إذاً، لا يمكنك أن تفوت أنكين AI!
أنكين AI هو منصة شاملة لكل احتياجاتك في أتمتة سير العمل، أنشئ تطبيق ذكاء اصطناعي قوي باستخدام أداة بناء التطبيقات بدون كود سهلة الاستخدام، مع ديب سيك، وOpenAI's o3-mini-high، وكلود 3.7 سونيت، وفلوكس، ومينيماكس فيديو، وهونيون...
ابنِ تطبيق الذكاء الاصطناعي الذي تحلم به في غضون دقائق، وليس أسابيع مع أنكين AI!

لقد أحرز الذكاء الاصطناعي تقدمًا ملحوظًا في فهم التواصل البشري، لكن التعرّف بدقة على المشاعر عبر وسائط متعددة لا يزال يمثل تحديًا. يمثل نموذج R1-Omni الذي أعلنت عنه علي بابا مؤخرًا تقدمًا كبيرًا في هذا المجال، حيث يثبت نفسه كأول تطبيق في الصناعة للتعلم التعزيزي مع مكافأة قابلة للتحقق (RLVR) لنموذج لغة كبير متعدد الوسائط.
نهج جديد للتعرّف على المشاعر
المشاعر البشرية معقدة وتُعبر عنها عبر قنوات متعددة في الوقت نفسه – تعبيرات الوجه، نبرات الصوت، لغة الجسد، والمحتوى اللفظي. لقد كافحت أنظمة التعرف على المشاعر التقليدية لدمج هذه الإشارات المتنوعة بشكل فعال، وغالبًا ما تفشل في التقاط التفاعل الدقيق بين الإشارات البصرية والسمعية التي يعالجها البشر بشكل غريزي.
يتناول R1-Omni هذا التحدي من خلال الاعتماد على نهج متطور في التعلم التعزيزي يمكّن النموذج من تطوير فهم أكثر دقة لكيفية مساهمة الوسائط المختلفة في الحالات العاطفية. تم بناء هذا النموذج الثوري على أساس HumanOmni-0.5B المفتوح المصدر، ويظهر قدرات متفوقة في التفكير والفهم والتعميم مقارنةً بالأنظمة المدربة تقليديًا.
"نركز على التعرّف على المشاعر، وهي مهمة تلعب فيها كل من الوسائط البصرية والصوتية أدوارًا محورية، للتحقق من إمكانية الجمع بين RLVR ونموذج Omni،" لاحظ الباحثون وراء R1-Omni في وثائقهم التقنية.
الهيكلية التقنية والابتكار
في جوهرها، يجمع R1-Omni معالجة متعددة الوسائط المتقدمة مع تقنيات التعلم التعزيزي لإنشاء نظام للتعرّف على المشاعر أكثر قابلية للتفسير ودقة. يعالج النموذج المدخلات البصرية باستخدام برج الرؤية SigLIP-base-patch16-224 ويتعامل مع الصوت عبر Whisper-large-v3، وهو نموذج قوي لمعالجة الصوت قادر على التقاط الإشارات الصوتية الدقيقة التي تنقل المعلومات العاطفية.
ما يميز R1-Omni عن النهجات السابقة هو منهجية تدريبه. بينما تقوم عملية الضبط الدقيق تحت الإشراف (SFT) التقليدية بتدريب النماذج للتنبؤ بتصنيفات المشاعر بناءً على أمثلة مشروحة، يستخدم R1-Omni إطارًا للتعلم التعزيزي حيث يتم مكافأة النموذج ليس فقط على التنبؤات الصحيحة، ولكن أيضًا على إظهار مسارات تفكير قابلة للتحقق تؤدي إلى تلك التنبؤات.
يعزز هذا النهج الجديد الروابط القابلة للتفسير بين المدخلات متعددة الوسائط والمخرجات العاطفية. بدلاً من مجرد تصنيف عاطفة كـ "غاضب"، يمكن لـ R1-Omni التعبير عن إشارات بصرية محددة (حاجبان مجعدان، وعضلات وجه مشدودة) وميزات صوتية (صوت مرتفع، وكلام سريع) تسهم في تقييمه - وهي قدرة حاسمة لبناء الثقة في أنظمة الذكاء الاصطناعي المستخدمة في سياقات حساسة.
القدرات الرئيسية والأداء
يعرض R1-Omni ثلاث تحسينات رئيسية مقارنةً بأنظمة التعرف على المشاعر السابقة:
- قدرة محسنة على التفكير: يقدم النموذج تفسيرات مفصلة لتصنيفاته، موصلاً ملاحظات متعددة الوسائط محددة إلى استنتاجات عاطفية. تمثل هذه الشفافية تحسنًا كبيرًا عن النهجات "صندوق أسود" التي تقدم تصنيفات دون تفسيرات.
- قدرة مُحسّنة على الفهم: مقارنةً بالنماذج التي تم تدريبها من خلال التنظيم الدقيق تحت الإشراف، يُظهر R1-Omni دقة أفضل بكثير في مهام التعرف على المشاعر. وهذا يشير إلى أن نهج التعلم التعزيزي يساعد في تطوير تمثيلات أكثر دقة للحالات العاطفية التي تتماشى بشكل أفضل مع الأحكام البشرية.
- قدرة أقوى على التعميم: ربما الأكثر إثارة للإعجاب، يظهر R1-Omni أداءً رائعًا على بيانات خارج نطاق التدريب - السيناريوهات التي تختلف عن أمثلة التدريب الخاصة به. تعتبر هذه القدرة على التعميم خارج سياقات التدريب المحددة أساسية للتطبيقات في العالم الحقيقي.
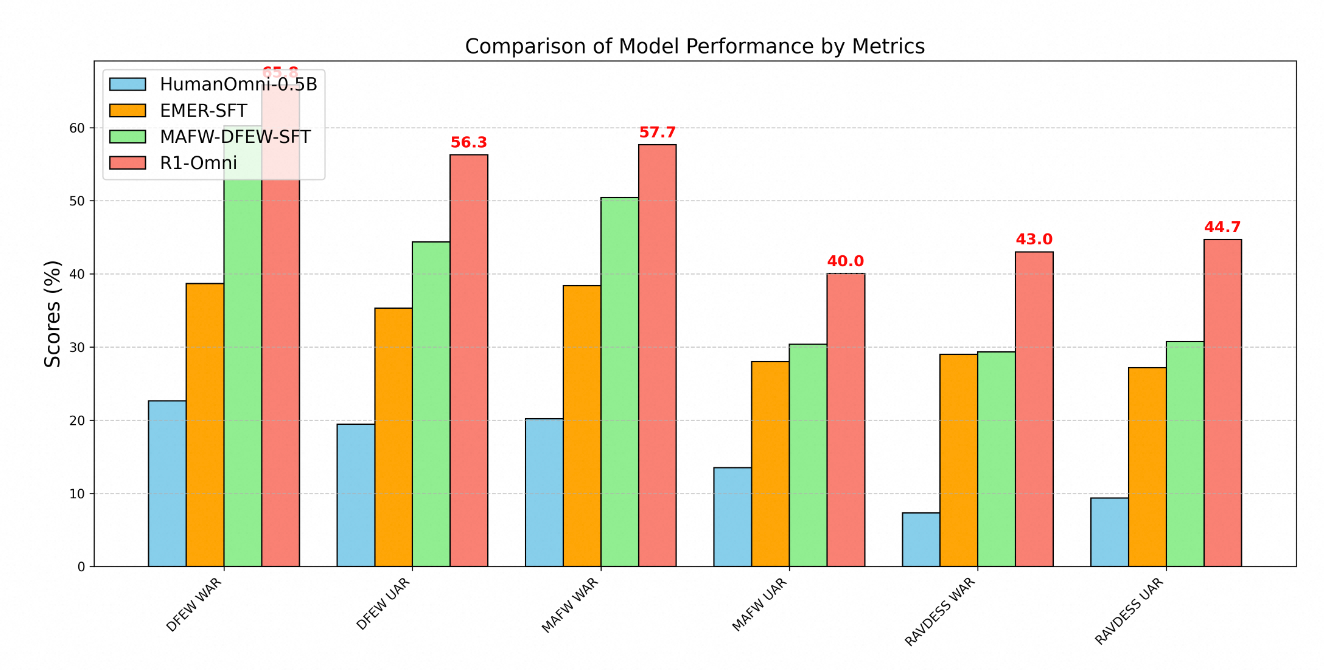
تظهر التفوق الفني لـ R1-Omni بوضوح من خلال مقاييس الأداء عبر العديد من معايير التعرف على المشاعر. يوفر الاختبار على ثلاثة مجموعات بيانات رئيسية - DFEW وMAFW وRAVDESS - تقييمًا شاملاً لقدرات النموذج على كل من البيانات ضمن النطاق وبيانات خارج النطاق.
في مجموعة بيانات DFEW، حقق R1-Omni متوسط ذكاء مرجح (WAR) بنسبة 65.83% ومتوسط ذكاء غير مرجح (UAR) بنسبة 56.27%، متفوقًا بشكل كبير على النموذج الأساسي HumanOmni-0.5B (22.64% WAR) ونموذج MAFW-DFEW-SFT (60.23% WAR) الذي تم ضبطه مباشرة على مجموعات التدريب.
ما هو أكثر دلالة هو أداء النموذج على بيانات خارج النطاق. عند اختباره على مجموعة بيانات RAVDESS، التي لم تُستخدم أثناء التدريب، حقق R1-Omni 43% WAR و44.69% UAR - أفضل بكثير من النموذج الأساسي (7.33% WAR) وبشكل أعلى بكثير من البدائل التي تم ضبطها تحت الإشراف (29.33% WAR).
منهجية التدريب
تبع تطوير R1-Omni عملية تدريب متقدمة من مرحلتين:
أولاً، في مرحلة "البداية الباردة"، بدأ الباحثون النموذج باستخدام HumanOmni-0.5B وضبطوه بدقة على مجموعة بيانات مُنظمة بعناية تتكون من 232 عينة من مجموعة بيانات التعرف على المشاعر متعددة الوسائط القابلة للتفسير و348 عينة من مجموعة بيانات HumanOmni. وقد وفر ذلك قدرات أساسية مع التأكيد على عمليات التفكير القابلة للتفسير.
استخدمت المرحلة الثانية التعلم التعزيزي مع مكافأة قابلة للتحقق باستخدام مجموعة بيانات أكبر بكثير تضم 15,306 عينة فيديو من مجموعات بيانات MAFW وDFEW. كانت هذه المرحلة التعلم التعزيزي حاسمة في تطوير قدرات التفكير والتعميم المتقدمة للنموذج.
طوال التدريب، أولت العملية الأولوية ليس فقط للتصنيف الدقيق ولكن أيضًا لتطوير مسارات تفكير قابلة للتحقق. عادةً ما تضمنت أمثلة التدريب كل من تصنيفات المشاعر وعمليات التفكير المنسقة التي تربط الملاحظات بالاستنتاجات. شجع هذا النهج النموذج على تطوير روابط قابلة للتفسير بدلاً من مجرد تعلم الارتباطات الإحصائية.
التطبيقات في العالم الحقيقي
تفتح القدرات التي يظهرها R1-Omni العديد من الاحتمالات عبر مجالات مختلفة:
- دعم الصحة النفسية: يمكن أن يساعد النموذج المعالجين من خلال تقديم تقييمات موضوعية لحالات المرضى العاطفية، مما قد يساعد في التعرف على إشارات عاطفية دقيقة قد تفوت.
- التعليم: يمكن أن تساعد أنظمة مشابهة المعلمين في قياس تفاعل الطلاب وردود فعلهم العاطفية تجاه المواد التعليمية، مما يتيح أساليب تعليمية أكثر استجابة.
- خدمة العملاء: قد تعزز تقنية R1-Omni أنظمة خدمة العملاء الآلية من خلال التعرف والتفاعل بشكل مناسب مع مشاعر العملاء، مما يحسن معدلات الرضا.
- تحليل المحتوى: يمكن أن يحلل النموذج المحتوى العاطفي في الفيديوهات والتسجيلات الصوتية لأغراض البحث السوقي، وتحليل الوسائط، ومراجعة المحتوى.
تعتبر قابلية تفسير هذا النموذج ذات قيمة خاصة في هذه السياقات، حيث تتيح للمشغلين البشريين فهم والتحقق من التفكير وراء تقييمات المشاعر التي تولدها الذكاء الاصطناعي. تعزز هذه الشفافية الثقة وتساعد في التعاون الفعال بين البشر والذكاء الاصطناعي، وهو أمر ضروري لاعتماد واسع النطاق في مجالات حساسة.
التطوير المستقبلي
وفقًا لخارطة طريق المشروع، تشمل التطورات المستقبلية لـ R1-Omni دمج كود المصدر لـ HumanOmni، وإصدار عملية إعادة إنتاج أكثر تفصيلاً، وإصدار جميع بيانات التدريب كمصدر مفتوح، وتطوير قدرات الاستدلال لبيانات الفيديو المفردة وبيانات الصوت المفردة، وإصدار نتائج من نسخة أكبر 7B من النموذج.
ستزيد هذه التحسينات المخطط لها مزيدًا من إمكانية الوصول والنفع للنموذج للباحثين والمطورين، مما قد يسرع التقدم في مجال التعرف على المشاعر متعددة الوسائط.
الختام
يمثل نموذج R1-Omni من علي بابا تقدمًا كبيرًا في التعرف على المشاعر القائم على الذكاء الاصطناعي من خلال تطبيقه المبتكر لتقنيات التعلم التعزيزي على الفهم متعدد الوسائط. من خلال تعزيز قدرات التفكير، وتحسين الدقة، وإظهار تعميم متفوق على سيناريوهات جديدة، يدفع R1-Omni حدود الممكن في الذكاء العاطفي.
مع تقدمنا نحو تفاعل أكثر طبيعية بين البشر والكمبيوتر، ستلعب أنظمة مثل R1-Omni التي يمكنها التعرف بدقة والاستجابة لمشاعر البشر عبر قنوات الاتصال المختلفة دورًا متزايد الأهمية. يركز النموذج على قابلية التفسير والتعميم، مما يتناول القيود الحرجة للنهجات السابقة، ويحدد معيارًا جديدًا لتكنولوجيا التعرف على المشاعر بشكل مسؤول وفعال.
من خلال الجمع بين مزايا التعلم التعزيزي مع قدرات المعالجة متعددة الوسائط، أنشأت علي بابا ليس فقط نظامًا محسّنًا للتعرف على المشاعر، ولكن ربما نموذجًا جديدًا لكيفية تعلم أنظمة الذكاء الاصطناعي لفهم التعقيدات الدقيقة للتواصل البشري.