安定拡散というオープンソースのテキストから画像を生成するモデルは、その初期リリース以来世界中で大きな話題を呼んでいます。Stability AIによって開発されたこの強力なツールは、高度な画像生成機能へのアクセスを民主化し、ユーザーがテキストの説明から見事なビジュアルを作成することを可能にしました。そして、Stable Diffusion 3 Mediumの登場により、Stability AIチームはさらに進化し、よりコンパクトでアクセスしやすいパッケージで優れたパフォーマンスと品質を提供しています。
💡
Stable Diffusionを無料でアクセスしたいですか?
Anakin AIでは、現在Stable Diffusionモデルの一部に無料でアクセスできます!
Anakin AIで自分の創造力を解き放ちましょう!
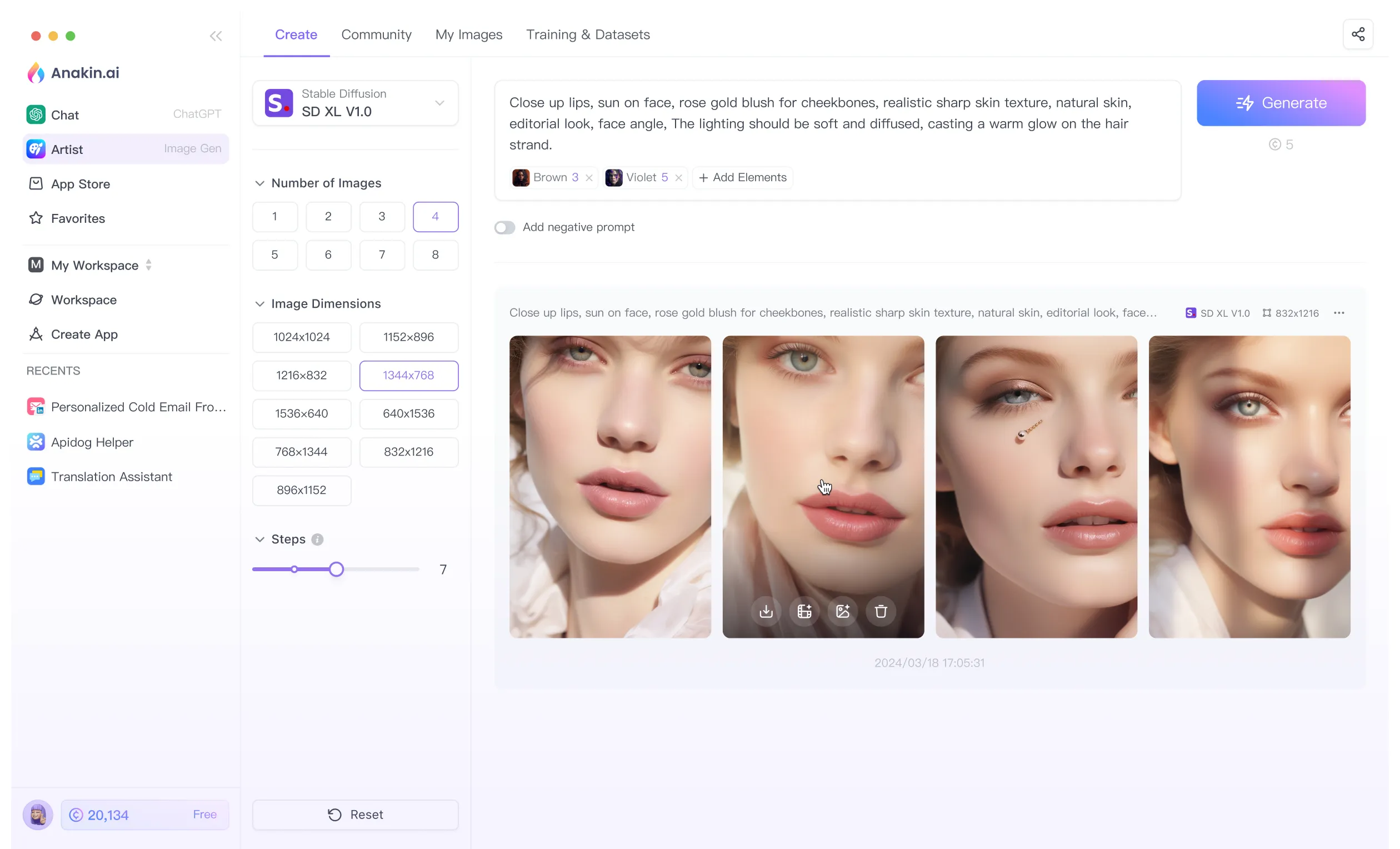
Stable Diffusion 3 Medium:小型ですがより優れたモデル
Stable Diffusion 3 Mediumの最も注目すべき特徴の一つは、より大きなモデルであるStable Diffusion 3 Largeと比べてそのサイズが小さくなっていることです。SD3 Largeは80億の驚異的なパラメータを誇りますが、SD3 Mediumはわずかに20億のパラメータで充分な性能を発揮します。 このサイズの削減は、ユーザーに重要な意味を持ちます。なぜなら、それによってモデルは品質を損なうことなく、消費者用のハードウェア上で効率的に動作することができるからです。

一般の消費者用GPU上で高品質の画像を生成できる能力は、多くのユーザーにとって画期的な進歩です。SD3 Mediumはたった5GBのGPU VRAMという最低要件で、高度な画像生成の可能性をより広い層のユーザーに開放しています。芸術家、デザイナー、創造的な愛好家であれ、高価で特殊なハードウェアを必要とせずにStable Diffusionのパワーを活用できます。
| GPUモデル |
VRAM |
SD3 Mediumのパフォーマンス |
| NVIDIA RTX 3060 |
12 GB |
2.35秒/画像(8枚) |
| NVIDIA RTX 3090 |
24 GB |
3.15秒/画像(8枚) |
| AMD Radeon RX 7900 XTX |
24 GB |
21枚/秒 |
Stable Diffusion 3 MediumとDALLE 3の比較:より写真のようで、タイポグラフィも優れています
Stable Diffusion 3 MediumがDALLE 3などの競合他社と比較して際立っている特徴の一つは、きめ細かいディテールやテクスチャを捉える能力による写真のような画像を生成することです。このモデルは微細な部分を捉えるように微調整されており、実際の写真に非常に近いビジュアルを実現しています。モデルのサイズが小さいことを考慮に入れると、このような写真のような表現力は特に印象的です。

写真のような能力に加えて、SD3 Mediumはタイポグラフィの生成でも優れています。このモデルは、テキストを明瞭かつ正確に理解してレンダリングするようにトレーニングされています。テキストを埋め込んだ画像を作成したり、単独のタイポグラフィを生成したりする場合、SD3 Mediumは鮮明で読みやすく、視覚的に魅力的な結果を提供します。
 Stable Diffusion 3 MediumとDALLE 3の比較
Stable Diffusion 3 MediumとDALLE 3の比較SD3 Mediumの写真のようなリアルさとタイポグラフィの能力を示すいくつかのプロンプトの例:
- 「ネオンサインとクラシックカーが駐車されたヴィンテージの1950年代のダイナー」
- 「高層ビルや飛行車、ホログラフィック広告がある未来都市の風景」
- 「ヒエログリフ、高い像、神秘的な石棺がある古代エジプトの神殿」
Stable Diffusion 3 Mediumのプロンプト:より良く簡単になる
Stable Diffusion 3 Mediumの優れている点の一つは、複雑なプロンプトを理解し解釈する能力です。
- このモデルは自然言語の微妙なニュアンスを理解するように設計されており、ユーザーはシーンやオブジェクト、構成の詳細な説明を提供することができます。SD3 Mediumはこれらのプロンプトを解析し、ユーザーの意図を正確に反映した画像を生成することができます。
- さらに、このモデルは空間的な関係性や構成要素に対する深い理解を持っています。提供されたプロンプトに基づいて、モデルは要素のサイズ、配置、および要素間の相互作用などの要素を考慮して画像内にオブジェクトを効果的に配置することができます。
- このような空間的な理解により、ユーザーはビジュアル的に一貫した、よく構成された画像を簡単に作成することができます。
SD3 Mediumの複雑なプロンプトの理解と空間的な関係性を示すいくつかの例:
- 「夕日に照らされた霧のかかった山岳地帯を舞う壮大なドラゴン」
- 「高い松の木とせせらぎのある小川に囲まれた森にある居心地の良い小屋」
- 「バイオルミネセンスのある植物、輝くキノコ、魔法の生物がいっぱいの魔法の森」
リソース効率と微調整の能力
Stable Diffusion 3 Mediumのコンパクトなサイズは、より幅広い範囲のユーザーにアクセスしやすくするだけでなく、リソースの効率化にも寄与しています。モデルのメモリの使用量が減ることで、標準的な消費者用GPUでのスムーズな動作が可能になり、高度なハードウェアへの需要を最小限に抑えることができます。この効率性は、短期間で複数の画像を生成したいユーザーや計算リソースが限られている状況で作業しているユーザーに特に効果的です。
さらに、SD3 Mediumは優れた微調整の能力を提供しています。このモデルは小規模なデータセットから微妙なディテールを吸収することができ、ユーザーはモデルをカスタマイズして特定の要件に適合させることができます。特定のアートスタイル、特定のドメイン、または一意のビジュアル要素に取り組んでいる場合、SD3 Mediumの微調整の能力を活用することで、よりパーソナライズされたターゲットの画像生成を実現することができます。
Stable Diffusion 3 APIの使用方法
💡
AIモデルの10以上のAPIサブスクリプションを管理するのに苦労していますか?
心配いりません!Anakin AIは、すべてのLLMおよび画像生成モデルに簡単にアクセスできるオールインワンのAI集約プラットフォームです!
Anakin AIの
API統合を今すぐ始めましょう!
Stable Diffusion 3 APIの使用は簡単です。以下にステップバイステップのガイドを示します:
ステップ1:APIキーに登録する
Stable Diffusion 3 APIにアクセスするには、APIキーに登録する必要があります。Stability AIのウェブサイトにアクセスし、アカウントを作成してください。アカウントを作成したら、APIキーのセクションに移動し、新しいAPIキーを生成します。
ステップ2:必要なライブラリをインストールする
Stable Diffusion 3 APIとやり取りするためには、いくつかのライブラリをインストールする必要があります。pipを使用してインストールできます:
pip install requests pillow
ステップ3:APIリクエストを作成する
APIキーと必要なライブラリが準備できたら、画像を生成するためにAPIリクエストを作成できます。以下にPythonでのサンプルコードを示します:
import requests
from PIL import Image
from io import BytesIO
api_key = "YOUR_API_KEY"
url = "https://api.stability.ai/v1/generation/stable-diffusion-v3/text-to-image"
prompt = "美しい日没の静かなビーチ"
payload = {
"text_prompts": [
{
"text": prompt
}
],
"cfg_scale": 7,
"clip_guidance_preset": "FAST_BLUE",
"height": 512,
"width": 512,
"samples": 1,
"steps": 30,
}
headers = {
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {api_key}"
}
response = requests.post(url, json=payload, headers=headers)
if response.status_code == 200:
data = response.json()
for i, image_data in enumerate(data["artifacts"]):
image_url = image_data["base64"]
image = Image.open(BytesIO(requests.get(image_url).content))
image.save(f"generated_image_{i}.png")
else:
print(f"リクエストがステータスコード{response.status_code}で失敗しました")
この例では、APIエンドポイントのURLと画像を生成するためのプロンプトを定義します。その後、画像サイズ、サンプル数、拡散プロセスのステップ数などの必要なパラメータを設定します。
プロンプトとパラメータを含むペイロードを作成し、APIキーとコンテンツタイプを含むヘッダーを設定します。最後に、ペイロードとヘッダーを使用してAPIエンドポイントにPOSTリクエストを送信します。
リクエストが成功した場合(ステータスコード200)、レスポンスから生成された画像データを取得し、PNGファイルとして保存します。リクエストが失敗した場合、デバッグのためにステータスコードを表示します。
ステップ4:カスタマイズと実験
コードを変更し、さまざまなプロンプトやパラメータを試してさまざまなタイプの画像を生成してみてください。 cfg_scaleを調整してプロンプトへの適合度を制御したり、clip_guidance_presetを変更してスタイルに影響を与えたり、 heightとwidthを変更して異なるサイズの画像を生成したりすることができます。
Stable Diffusion 3 APIは、創造的でユニークな画像を生成するための幅広い可能性を提供しています。使用可能なパラメータやオプションについて詳しく知るためには、APIのドキュメントを参照してください。
APIキーを安全に管理し、公に共有しないようにすることを忘れないでください。これらのステップで、テキストプロンプトから素晴らしい画像を生成するためのStable Diffusion 3 APIを使用する準備が整いました!
はい、Stable Diffusion 3 Mediumはオープンソースで無料で使用できます

Stability AIは、Stable Diffusion 3 Mediumをさまざまなチャネルを通じて利用できるようにしています:
- ユーザーはStability APIを介してモデルをテストし、既存のワークフローやアプリケーションにシームレスに統合することができます。
- モデルの重みはオープンな非商用ライセンスのもとで利用可能であり、研究者や愛好家がこの技術を探索し実験することができます。
- 商業利用には、Stability AIがクリエイターライセンスとエンタープライズライセンスを提供しています。これらのライセンスオプションは、プロジェクトや製品でSD3 Mediumを活用したい個人や企業に必要な権限とサポートを提供します。
柔軟なライセンスオプションを提供することで、Stability AIは強力なテクノロジーの利点を幅広いユーザーが活用できるようにしています。モデルはこちらからダウンロードできます。

まとめ
Stable Diffusion 3 Mediumは、テキストから画像を生成するモデルの進化における重要な節目を示しています。小型でアクセスしやすいパッケージで優れたパフォーマンスと品質を提供することにより、SD3 Mediumは専門的なハードウェアを必要とせずに素晴らしいビジュアルを作成できるようにします。写真のような画像の生成能力、複雑なプロンプトの処理能力、および空間的な関係性の理解能力により、SD3 Mediumはクリエイティブなプロフェッショナルや愛好家にとって高い汎用性とパワフルなツールとなっています。
Stability AIがジェネラティブAIの限界を引き上げ続ける中、Stable Diffusion 3 Mediumは先進的な画像生成機能へのアクセスを民主化するという彼らの取り組みの証となっています。リソースの効率性、微調整の能力、柔軟なライセンスオプションにより、SD3 Mediumは私たちがビジュアルコンテンツを作成し、それと対話する方法を革新する準備が整っています。アーティスト、デザイナー、研究者、創造性に溢れる人々であれば、Stable Diffusion 3 Mediumによって、今まで以上に創造力を活かしたアイデアを実現することができます。
💡
Stable Diffusionを無料でアクセスしたいですか?
Anakin AIでは、現在Stable Diffusionモデルの一部に無料でアクセスできます!
Anakin AIで自分の創造力を解き放ちましょう!



