A complete guide about the Open Source LLM: Mistral-7B. Mistral-7B Benchmarks, how to install Mistral-7B locally with Ollama and LM Studio, How to Use Mistral-7B for Coding, Prompt Engineering, How to Fine-tune Mistral-7B, other Mistral-7B related Models, etc.
Mistral 7B, with its 7.3 billion parameters, sets a new standard in the realm of Large Language Models (LLMs). This model has notably surpassed the performance of its 13 billion parameter counterparts in all benchmarks and competes closely with 34 billion parameter models in many aspects. It uniquely balances proficiency in code-related tasks and English language processing.
What is Mistral 7B?
Mistral 7B is a comprehensive foundation model designed for English text and code generation. It excels in various applications such as text summarization, classification, text completion, and code completion.
Developed by the French company Mistral AI, this Open Source LLM model stands out for its versatility, effectively catering to both text-based and coding needs.
Mistral 7B excels in benchmarks, outperforming similar-sized models.
Equally adept at code-related tasks and general English language tasks.
Grouped-query attention enables fast inference without sacrificing quality, making it highly efficient.
Mistral 7B is available for use and can be tested through API calls, reflecting its user-friendly nature and wide accessibility.
Why Is Mistral 7B So Good?
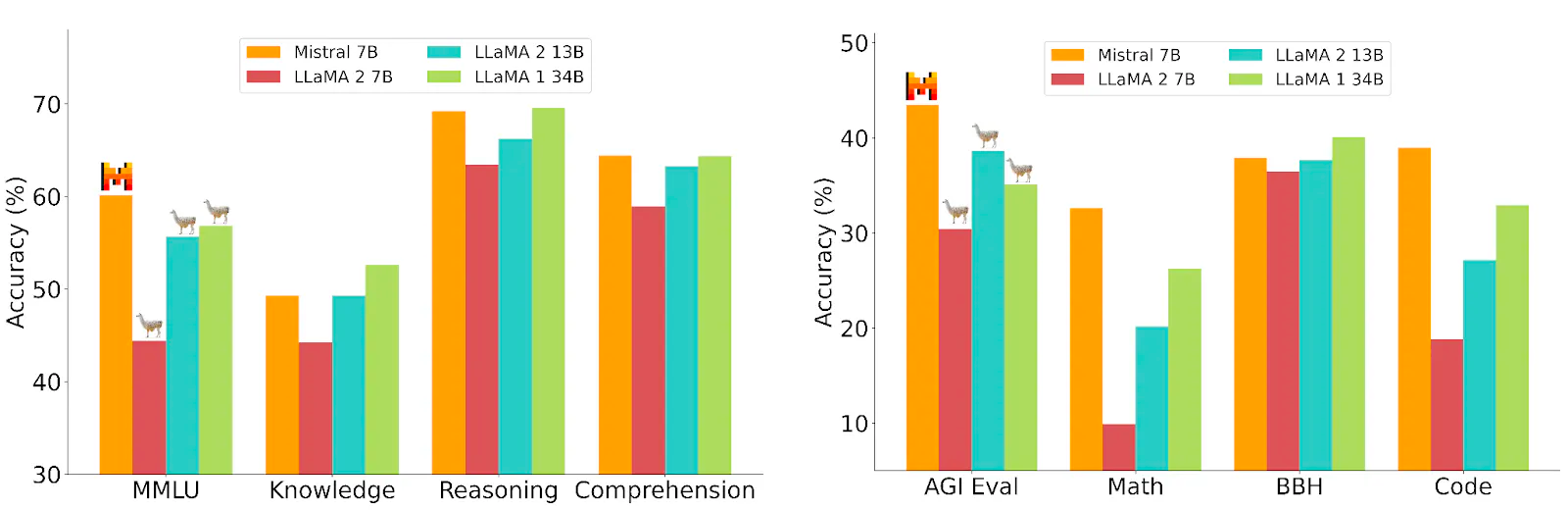
Mistral-7B Benchmarks
The following table presents a comparative analysis of benchmark performances between Mistral 7B and other leading LLMs such as LLaMA 2 13B, LLaMA 2 7B, and LLaMA 1 34B across various NLP tasks:
Task
Mistral 7B
LLaMA 2 13B
LLaMA 2 7B
LLaMA 1 34B
MMLU
60%
55%
52%
65%
Knowledge
58%
53%
50%
63%
Reasoning
64%
58%
55%
68%
Comprehension
70%
65%
62%
73%
AGI Eval
45%
40%
37%
48%
Math
40%
35%
32%
43%
BBH (Benchmark)
50%
45%
42%
53%
Code
35%
30%
28%
38%
The data reveals that Mistral 7B demonstrates commendable accuracy, frequently outperforming LLaMA 2 13B and LLaMA 2 7B models. It showcases Mistral 7B's robustness in tasks that involve complex reasoning and comprehension, while also maintaining competitive performance in specialized areas such as mathematics and coding.
Highlights:
Efficiency: For potential users who have limited computational resources, Mistral 7B offers a more efficient yet powerful option, allowing access to state-of-the-art AI capabilities without the need for extensive infrastructure.
Specialization: Mistral 7B's strong performance in comprehension and reasoning tasks makes it a suitable choice for applications requiring advanced understanding, such as legal or technical document analysis.
Accessibility: The performance of Mistral 7B, coupled with its open-source nature, allows for a broader range of developers and researchers to experiment with and deploy advanced LLM solutions.
Grouped-query Attention (GQA): GQA is a novel attention mechanism implemented within Mistral 7B, designed to enhance inference speed. This is achieved by grouping queries to reduce the computational load during the attention process, which is particularly beneficial in tasks requiring real-time responses.
Sliding Window Attention (SWA): The SWA technique enables Mistral 7B to process extensive text sequences more effectively by managing the computational burden through a sliding window, thus maintaining high performance even with longer input sequences.
Ollama is a user-friendly tool designed to simplify running Large Language Models (LLMs) like Mistral 7B on local machines. It allows users to leverage the capabilities of advanced LLMs without requiring specialized hardware or extensive setup procedures.
How to Install Ollama
Download Ollama:
Go to the Ollama website to download the tool. Choose the appropriate version for your operating system (currently available for macOS and Linux).
Installation for macOS Users:
After downloading, move Ollama to the Applications folder. This step is necessary for macOS users to successfully complete the installation.
Install Command Line Tool:
Install the command line tool for Ollama by following the instructions within the application. This step is crucial for running LLMs through your terminal.
Installing and Running Mistral 7B with Ollama
Deploy Mistral 7B:
Open your terminal and run the following command to install Mistral 7B:
ollama run mistral
This command will initiate the download of Mistral 7B, which is approximately 4.1GB in size.
Running the Model:
After the download is complete, Mistral 7B will be installed on your machine, and you can start interacting with it directly from your terminal.
You can use Mistral 7B for various tasks, such as text completion or instruction-based models. For text completion, use the command:
ollama run mistral --task text-completion
For instruction-based models, use:
ollama run mistralai/mistral-7b-instruct
Advantages of Using Ollama
Running Mistral 7B locally with Ollama offers several benefits:
Privacy and Security: Your data doesn’t leave your machine, ensuring a higher degree of privacy.
Flexibility: Customize the model according to your needs and use it without relying on third-party APIs or cloud services.
Ease of Use: Ollama simplifies the process of deploying LLMs, making it accessible even to those with limited technical expertise.
Which Mistral 7B Shall I Choose?
If you visited the ollama webpage, you might be confused by the Mistral 7B models availalbe. they have various versions tailored for different purposes.
Let's break down the common options. More specifically:
Mistral-7b-instruct:
Tailored for conversation and question-answering tasks.
Ideal for specific instructions or detailed responses.
Mistral-7b-text:
A general-purpose version for a broad range of text generation tasks.
The versions with 'q3', 'q4', 'q5', and 'q6' indicate different levels of quantization, which affects the balance between performance and computational efficiency.
Quantization Versions (q3, q4, q5, q6):
Indicate the level of quantization, balancing performance and efficiency.
Examples: 7b-instruct-q3_K_S, 7b-instruct-q4_K_M, etc.
Context Length Variations (K_S, K_M, K_L):
'K' refers to the context length.
'S', 'M', and 'L' stand for small, medium, and large sizes, respectively.
Recommended Choice:
q4_K_M is often a good balance between performance and computational efficiency, suitable for most applications. Of course, for the best result you should go for q6.
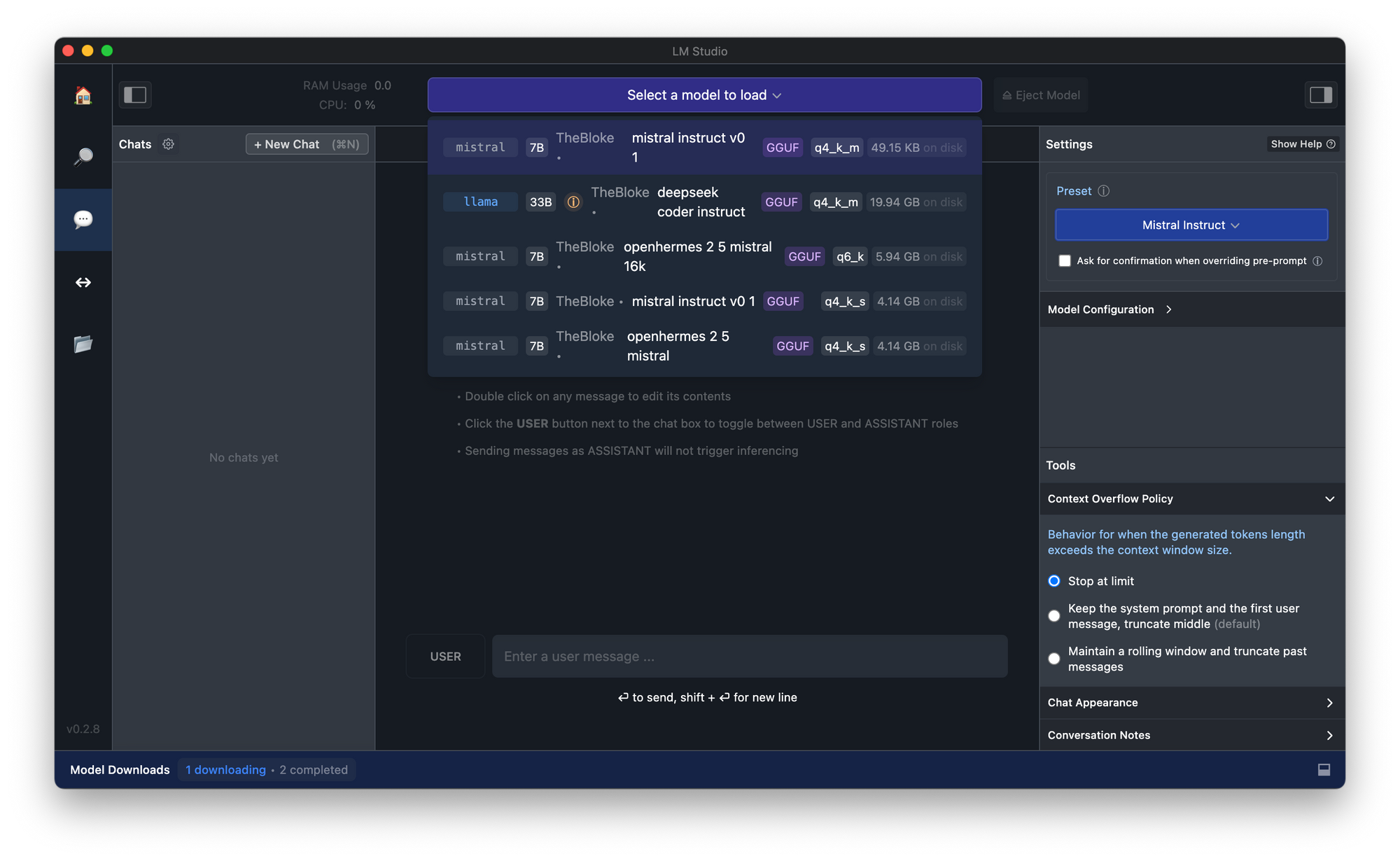
Option 2. Run Mistral 7B Locally Using LM Studio
LM Studio provides a user-friendly environment for running various AI models, including Mistral 7B, on your local machine. Here's a comprehensive guide to get you started.
Step 1: Download and Install LM Studio
You can download LM Studio from its official website. Select the version compatible with your operating system (Windows, macOS, or Linux).
Next, Run the downloaded installer and follow the on-screen instructions to complete the installation.
Step 2: Set Up Your Machine
Check System Requirements:
Ensure your computer meets the minimum requirements, particularly for RAM and CPU.
LM Studio requires your CPU to support AVX2. Verify this via your system settings or use tools like CPU-Z (Windows) or iStat Menus (macOS).
Update System Path (Optional):
For ease of access, you may add LM Studio to your system's PATH environment variable.
Step 3: Launch LM Studio and Download Mistral 7B
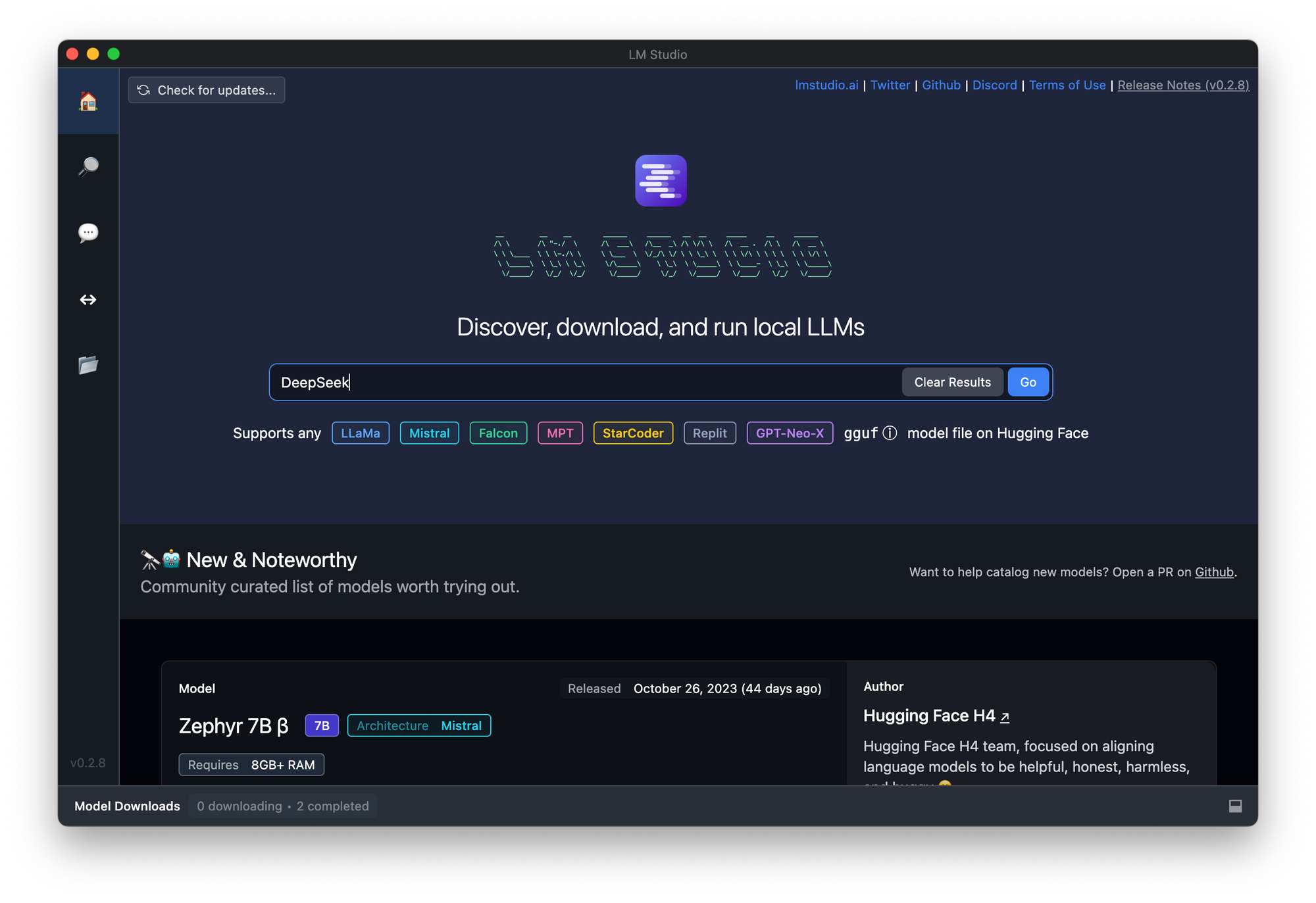
Open LM Studio:
Launch the LM Studio application from your Applications folder (macOS) or Start Menu (Windows).
Download Mistral 7B:
In LM Studio, navigate to the AI models section.
Search for "Mistral 7B" and select the model.
Click on the download button to start downloading the model to your local machine.
Step 4: Configure Mistral 7B
Model Configuration:
Once downloaded, you can configure Mistral 7B settings. This might include setting the maximum token length, enabling GPU acceleration, and adjusting other model-specific parameters.
Save Configuration:
After adjusting the settings, save your configuration to ensure the changes are applied.
Step 5: Run the Model
Start the Model:
Select Mistral 7B from the list of downloaded models.
Click on the 'Run' button to start the model.
Verify Model is Running:
Once the model is running, LM Studio will display its status. You can now start using Mistral 7B for your tasks.
Note: You Might encounter error such as "Failed to Load Model ... gguf" on M1/M2 Mac. To resolve the issue, update Your Mac OSX to the latest version ( Sonoma).
Step 6: Using Mistral 7B
Interact with the Model:
Use the built-in chat interface to send prompts to Mistral 7B and receive responses.
You can also use the API endpoint provided by LM Studio to interact with the model programmatically.
Step 7: Advanced Features (Optional)
Custom Applications:
For more advanced usage, consider integrating Mistral 7B into custom applications or services using the provided API.
Further Customization:
Explore additional settings and customization options within LM Studio to optimize the model's performance based on your specific use case.
Tips for Running Mistral 7B with LM Studio
Performance Optimization: For better performance, consider running LM Studio on high-speed storage devices like an SSD or M2 drive.
Memory Management: Larger models may require more RAM. Ensure you have sufficient memory available, especially when running complex tasks.
Community Support: For additional help and community support, visit LM Studio's user forums or help sections.
Option 3. Run Mistral 7B with Docker
Docker provides a convenient and efficient way to run Mistral 7B, especially on GPU-enabled hosts. This method ensures consistent environment setup and easy deployment. Here's a detailed guide to set up and run Mistral 7B using Docker:
1. Pulling the Docker Image:The first step is to pull the Docker image that contains everything required to run Mistral 7B, including a fast Python inference server (vLLM).
2. Running the Model using Docker:After pulling the image, run the model using Docker. This step requires specifying the Hugging Face token and setting up the appropriate ports.
docker run --gpus all \
-e HF_TOKEN=$HF_TOKEN -p 8000:8000 \
ghcr.io/mistralai/harmattan/vllm-public:latest \
--host 0.0.0.0 \
--model mistralai/Mistral-7B-v0.1
Note: Replace $HF_TOKEN with your Hugging Face user access token.
Option 4. Run Mistral 7B with vLLM
For direct deployment of Mistral 7B, especially on systems with CUDA 11.8 and GPU support, vLLM can be a robust solution. Here’s how to install and run Mistral 7B using vLLM:
1. Installation:Install vLLM using Python's pip package manager. This will download and install the vLLM package and its dependencies.
pip install vllm
2. Login to Hugging Face Hub:Before using Mistral 7B, authenticate with the Hugging Face Hub to access the model:
huggingface-cli login
Follow the prompts to enter your Hugging Face credentials.
3. Starting the Server:Once vLLM is installed and you’re logged in to Hugging Face, you can start the server. This will initialize Mistral 7B for inference.
This setup provides a streamlined approach for deploying Mistral 7B, especially in environments where Docker and GPU resources are available. By encapsulating the model within a Docker container or using vLLM, developers can leverage Mistral 7B's capabilities with greater ease and flexibility.
How to Use Mistral-7B for Coding
Setting Up Mistral 7B for Code Generation:
Platform Selection: Utilize Fireworks.ai for accessing the Mistral 7B model. This platform provides a conducive environment for code generation.
Configuration: Adjust the max_length setting to 250 on Fireworks.ai. This ensures comprehensive and detailed code outputs.
Prompt Engineering for Optimal Code Generation:
Structured Prompting: Use [INST] Instruction [/INST] format for clear and structured commands.
Example Prompt for Python Function:
Request: "Create a Python function to convert Celsius to Fahrenheit."
This code snippet demonstrates Mistral 7B's ability to understand and generate practical code solutions.
Tips for Effective Usage:
Experiment with different prompt structures to discover the model's capabilities.
Understand the model's strengths and limitations for better output quality.
Regularly update your approach based on the model's performance and output.
Mistral 7B's code generation capabilities, when combined with effective prompt engineering, can be a significant asset for a variety of programming tasks. Its ability to understand complex instructions and generate accurate code makes it a powerful tool for developers and coders.
Prompt Engineering for Mistral-7B
Structured Instructional Prompts:
Utilize <s>[INST] Instruction [/INST] format for clear directions.
Example for JSON Creation:
[INST] Create a JSON object for a person with the following details: Name - John, Lastname - Smith, Address - #1 Samuel St. [/INST]
Handling Complex Tasks:
Use follow-up instructions within prompts for multi-step tasks.
Example for Extended JSON Task:
<s>[INST] Now, add the person's contact details to the same JSON object. Phone: 123-456-7890, Email: john.smith@example.com [/INST]</s>
Mitigating Prompt Injections:
Mistral 7B may produce unexpected outputs when faced with prompt injections.
Construct prompts carefully to guide the model accurately and avoid manipulative inputs.
Example of Handling Prompt Injection:
[INST] Translate the following text from English to French, keeping the meaning intact: "Happy to help with your project." [/INST]
In this example, any attempt to deviate the translation is mitigated by the specific instruction.
Multi-Turn Conversational Contexts:
Engage in a conversational style with Mistral 7B for dynamic interactions.
Example for Conversational Prompt:
<s>[INST] As an assistant, suggest three tourist attractions in Paris. [/INST] "The Eiffel Tower is a must-see. What about historical museums?"</s> [INST] List two historical museums in Paris. [/INST]
Prompt Engineering for Code Generation:
When generating code, specify the programming language and desired output.
Example for Python Code Generation:
[INST] Write a Python function to calculate the area of a circle given its radius. Include comments for clarity. [/INST]
Crafting effective prompts for Mistral 7B requires a blend of clarity, structure, and foresight to guide the model towards desired outputs. By understanding the nuances of instructional prompts and conversational contexts, users can leverage Mistral 7B's capabilities for a wide range of applications, from data processing to dynamic code generation.
How to Fine-tune Mistral 7B
Fine-tuning Mistral 7B requires a hands-on approach, integrating both practical steps and a solid understanding of the model's architecture. Below is a more practical guide, with executable sample codes, to fine-tune Mistral 7B for your specific NLP tasks.
Preparing the Environment for Mistral-7B
Before you begin fine-tuning, ensure you have a suitable environment set up. This includes access to a GPU with adequate memory, as Mistral 7B is a large model, and having the necessary libraries installed.
# Install the required libraries
pip install transformers datasets torch
Loading the Dataset for Mistral-7B
Choose a dataset that closely aligns with the problem you're aiming to solve. Here's how you can load and preprocess your dataset:
from datasets import load_dataset
# Load your dataset
dataset = load_dataset('your_dataset_name')
# Preprocess the dataset
def preprocess_function(examples):
return tokenizer(examples['text'], truncation=True, padding='max_length', max_length=512)
tokenized_dataset = dataset.map(preprocess_function, batched=True)
Fine-Tuning Mistral 7B
With your environment and dataset prepared, you can begin fine-tuning Mistral 7B.
from transformers import AutoModelForCausalLM, AutoTokenizer, Trainer, TrainingArguments
model_name = 'mistralai/Mistral-7B-v0.1'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Define training arguments
training_args = TrainingArguments(
output_dir='./results', # output directory for model checkpoints
num_train_epochs=3, # number of training epochs
per_device_train_batch_size=4, # batch size per device during training
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01 # strength of weight decay
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset['train'],
eval_dataset=tokenized_dataset['test']
)
# Start fine-tuning
trainer.train()
Evaluating the Fine-Tuned Mistral-7B Model
After fine-tuning, evaluate the performance of the model using the validation set to ensure it has learned the desired task.
from datasets import load_metric
metric = load_metric('accuracy')
# Evaluate the model
eval_results = trainer.evaluate()
print(f"Accuracy: {eval_results['eval_accuracy']:.2f}")
Deploy Mistral-7B
Once you're satisfied with the fine-tuned model's performance, you can deploy it for inference.
# Save the fine-tuned model
model.save_pretrained('./fine_tuned_mistral_7B')
# Load the fine-tuned model for inference
model = AutoModelForCausalLM.from_pretrained('./fine_tuned_mistral_7B')
This practical guide aims to provide you with the tools and knowledge necessary to fine-tune Mistral 7B on your data, enabling you to enhance its capabilities for your specific NLP applications.
Conclusion: Embracing the Potential of Mistral 7B
In conclusion, Mistral 7B is not just an achievement in AI; it represents a shift in the paradigm of language model development. It encourages the field to move towards sustainable models without compromising the quality of outcomes. For developers, researchers, and organizations, Mistral 7B offers a versatile tool capable of enhancing a myriad of applications, from automated content generation to sophisticated data analysis.
As the AI community continues to evolve, models like Mistral 7B will likely play a pivotal role in shaping the future of technology, offering insights and solutions to complex problems. By participating in its development and application, we all contribute to the vast tapestry of innovation that will define the next era of AI.