcci educativi più reattivi.
- Servizio Clienti: La tecnologia di R1-Omni potrebbe migliorare i sistemi automatizzati di servizio clienti riconoscendo e rispondendo adeguatamente alle emozioni dei clienti, aumentando i tassi di soddisfazione.
- Analisi dei Contenuti: Il modello potrebbe analizzare il contenuto emotivo in video e registrazioni audio per ricerche di mercato, analisi dei media e moderazione dei contenuti.
La spiegabilità del modello è particolarmente preziosa in questi contesti, in quanto consente agli operatori umani di comprendere e convalidare il ragionamento alla base delle valutazioni emotive generate dall'IA. Questa trasparenza costruisce fiducia e facilita una collaborazione efficace uomo-IA, essenziale per l'adozione diffusa in ambiti sensibili.
Sviluppo Futuro
Secondo la tabella di marcia del progetto, gli sviluppi futuri per R1-Omni includono l'integrazione del codice sorgente di HumanOmni, il rilascio di un processo di riproduzione più dettagliato, la pubblicazione di tutti i dati di addestramento come open-source, lo sviluppo di capacità di inferenza per dati di singolo video e modalità audio, e il rilascio di risultati da una versione più grande del modello da 7B.
Questi miglioramenti pianificati aumenteranno ulteriormente l'accessibilità e l'utilità del modello per ricercatori e sviluppatori, potenzialmente accelerando il progresso nel campo del riconoscimento delle emozioni multimodale.
Conclusione
R1-Omni di Alibaba rappresenta un significativo avanzamento nel riconoscimento delle emozioni basato su IA attraverso l'applicazione innovativa di tecniche di apprendimento per rinforzo alla comprensione multimodale. Potenziando le capacità di ragionamento, migliorando l'accuratezza e dimostrando una superiorità di generalizzazione a scenari nuovi, R1-Omni spinge i confini di ciò che è possibile nell'IA emotiva.
Man mano che ci dirigiamo verso interazioni uomo-computer più naturali, sistemi come R1-Omni, che possono riconoscere e rispondere accuratamente alle emozioni umane attraverso diversi canali di comunicazione, giocheranno un ruolo sempre più importante. L'enfasi del modello sulla spiegabilità e sulla generalizzazione affronta limitazioni critiche degli approcci precedenti, stabilendo un nuovo standard per la tecnologia di riconoscimento delle emozioni responsabile ed efficace.
Combinando i punti di forza dell'apprendimento per rinforzo con le capacità di elaborazione multimodale, Alibaba ha creato non solo un sistema di riconoscimento delle emozioni migliorato, ma potenzialmente un nuovo paradigma su come i sistemi IA possono imparare a comprendere le sottili complessità della comunicazione umana.