Stable Diffusion、テキストから画像に変換するためのオープンソースモデルは、初めてリリースされて以来、世界中に広まってきました。この強力なツールはStability AIによって開発され、テキストの説明から驚くべき視覚効果を持つ画像を作成できるようになりました。そして、Stable Diffusion 3 Mediumの導入により、Stability AIのチームはより一層限界を押し広げ、よりコンパクトかつアクセスしやすいパッケージで、卓越したパフォーマンスと品質を提供します。
💡
Stable Diffusionへの無料アクセスをご希望ですか?Anakin AIではStable Diffusionの一部のモデルに現在無料でアクセスできます!
無料でStable Diffusionを探求し、創造力を解き放ちましょう!
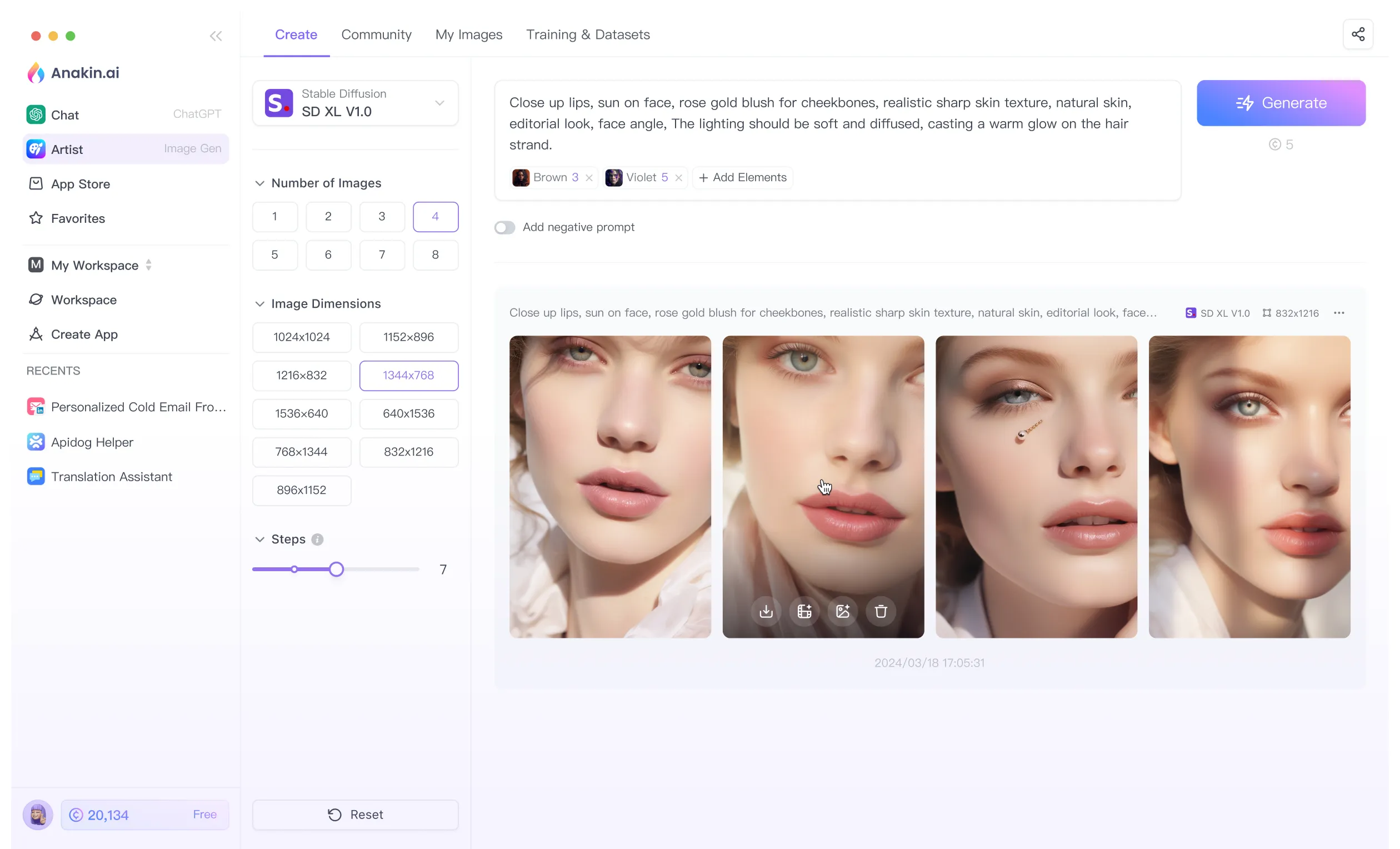
Stable Diffusion 3 Medium:より小型でさらに優れたモデル
Stable Diffusion 3 Mediumの最も重要な特徴の1つは、より大型のStable Diffusion 3 Largeと比較して、サイズが小さくなったことです。SD3 Largeは80億のパラメータを持っている一方、SD3 Mediumは20億のパラメータで相当な性能を発揮します。このサイズの縮小により、ユーザーは一般的なハードウェア上でモデルを効率的に実行できるため、品質を犠牲にすることなく高度な画像生成の機能にアクセスできます。

一般的なGPUで高品質な画像の生成が可能になることで、多くのユーザーにとって画期的な転換点となります。SD3 Mediumは、わずか5 GBのGPU VRAMが必要なだけで高度な画像生成の可能性を広げます。アーティスト、デザイナー、クリエイティブなマインドを持つ人々は、高価な特殊なハードウェアを必要とせずにStable Diffusionのパワーを活用することができます。
| GPU のモデル |
VRAM |
SD3 Medium の性能 |
| NVIDIA RTX 3060 |
12 GB |
2.35 秒/画像(8枚) |
| NVIDIA RTX 3090 |
24 GB |
3.15 秒/画像(8枚) |
| AMD Radeon RX 7900 XTX |
24 GB |
21 it/s |
Stable Diffusion 3 Medium vs DALLE 3:より写真のようで、文字の表現がより優れています
Stable Diffusion 3 Medium(DALLE 3などの競合他社と比較した場合)の特筆すべき特徴の1つは、非常に高い精度で写真のような画像を生成できる能力です。モデルは細かいディテールと複雑なテクスチャをキャプチャするように調整されており、現実の世界の写真に非常に近いビジュアルが生成されます。この実物のような写真の品質は、モデルの小さいサイズにもかかわらず非常に印象的です。

写真のような画像を生成する能力に加えて、SD3 Mediumはタイポグラフィの生成でも優れています。モデルはテキストを明瞭かつ正確に理解し、表現するようにトレーニングされています。テキストを組み込んだイメージを作成したり、独立したティポグラフィを生成したりする場合、SD3 Mediumは鮮明で読みやすいビジュアルを提供します。
 Stable Diffusion 3 Medium vs DALLE 3
Stable Diffusion 3 Medium vs DALLE 3SD3 Mediumの写真のような写真現実的な表現と優れたタイポグラフィ生成の例:
- "ビンテージの1950年代のレストランで、ネオンサインと古い車が駐車している"
- "高層ビル、空飛ぶ車、ホログラフ広告がある未来都市の風景"
- "ヒエログリフ、巨大な像、神秘的な石棺がある古代のエジプトの神殿"
Stable Diffusion 3 Mediumの中間のプロンプト:すべてが改善されてより簡単になりました
Stable Diffusion 3 Mediumが優れている別の領域は、複雑なプロンプトを理解し解釈できる能力です。
モデルは自然言語のニュアンスを把握し、ユーザーが望むシーン、オブジェクト、構成の詳細な説明を提供できるようにデザインされています。SD3 Mediumはこれらのプロンプトを分析し、ユーザーの意図を正確に反映した画像を生成することができます。
さらに、モデルは空間的な関係と構成要素について深い理解を持っています。モデルは、提供されたプロンプトに基づいてオブジェクトを効果的に画像内に配置し、サイズ、位置、要素間の相互作用などの要素を考慮します。
この空間認識能力により、ユーザーは視覚的に整合性のある、効果的な構成のイメージを簡単に生成することができます。
SD3 Mediumの複雑なプロンプトの理解と空間的な関係の例:
"日没の美しいビーチに浮かぶ壮大なドラゴン"
"森の中の居心地の良い小屋、大きなマツと小川に囲まれた"
"バイオルミネッセンスの植物、光り輝くキノコ、魔法の生物がいっぱいの魔法の森"
リソースの効率性と細かい調整の能力
Stable Diffusion 3 Mediumの小さなサイズは、さまざまなユーザーに対して利用可能にするだけでなく、リソースの効率性にも貢献しています。モデルの小さなメモリフットプリントにより、専用のハードウェアの必要性が最小限に抑えられ、一連の画像を生成する必要がある場合や、リソースが限られている環境で作業している場合に特に便利です。
さらに、SD3 Mediumは細かい調整の能力も非常に優れています。モデルは少量のデータセットから微妙な詳細を吸収することができるため、個々のニーズに合わせてモデルをカスタマイズし調整することができます。特定のアートスタイル、特定のドメイン、または独自の視覚要素セットに取り組んでいる場合、SD3 Mediumの細かい調整機能を活用することで、よりカスタマイズされた画像生成が可能になります。
Stable Diffusion 3 APIの使用方法
💡
AIモデルのAPIサブスクリプションを10個以上管理することに苦労していますか?心配しないでください!Anakin AIは、すべてのLLMおよび画像生成モデルを1つの場所で簡単にアクセスできるAI統合プラットフォームです!
Anakin AI API統合を始めましょう!
Stable Diffusion 3 APIの使用は簡単なプロセスです。以下は手順のガイドです:
ステップ1:APIキーを取得する
Stable Diffusion 3 APIにアクセスするためには、APIキーを取得する必要があります。Stability AIのウェブサイトにアクセスし、アカウントを作成してください。アカウントを作成したら、APIキーのセクションに移動し、新しいAPIキーを生成します。
ステップ2:必要なライブラリのインストール
Stable Diffusion 3 APIとの連携には、いくつかのライブラリのインストールが必要です。pipを使用して以下のコマンドでインストールできます:
pip install requests pillow
ステップ3:APIリクエストの実行
APIキーと必要なライブラリを用意したら、画像を生成するためにAPIリクエストを実行できます。以下にPythonのコードの例を示します:
import requests
from PIL import Image
from io import BytesIO
api_key = "YOUR_API_KEY"
url = "https://api.stability.ai/v1/generation/stable-diffusion-v3/text-to-image"
prompt = "A beautiful sunset over a serene beach"
payload = {
"text_prompts": [
{
"text": prompt
}
],
"cfg_scale": 7,
"clip_guidance_preset": "FAST_BLUE",
"height": 512,
"width": 512,
"samples": 1,
"steps": 30,
}
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
for i, image_data in enumerate(data["artifacts"]):
image_url = image_data["base64"]
image = Image.open(BytesIO(requests.get(image_url).content))
image.save(f"generated_image_{i}.png")
else:
print(f"Request failed with status code {response.status_code}")
この例では、APIエンドポイントのURLと画像生成のプロンプトを設定します。その後、画像のサイズ、サンプルの数、および拡散プロセスのステップ数など、希望するパラメータを指定します。
次に、プロンプトとパラメータを含むペイロードを作成し、APIキーとコンテンツタイプのヘッダーを設定します。最後に、ヘッダーとペイロードを使用してAPIエンドポイントにPOSTリクエストを送信します。
リクエストが成功した場合(ステータスコードが200)、レスポンスから生成された画像データを取得し、PNGファイルとして保存します。リクエストが失敗した場合、デバッグのためにステータスコードを表示します。
ステップ4:カスタマイズと実験
コードを変更し、さまざまなプロンプトやパラメータを試して異なる種類の画像を生成してみてください。cfg_scaleを調整してプロンプトに画像が適合する度合いを制御し、clip_guidance_presetを変更してスタイルに影響を与え、heightとwidthを変更して異なるサイズの画像を生成することができます。
Stable Diffusion 3 APIは、創造的でユニークな画像を生成するためのさまざまな可能性を提供します。APIのドキュメントを探索して、使用可能なパラメータやオプションについてさらに詳しく学びましょう。
APIキーを安全に管理し、公開しないように注意してください。これらの手順を実行することで、テキストのプロンプトから驚くべき画像を生成するためにStable Diffusion 3 APIを使用する準備が整います!
Stable Diffusion 3 Mediumはオープンソースで無料です

Stability AIは、さまざまなチャンネルを通じてStable Diffusion 3 Mediumへのアクセスを提供しています:
ユーザーは、API Stabilityを介してモデルをテストできます。これにより、既存のワークフローやアプリケーションにシームレスに統合できます。
モデルのウェイトは非商用利用のオープンライセンスで利用できるため、研究者やエンスージアストが技術を探索し実験することができます。
商用利用においては、Stability AIではクリエイターライセンスとエンタープライズライセンスを提供しています。これらのライセンスオプションにより、プロジェクトや製品でSD3 Mediumを活用したい個人や企業が必要な権限とサポートを取得することができます。
柔軟なライセンスオプションを提供することにより、Stability AIはこの強力なテクノロジーの利点を幅広いユーザーが活用できるようにします。モデルはこちらでダウンロードできます。

結論
Stable Diffusion 3 Mediumは、テキストから画像生成のモデルの進化において重要なステップです。SD3 Mediumは、高度な画像生成の能力に特化したコンパクトでアクセスしやすいパッケージで、卓越したパフォーマンスと品質を提供します。フォトリアリスティックな画像の生成、複雑なプロンプトのサポート、および空間関係の理解に優れた能力により、SD3 Mediumはクリエイティブプロフェッショナルやエンスージアストにとって強力で多目的なツールとして注目されています。
AI生成技術の限界に挑戦し続けるStability AIは、高度な画像生成能力へのアクセスを民主化することに注力しています。効率的なリソース利用、細かい調整能力、柔軟なライセンスオプションにより、SD3 Mediumはビジュアルコンテンツの作成と相互作用の方法を革新する準備が整いました。アーティスト、デザイナー、研究者、クリエイティブなマインドを持つ人々にとって、Stable Diffusion 3 Mediumはこれまでにない方法で想像力を具現化するチャンスを提供します。
💡
Stable Diffusionへの無料アクセスをご希望ですか?Anakin AIではStable Diffusionの一部のモデルに現在無料でアクセスできます!
無料でStable Diffusionを探求し、創造力を解き放ちましょう!



