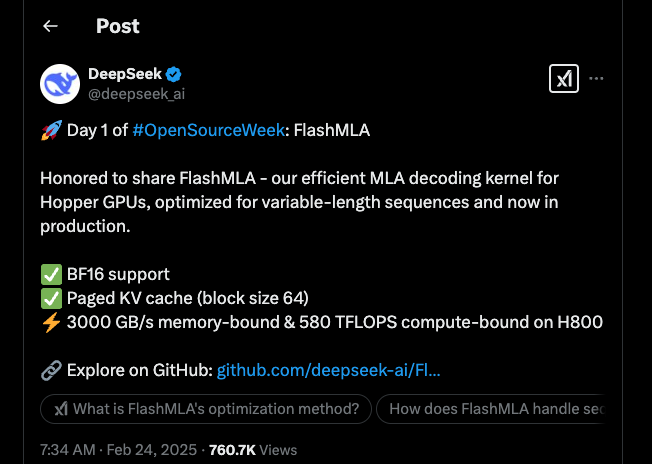
DeepSeek has kicked off their Open Source Week with a bang, unveiling FlashMLA — a cutting-edge MLA decoding kernel built for NVIDIA’s Hopper GPUs. This announcement has got the tech community buzzing, and folks are eager to dive into what this update means for AI processing.
Looking to harness the power of AI for seamless video creation and editing? Anakin AI is your go-to platform! With a comprehensive suite of cutting-edge AI video generators — including Runway ML, Minimax Video 01, Tencent Hunyuan Video, and more — you can effortlessly bring your creative vision to life. Whether you’re transforming scenes, generating cinematic sequences, or refining edits with advanced AI models, Anakin AI has everything you need.
🚀 Start creating today! Explore the AI video tools here: Anakin AI Video Generation
What is FlashMLA?

FlashMLA is a specialized kernel designed to accelerate the decoding process for Multi-head Latent Attention (MLA). In plain terms, it helps AI models handle variable-length sequences more efficiently. Whether you’re into natural language processing or other AI tasks, this tool is set to make a big splash.
Key Features and Performance
BF16 Support
One of the standout features of FlashMLA is its support for BF16 (Brain Float 16) precision. By using BF16, the kernel reduces memory usage without sacrificing the accuracy that large-scale AI models demand. Users have been singing its praises, noting that it’s a real game-changer in handling heavy-duty computations.
Paged KV Cache
Another cool aspect is the paged key-value cache, which comes with a block size of 64. This setup efficiently manages memory and helps boost inference performance. It’s like having a well-organized toolbox where every tool is exactly where you need it.
Impressive Metrics
Performance-wise, FlashMLA doesn’t disappoint. On the H800 SXM5 GPU, it clocks in at a staggering 3000 GB/s in memory-bound scenarios and pushes up to 580 TFLOPS when the task is compute-bound. These numbers aren’t just impressive — they’re a testament to the incredible engineering behind the kernel.
How FlashMLA Stands Out
FlashMLA takes inspiration from well-known projects like FlashAttention and NVIDIA’s CUTLASS. It’s been built with a focus on efficiency and production readiness, ensuring that developers can integrate it seamlessly into their workflows. Folks in the community have been quick to remark that this is a must-have tool for anyone serious about pushing the limits of AI performance.
Integration and Setup
For those keen to get started, the installation is as easy as pie. With a Hopper GPU, CUDA 12.3 or higher, and PyTorch 2.0 or above, you can install FlashMLA using a simple command:python setup.py install
Once installed, you can run benchmarks with:python tests/test_flash_mla.py
This straightforward process has been a hit among developers, many of whom are already sharing glowing testimonials about how FlashMLA is reshaping their projects.
The Bigger Picture
DeepSeek’s release of FlashMLA marks the beginning of an exciting week of open-source innovation. The company isn’t just stopping here — they’re inviting developers from all over the world to collaborate and build on this new technology. As AI continues to evolve, tools like FlashMLA play a crucial role in making advanced AI more accessible and efficient.
Developers and tech enthusiasts alike are keeping a close eye on this project. With FlashMLA, DeepSeek has demonstrated a clear commitment to pushing the envelope, and this announcement is just the tip of the iceberg during Open Source Week.
Final Thoughts
DeepSeek’s introduction of FlashMLA has everyone talking. With its robust support for BF16, an innovative paged KV cache, and exceptional performance metrics, it’s clear that this tool is set to redefine efficiency in AI processing. If you’re in the AI game, now’s the time to explore what FlashMLA can do for you. Keep an eye out for more updates as DeepSeek continues to roll out exciting new features throughout Open Source Week.