With the rapid rise of AI, the need for powerful, scalable models has become essential for businesses of all sizes. Meta’s Llama 3.2 API offers one of the most efficient and adaptable language models on the market, featuring both text-only and multimodal capabilities (text and vision). Whether you’re building conversational agents, data processing systems, or multimodal applications, the Llama 3.2 API delivers top-notch performance. However, understanding the pricing structure is critical to maximizing value for your specific use case.
In this article, we’ll break down the Llama 3.2 API pricing model, provide regional examples, and offer insights into token consumption for specific inputs and outputs.
Special Note: Llama 3.2 on Anakin.ai: Unlock AI Potential with Flexible Access
At Anakin.ai, we are proud to support Llama 3.2, offering users seamless access to Meta’s powerful AI models directly through our platform. Whether you need the lightweight, text-only versions for small-scale applications or the multimodal vision models for more complex tasks, Anakin.ai provides a flexible and user-friendly interface to get started with Llama 3.2.
With Anakin.ai, you can:
Access Llama 3.2 models instantly, including the 1B, 3B, 8B, and 90B versions.
Seamless Integration: Our platform allows you to easily integrate Llama 3.2 into your applications for tasks ranging from text summarization to image captioning and visual reasoning.
Scalable Usage: We offer scalable API endpoints with support for high-volume requests, ensuring that both small projects and enterprise-scale deployments are covered.
By using Anakin.ai, you can explore the power of Llama 3.2 with a reliable, cost-effective solution. Try Llama 3.2 on Anakin.ai today.
Llama 3.2 API Pricing Overview

The Llama 3.2 API pricing is designed around token usage. Tokens represent pieces of words, typically between 1 to 4 characters in English. Pricing is divided into input tokens and output tokens, with different rates applied depending on the model size and the region in which you are operating.
- Input Tokens are the tokens you send to the model in a request.
- Output Tokens are the tokens generated by the model in response to your request.
Meta and its partners provide pricing in terms of USD per million tokens. The pricing structure is different across Llama models, based on their sizes and capabilities.
Here is the pricing breakdown for some of the models:
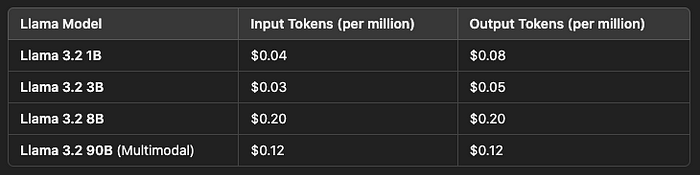
For businesses looking to integrate Llama 3.2 into their applications, this flexible pricing model makes it scalable for small-scale and large enterprise applications alike.
Regional Pricing Variations
API pricing can vary by region, primarily due to infrastructure costs, data centers, and operational overhead. Providers such as Together AI and Amazon Bedrock offer the Llama 3.2 API with region-specific pricing.
Here are some examples of regional pricing:
Together AI Pricing:
Llama 3.2 Turbo (3B):
- Input & Output Tokens: $0.06 per million tokens
Llama 3.2 Reference (8B):
- Input & Output Tokens: $0.20 per million tokens
- Region: North America, Europe, Asia-Pacific
Amazon Bedrock Pricing:
- Llama 3.2 API models are available in multiple AWS regions. Pricing may fluctuate depending on the region, with cross-region inference potentially affecting latency and cost.
- AWS US East: Standard pricing applies.
- AWS EU West: Pricing may include additional charges due to higher infrastructure costs.
While the token pricing for Llama models generally remains within a similar range, regional costs can vary due to infrastructure investments and other factors such as data residency requirements.
Provider-Specific Features
Different cloud providers and API platforms offer Llama 3.2 with unique features that go beyond basic token pricing. These additional services can impact your cost, but they also offer valuable benefits such as scalability and lower latency.
Together AI:
- Scalability: Together AI supports up to 9,000 requests per minute and 5 million tokens per minute for large language models.
- Flexible Usage: No daily rate limits, making it ideal for high-throughput applications such as chatbots or AI-powered customer service.
Amazon Bedrock:
- Cross-Region Inference: Bedrock allows developers to run Llama models across different AWS regions, enabling global scalability.
- Enterprise Integration: Llama models on AWS can be easily integrated into existing cloud-based applications, with tools for fine-tuning and customized deployment.
Providers may also offer additional services such as enhanced security, custom SLAs (Service Level Agreements), and dedicated endpoints for enterprise clients.
Token Consumption Examples
To better understand how Llama 3.2 API pricing works, let’s explore a few token consumption examples. This can help illustrate how much you can expect to spend based on input/output token usage in various applications.
Example 1: Text Summarization

- Input Text Length: 1,500 words (~6,000 tokens)
- Output Summary Length: 250 words (~1,000 tokens)
For this task:
- Input token cost: 6,000 tokens / 1,000,000 tokens * $0.03 = $0.018
- Output token cost: 1,000 tokens / 1,000,000 tokens * $0.05 = $0.005
- Total cost: $0.018 (input) + $0.005 (output) = $0.023
Example 2: Real-Time Chatbot

- User Input (chat): 100 words (~400 tokens)
- AI Response: 120 words (~480 tokens)
For each interaction:
- Input token cost: 400 tokens / 1,000,000 tokens * $0.03 = $0.000012
- Output token cost: 480 tokens / 1,000,000 tokens * $0.05 = $0.000024
- Total cost per interaction: $0.000012 + $0.000024 = $0.000036
For 100,000 chatbot interactions, the cost would be:
- Input cost: $0.000012 * 100,000 = $1.2
- Output cost: $0.000024 * 100,000 = $2.4
- Total cost: $1.2 + $2.4 = $3.6
Example 3: Multimodal Image Captioning
- Image Analysis Input: 5 images (~20,000 tokens)
- Text Output (captions): 5 captions (~1,000 tokens each)
For this multimodal task:
- Input token cost: 20,000 tokens / 1,000,000 tokens * $0.06 = $0.012
- Output token cost: 5,000 tokens / 1,000,000 tokens * $0.08 = $0.04
- Total cost: $0.012 (input) + $0.04 (output) = $0.052
For an application processing 10,000 images per month:
- Total cost: $0.052 * 10,000 = $520
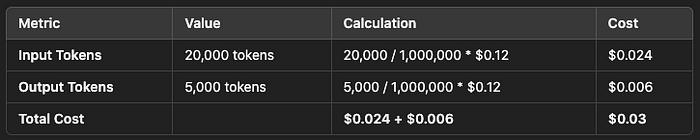
Example 4: Multimodal Integration with Llama 3.2 90B

Image and Text Processing Input: 5 images + related text (~20,000 tokens)
Text Output (captions): 5 captions (~1,000 tokens each)
For this multimodal task:
- Input token cost: 20,000 tokens / 1,000,000 tokens * $0.12 = $0.024
- Output token cost: 5,000 tokens / 1,000,000 tokens * $0.12 = $0.006
- Total cost: $0.024 (input) + $0.006 (output) = $0.03
For an application processing 10,000 batches per month:
- Total cost: $0.03 * 10,000 = $300
Enterprise and Bulk Pricing Options
Large enterprises or businesses looking for long-term, high-volume usage can negotiate custom pricing models with Meta or third-party providers. These agreements often offer discounted rates, dedicated infrastructure, or enhanced support packages.
For example, a company processing 10 million tokens daily could negotiate a custom rate to reduce costs, especially when using large models like the Llama 3.2 Reference (8B) model or the Llama 3.2 90B multimodal model for vision tasks. Discover more about enterprise pricing for Llama models here.
Free Tier and Credits
Many providers offer free tiers or initial credits to encourage developers to experiment with the Llama 3.2 API. For example:
- Together AI provides a free usage tier, allowing developers to test the model for a limited number of tokens before transitioning to paid services.
- AWS offers credits to new users, which can be applied toward running Llama 3.2 models on Amazon Bedrock.
These free tiers are a great way for small businesses or developers to test Llama 3.2’s performance before committing to a larger budget. Learn more about available free tiers.
Multimodal Capabilities and Token Pricing
It’s important to note that multimodal models (like those supporting both text and vision) tend to have slightly higher pricing compared to text-only models. This is due to the increased computational complexity involved in image recognition and visual reasoning tasks.
For instance, the Llama 3.2 90B multimodal model might cost:
- Input & Output tokens: $0.12 per million tokens (region-specific)
This pricing is still competitive compared to other multimodal models like GPT-4’s multimodal capabilities, which are often priced higher due to closed-access APIs and limited fine-tuning options. Learn more about the pricing differences.
Conclusion
Understanding Llama 3.2 API pricing allows developers to effectively budget for AI projects based on token usage. Whether you are running small applications or large-scale multimodal systems, Llama 3.2 offers flexible and competitive pricing. Key considerations include the region where the API is hosted, the token requirements of your specific use case, and whether you need text-only or multimodal processing.
For small applications, Llama 3.2’s 1B and 3B models provide an affordable entry point. Enterprises, on the other hand, may benefit from custom pricing deals for larger models like the 8B or 90B.
By considering these factors, businesses can better optimize costs while leveraging the full power of Llama 3.2 for various AI-driven applications. Explore more about Llama’s API pricing.
How to Use Llama 3.2 with Anakin AI: Step-by-Step Guide
Now that you know what Llama 3.2 is capable of, let’s dive into how and where you can use it. Follow these steps to get started with Llama 3.2 on Anakin AI:
Step 1: Visit Anakin AI
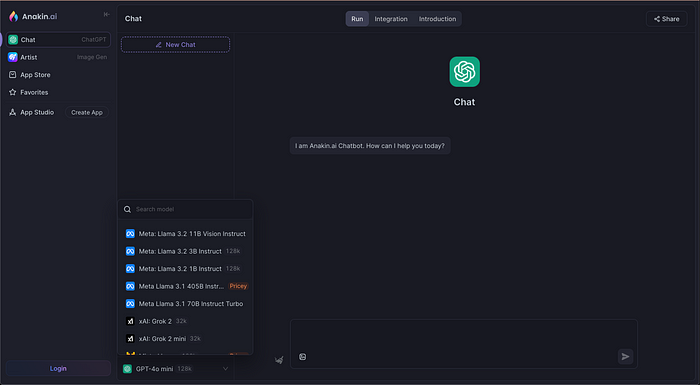
First, go to Anakin AI’s chat platform. This is where you’ll be able to access Meta’s Llama 3.2 alongside other leading AI models.
Step 2: Create an Account
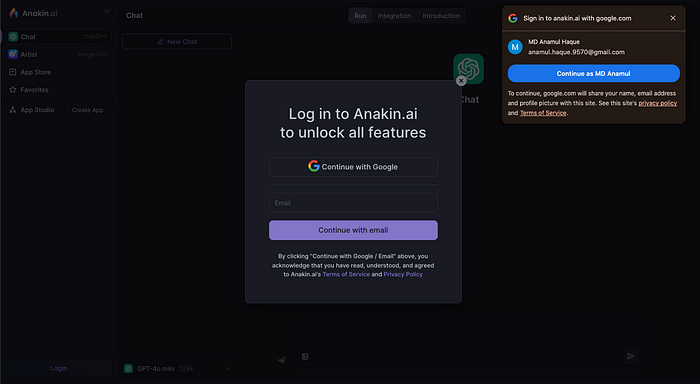
If you haven’t already, you’ll need to sign up for an account. The sign-up process is quick, requiring just an email and a password. Once you’re in, you’ll have access to all the AI models on the platform.
Step 3: Choose Your AI Model

From the model selection panel, you’ll see a list of available models such as ChatGPT, Gemini, Claude, and of course, Llama 3.2. The models come in different variants, like Llama 3.2 Vision Instruct or Llama 3.2 Turbo Instruct, depending on the complexity of your project.