Generative AIは、機械に現実的な画像やビデオ、さらにはテキストを生成する能力を与えることで、コンピュータビジョンの分野を革新しました。Generative AIで使用されるさまざまな技術の中でも、Generative Adversarial Networks(GAN)は広く人気があり成功していますが、新たな競争相手が登場しました:Stable Diffusionです。本ブログ記事では、GANとStable Diffusionの戦いについて探求し、それぞれの長所と短所を比較し、Anakin AIのStable Diffusion Image Generatorを使用したStable Diffusionの力を紹介します。
記事の要約
Autoencoders、GAN(Generative Adversarial Networks)、Diffusion Modelsなど、利用可能なGenerative Modelsの比較を行います。
Stable Diffusion Modelsは一般的な使用において特にクリエイティブなアートにおいて人気があります。
GANはリアルなタイムラプス映像の場合により有用です。
Generative Modelsとは
Generative Modelsは、トレーニングデータに似た新しいサンプルを生成する能力を持つディープラーニングモデルです。これらのモデルはトレーニングデータの基礎となる分布を学習し、観測されたデータに似た新しいサンプルを生成できます。これらは、現実的な画像の生成から新しい音楽作曲まで、さまざまなアプリケーションで使用されています。
Generative AIの歴史
Generative AIはその創設以来、大きく進化してきました。初期のGenerative Modelsの開発は高品質な画像の生成能力に制限がありました。しかし、ディープラーニングとコンピュータの処理能力の進歩により、非常にリアルな画像やビデオ、テキストを生成できるようになったより洗練されたモデルが登場しました。
Generative AIのテキストから画像への進化
Generative AIの大きな飛躍の1つは、テキストから画像への変換モデルの開発です。これらのモデルはテキストの記述に基づいて画像を生成し、テキストをビジュアルに直接変換することができます。このイノベーションは広告、ゲーム、デジタルアートなどのクリエイティブな産業に大きな影響を与えています。
画像生成モデルの比較
初期の画像生成モデルでは、モード崩壊、多様性の欠如、トレーニングの困難など、いくつかの技術的な課題がありました。研究者や開発者はこれらの制限を克服するために努力しており、高品質かつ多様性に富んだ画像を生成できる改良モデルや技術が開発されています。
Autoencoders
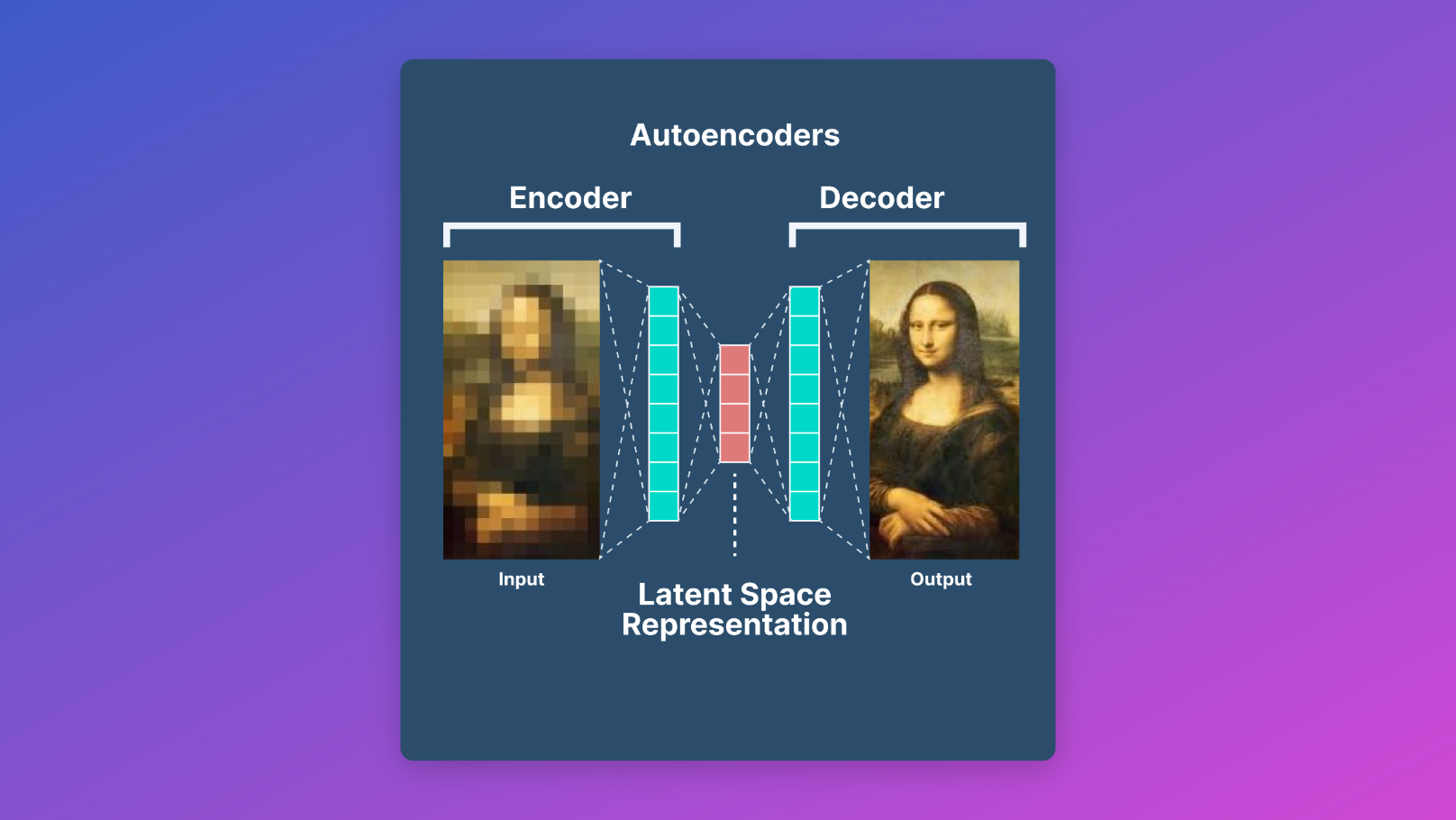
Autoencodersは、データのエンコードとデコードを学習するGenerative Modelsの一種です。画像生成のタスクに広く使用され、Generative AIの発展に重要な役割を果たしています。Autoencodersには独自の利点がありますが、他のGenerative Modelsと比較していくつかの制限もあります。
GAN(Generative Adversarial Networks)
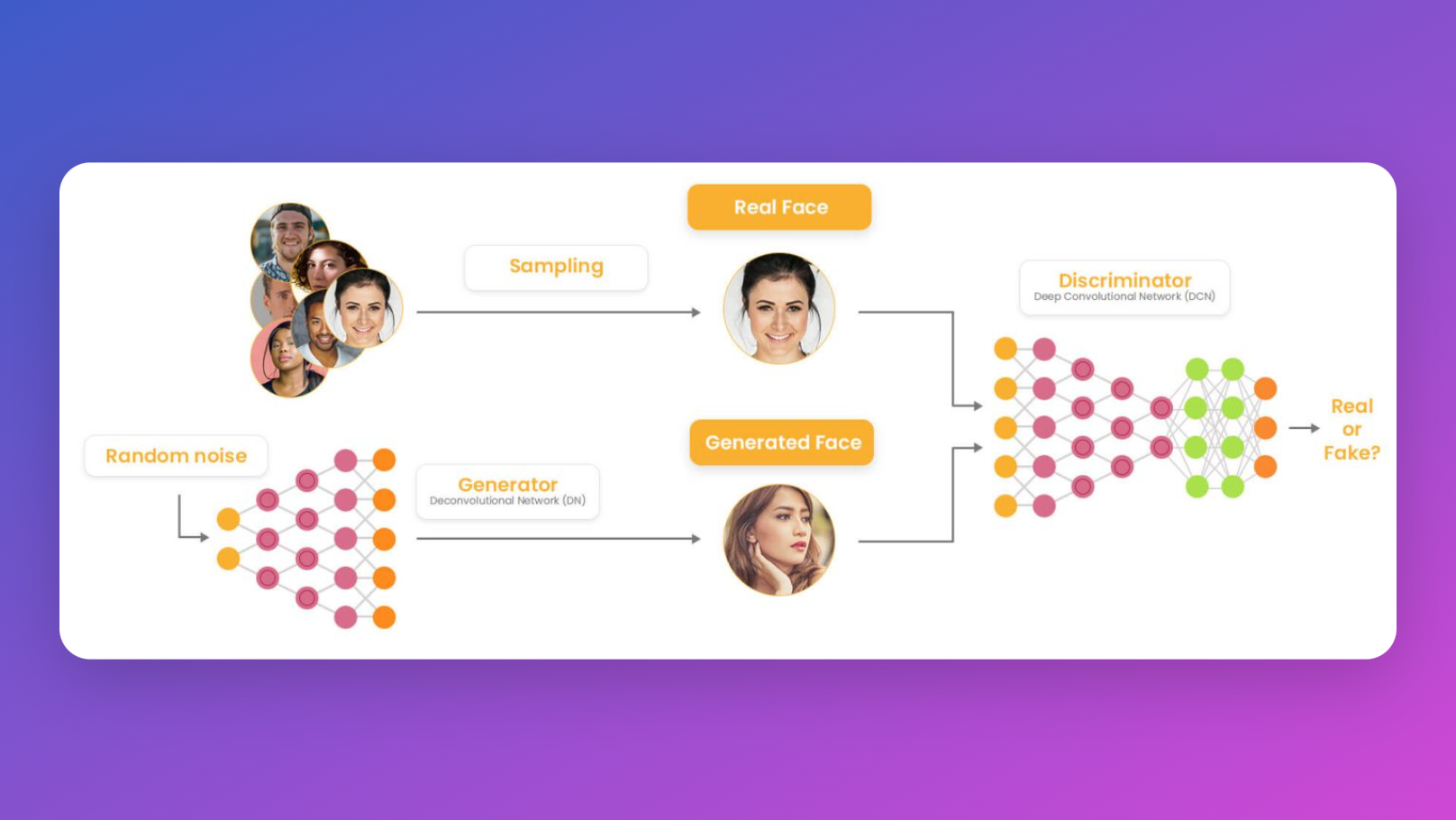
GANは、コンピュータビジョンの分野で最もよく知られ、広く使用されているGenerative Modelsの1つです。GANは、ジェネレータとディスクリミネータの2つの主要なコンポーネントで構成されています。ジェネレータはリアリスティックな画像を生成し、ディスクリミネータは実際の画像と生成された画像を識別しようとします。GANは、高品質な画像を生成するのに非常に成功していますが、それには独自の制限もあります。
Diffusion Models

Diffusion Modelsは、比較的新しいGenerative AIの手法ですが、その独自のアプローチで注目されています。GANとは異なり、Diffusion Modelsはランダムなノイズ入力を反復的に洗練することで画像を生成します。この反復的なプロセスにより、驚くほど詳細かつ現実的な画像を生成することができます。
Stable Diffusion vs GAN:詳細な比較
それでは、Stable DiffusionとGANの詳細な比較について見ていきましょう。各モデルの長所と短所を示したこの分析は、特定の画像生成ニーズに合うモデルを理解するのに役立ちます。
トレーニングと計算要件
- GAN:過去にはGANが画像生成に選ばれることが多かったが、トレーニングは困難です。ジェネレータとディスクリミネータの間で安定した均衡を達成するのは複雑であり、ジェネレータが多様な出力を生成できないモード崩壊のリスクがあります。
- Diffusion Models:GANと比較して、Stable Diffusionなどのdiffusion modelsのトレーニングはより簡単です。デノイジングプロセスは信頼性があり、反復的な洗練プロセスによるノイズからの生成を可能にします。ただし、高解像度の画像の直接的な拡散プロセスにおいては、GANよりも計算量が多く必要です。高解像度の画像では、Variational Autoencoder(VAE)の潜在空間で動作する潜在的なdiffusion modelsは、これらの計算上の課題の一部を解決することができます。
- Transformers:テキスト生成と関連付けられることが多いですが、Transformerは画像モデルにも適用することができます。これらは、diffusionやGANモデルとは異なる生成プロセスの選択として、アーキテクチャ上の選択肢です。
具体的な用途
- クリエイティブなバリエーション: 拡散モデルは、芸術的で革新的な出力のための豊かなパレットを提供し、顕著なバリアンスを持つクリエイティブな画像を生成するのに理想的です。
- リアルなタイムラプス映像: 拡散モデルとGANの両方が、植物の成長などのタイムラプス映像を生成するのに適しています。拡散プロセスは、次のタイムステップへのノイズの除去に適応することができ、徐々な成長を効果的に捉えることができます。GANも前のタイムステップから各タイムステップを生成するように設計できますが、背景の一貫性を維持するためにより注意深い調整が必要になるかもしれません。
モデルの選択とデータセットの品質
- モデルのタイプの選択(拡散、GAN、自己回帰トランスフォーマー)は、モデルそのものの特性よりもデータセットの品質や大きさによってしばしばより多く依存することに注意する必要があります。
- 各モデルにはそれぞれの強みがありますが、最終的な出力の品質は入力データに大きく影響されます。したがって、モデルの選択はトレーニングデータの入手可能性と品質も考慮する必要があります。
モデル間のギャップを埋める
- 最近の研究では、自己回帰と拡散モデルのギャップを埋める方法が探求されており、両者を時間依存のノイズ除去プロセスのインスタンスとして捉えています。この研究は、それぞれのモデルの固有の利点を組み合わせたり活用したりするハイブリッドアプローチの可能性を示しています。
Stable Diffusionの利点と欠点
Stable Diffusionの利点:
Stable Diffusionは、GANに比べていくつかの利点を提供します:
- 安定したトレーニング: Stable Diffusionモデルは、GANよりもトレーニングが容易であり、より広範なユーザーにアクセスしやすくなっています。
- 一貫した出力品質: Stable Diffusionは、GANにおけるモード崩壊という一般的な問題のリスクなしで、一貫して高品質な画像を生成します。
- 複雑な画像生成タスクの扱いの改良: 拡散モデルは、複雑なテクスチャ、細部、鮮明なエッジを持つ画像の生成において、より良いパフォーマンスを示しています。
- トレーニング中の安定性の向上: Stable Diffusionモデルは、トレーニングの安定性と収束特性が向上し、トレーニングの失敗の可能性を減らします。
Stable Diffusionの欠点:
Stable Diffusionには利点がありますが、いくつかの制約もあります:
- 推論時間が長い: Stable Diffusionを使用して画像を生成するには、GANに比べてより多くの時間がかかります。初期のノイズ入力を洗練するために複数のイテレーションが必要です。
- より高い計算要件: Stable Diffusionモデルは、トレーニングと推論の両方でGANよりも多くの計算リソースを必要とします。
- 限定された応用分野: Stable Diffusionモデルは現在、画像生成タスクにおいてより適しており、画像から画像への変換などの他の応用にもGANほど汎用的ではありません。
使用ケースとパフォーマンス分析
Stable DiffusionとGANの実世界でのパフォーマンスを理解するためには、それぞれの使用ケースを探索し、さまざまなシナリオでのパフォーマンスを評価することが重要です。この分析により、特定の画像生成タスクにどのモデルがより適しているかについての洞察が得られます。例えば、風景、肖像画、抽象美術の生成などです。
生成AIの未来: Stable DiffusionまたはGAN?
GANおよび拡散モデルを含む生成モデルは、引き続き進化と改良がされています。生成AIの未来には、より安定した効率的なトレーニングアルゴリズム、複雑な画像生成タスクの扱いの改善、スケーラビリティの向上など、興味深い可能性があります。ただし、生成AIがより強力になるにつれて、その使用に関連する倫理的な考慮事項や潜在的なリスクに対処することが重要です。
結論
まとめると、GANとStable Diffusionの競争は、生成AIの分野を形作り続けています。GANは長い間風景に君臨してきましたが、Stable Diffusionはより安定した信頼性のある代替案として非常に有望です。Anakin AIのStable Diffusion Image Generatorを使用すると、Stable Diffusionの力を解き放ち、簡単に素晴らしい画像を作成することができます。GANまたはStable Diffusionを選ぶにせよ、生成AIの未来はクリエイティブな産業を変革し、さまざまな他の領域に影響を与えるという無限の可能性を秘めています。今日から生成AIの世界への旅を始め、無限の可能性を解き放ちましょう。
もう一つ:
Anakin AIのStable Diffusion Image Generatorを今すぐお試しください。生成AIの力を指先で解き放ちましょう!
最先端の拡散モデル技術を使って、簡単に素晴らしい画像を作成しましょう。Anakin AIのStable Diffusion Image Generatorで今すぐ始めて、創造的なアイデアを現実に変えましょう!