はじめに
自然言語処理(NLP)と情報検索の領域では、外部ソースから関連情報を検索する能力を持つ大規模言語モデル(LLM)の強みを組み合わせたRetrieval Augmented Generation(RAG)という概念が強力な手法として登場しました。このチュートリアルでは、Meta AIの最先端の言語モデルであるLlama 3言語モデルとLlamaIndexライブラリを使用して、ローカルのLLM RAGシステムを構築する手順を案内します。
Llama 3は、対話型のユースケースに適した優れた性能で知られるMeta AIによって開発された最先端の言語モデルです。一方、LlamaIndexは、LLMと情報検索機能のシームレスな統合を提供することで、Retrieval Augmented Generationシステムの構築プロセスを簡素化するためのPythonライブラリです。
このチュートリアルに従って、必要な環境の設定、データの前処理とインデックス作成、クエリエンジンの作成、およびLlama 3とLlamaIndexのパワーを活用して効率的かつ正確なRAGシステムの構築方法を学ぶことができます。研究者、開発者、またはNLPの最新の進展に興味がある方にとって、このチュートリアルはRAGシステムのエキサイティングな世界を探求するための堅固な基盤を提供します。
No-Code RAGソリューションにAnakin AIを使用する方法
Anakin AIは、コードを書かずにAIパワードアプリケーションを構築できる強力なノーコードプラットフォームです。カスタムAIモデルの作成、データソースの統合、アプリケーションのデプロイに対するビジュアルインターフェースを提供します。Anakin AIを使用すると、広範なプログラミング知識なしに独自のRetrieval Augmented Generation(RAG)システムを構築することができます。
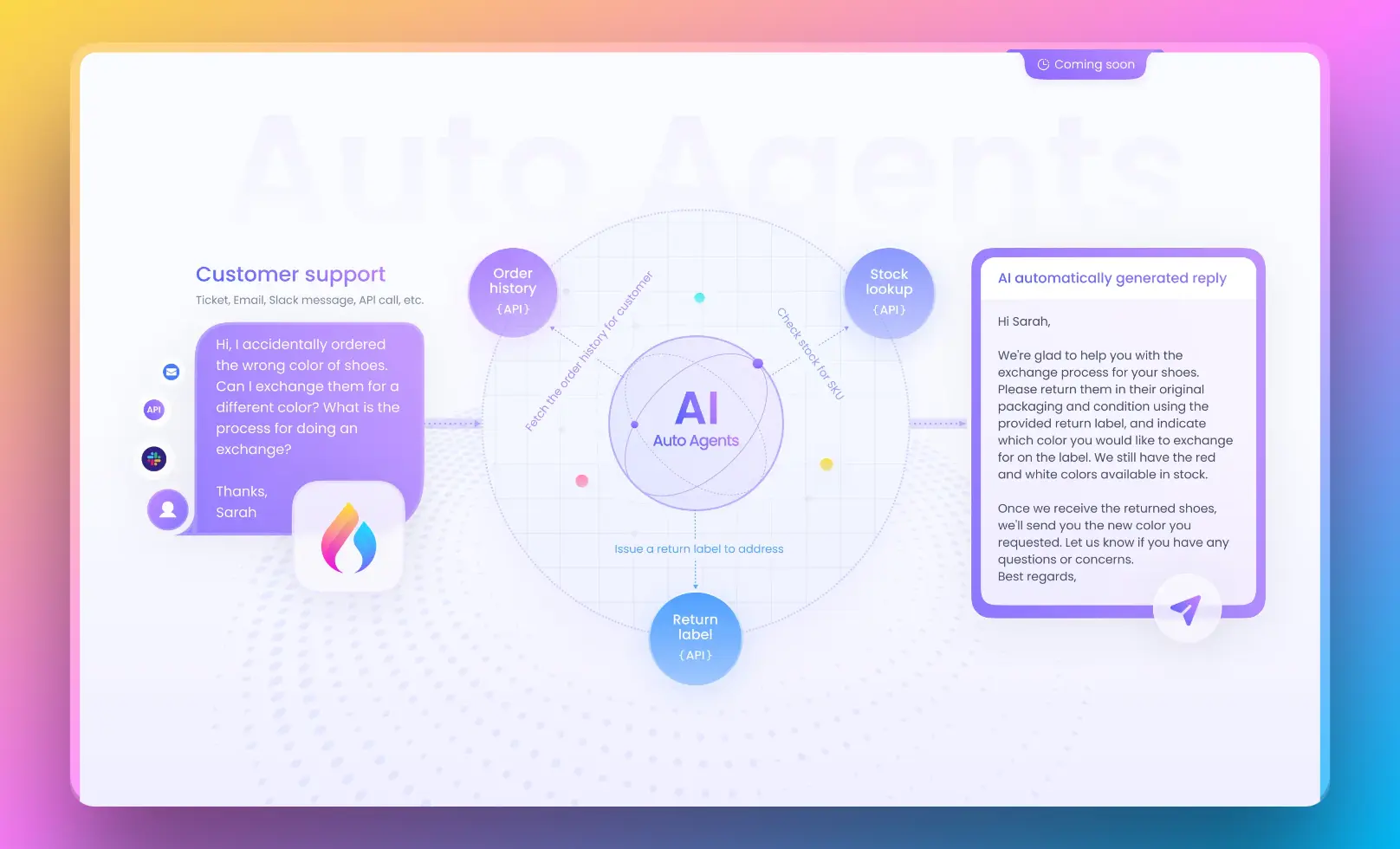
このプラットフォームは、カスタムRAGアプリケーションを作成するために使用できる事前構築コンポーネントやテンプレートの範囲を提供します。ドキュメント、データベース、APIなどのデータソースを接続し、検索と生成のコンポーネントを必要に応じて設定できます。
Anakin AIを使用する際の主な利点の1つは、非技術的なユーザーにもアクセス可能なユーザーフレンドリーなインターフェースです。コンポーネントをドラッグアンドドロップしたり、設定を構成したり、AIアプリケーションを数回クリックするだけでデプロイできます。さらに、Anakin AIにはチームが共同でAIアプリケーションの構築と維持を行うためのコラボレーション機能も提供されています。
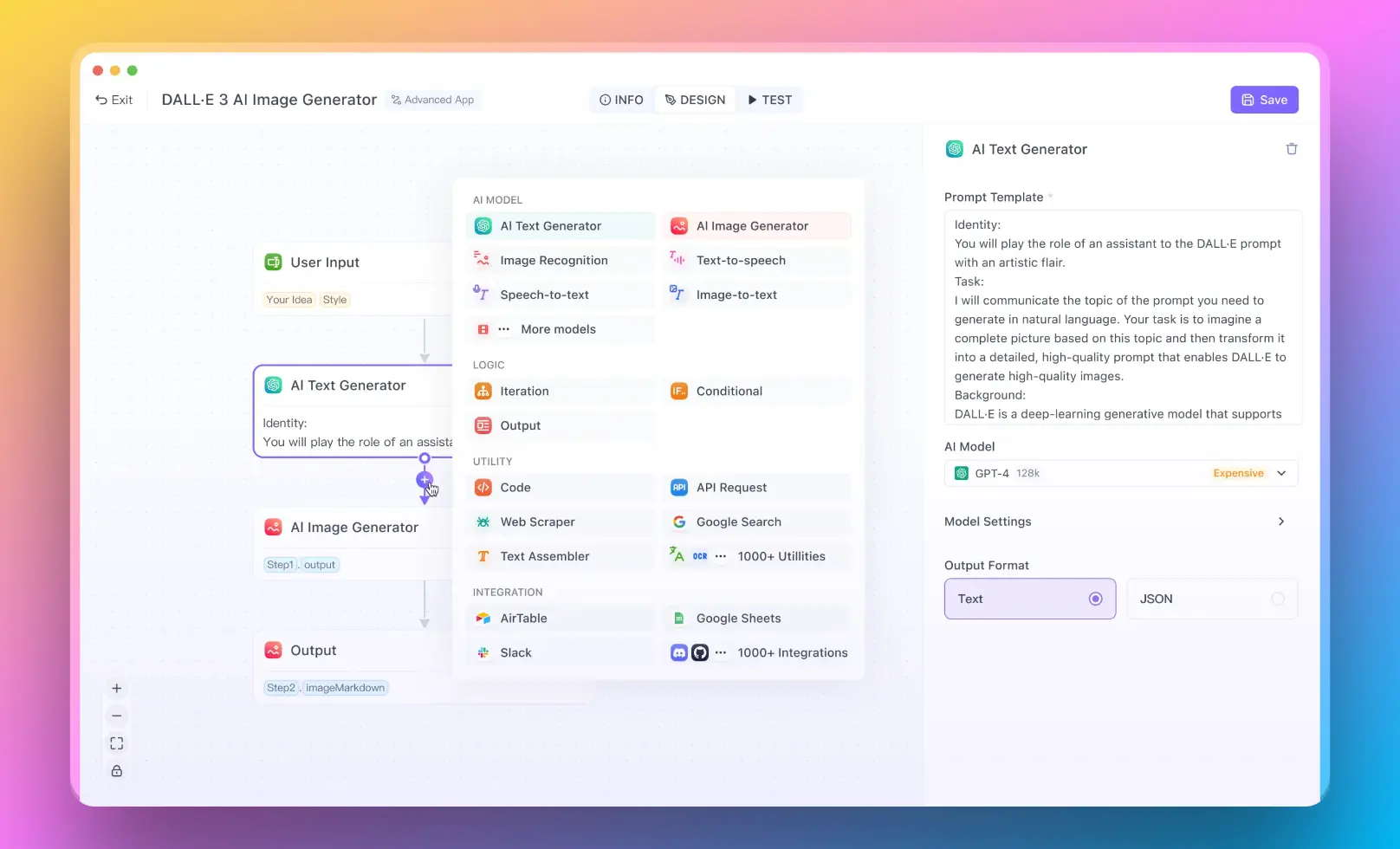
Anakin AIは、コードベースのアプローチと同じレベルの柔軟性とカスタマイズ性を提供しないかもしれませんが、広範なプログラミングの専門知識を必要とせずにAIアプリを作成できる便利で効率的な方法を提供します。これは、RAGシステムのパワーを活用したいが、ゼロから開発するためのリソースや専門知識が不足しているビジネスや組織に特に役立ちます。
Anakin AIとその機能について詳しくは、https://anakin.aiをご覧ください。

ステップ1:必要なライブラリのインストール
チュートリアルに入る前に、必要なライブラリがインストールされていることを確認する必要があります。ターミナルまたはコマンドプロンプトを開き、次のコマンドを実行してください:
pip install llama-index
pip install llama-index-llms-huggingface
pip install llama-index-embeddings-huggingface
これらのコマンドは、Hugging Faceのモデルと埋め込みに対応したLlamaIndexとその依存関係をインストールします。
ステップ2:トークナイザとストッピングIDの設定
次に、Llama 3モデルのトークナイザとストッピングIDを設定する必要があります。PythonスクリプトまたはJupyter Notebookで、必要なライブラリをインポートし、トークナイザをロードしてください:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3-8B-Instruct",
token=hf_token,
)
stopping_ids = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>"),
]
hf_tokenを使用するHugging Faceトークンで置き換えてください。stopping_idsリストには、シーケンスの終わりを示すトークンIDと、生成プロセスを停止するために使用される特殊なトークンIDが含まれています。
ステップ3:HuggingFaceLLMを使用してLLMを設定する
このステップでは、LlamaIndexのHuggingFaceLLMクラスを使用してLlama 3言語モデルを設定します。このクラスは、LlamaIndexエコシステム内でHugging Faceモデルを扱うための便利なインターフェースを提供します。
import torch
from llama_index.llms.huggingface import HuggingFaceLLM
llm = HuggingFaceLLM(
model_name="meta-llama/Meta-Llama-3-8B-Instruct",
model_kwargs={
"token": hf_token,
"torch_dtype": torch.bfloat16,
},
generate_kwargs={
"do_sample": True,
"temperature": 0.6,
"top_p": 0.9,
},
tokenizer_name="meta-llama/Meta-Llama-3-8B-Instruct",
tokenizer_kwargs={"token": hf_token},
stopping_ids=stopping_ids,
)
このコードスニペットでは、適切なモデル名、モデルのパラメータ、生成のパラメータ、トークナイザの名前、およびストッピングIDを指定して、HuggingFaceLLMのインスタンスを作成します。好みに応じて生成のパラメータを調整してください。
ステップ4:データの読み込みと前処理
インデックスを作成する前に、RAGシステムで使用するデータを読み込み、前処理する必要があります。LlamaIndexでは、この目的のために便利なSimpleDirectoryReaderクラスを提供しています。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["path/to/your/data/files"]
).load_data()
"path/to/your/data/files"を実際のデータファイルへのパスに置き換えてください。load_data()メソッドはファイルを読み込み、ドキュメントのリストを返します。
ステップ5:埋め込みモデルの設定
インデックスを作成するためには、ドキュメントのベクトル表現を生成するための埋め込みモデルを設定する必要があります。LlamaIndexでは、Hugging Faceをはじめとするさまざまな埋め込みモデルをサポートしています。
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-en-v1.5")
この例では、Hugging Faceの"BAAI/bge-small-en-v1.5"モデルを使用しています。要件と計算リソースに基づいて、異なるモデルを選択することができます。
ステップ6:デフォルトのLLMと埋め込みモデルを設定する
次に、LlamaIndexがデフォルトで使用するLLMと埋め込みモデルを設定する必要があります。Settingsクラスを使用します。
from llama_index.core import Settings
Settings.embed_model = embed_model
Settings.llm = llm
このステップにより、LlamaIndexがデフォルトでLlama 3言語モデルと指定した埋め込みモデルを使用するようになります。
ステップ7:インデックスの作成
データとモデルの設定が完了したら、LlamaIndexのVectorStoreIndexクラスを使用してインデックスを作成できます。
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(documents)
from_documents()メソッドは、前に読み込んだドキュメントのリストからインデックスを作成します。
ステップ8:QueryEngineの作成
インデックスをクエリし、関連する情報を取得するためには、QueryEngineのインスタンスを作成する必要があります。
query_engine = index.as_query_engine(similarity_top_k=3)
as_query_engine()メソッドは、インデックスからQueryEngineのインスタンスを作成します。similarity_top_kパラメータは、類似性スコアに基づいて取得する上位ランクのドキュメントの数を指定します。
ステップ9:インデックスのクエリ
QueryEngineが設定されたら、インデックスをクエリし、関連する情報を取得することができます。
response = query_engine.query("What did Paul Graham do growing up?")
print(response)
クエリ文字列を独自の質問やプロンプトに置き換えてください。query()メソッドは関連するドキュメントを取得し、Llama 3言語モデルを使用して応答を生成します。
ステップ10:エージェントとツールの構築(オプション)
LlamaIndexは、カスタムツールとエージェントを定義して高度な使用事例に対応する強力なエージェントベースのインターフェースを提供します。このステップはオプションですが、RAGシステムの機能を拡張したい場合に便利です。
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import BaseTool, FunctionTool
from llama_index.core.agent import ReActAgent
# カスタムツールを定義するか、作成したQueryEngineを使用したQueryEngineToolを使用します。
query_engine_tool = QueryEngineTool(
query_engine=query_engine,
metadata=ToolMetadata(
name="my_query_engine",
description="インデックスされたドキュメントから情報を提供します。",
),
)
# ツールとLLMを使用してReActAgentインスタンスを作成します。
agent = ReActAgent.from_tools([query_engine_tool], llm=llm, verbose=True)
# エージェントをクエリします。
response = agent.chat("What did Paul Graham do growing up?")
print(str(response))
この例では、QueryEngineToolを使用してQueryEngineインスタンスを作成します。次に、ツールとLlama 3言語モデルを使用してReActAgentインスタンスを作成します。最後に、chat()メソッドを使用してエージェントにクエリします。
結論
おめでとうございます!Llama 3とLlamaIndexを使用して、ローカルのLLM RAGシステムを正常に構築しました。このチュートリアルでは、環境の設定、データの前処理、インデックスの作成、クエリエンジンの作成、およびシステムのクエリといった重要なステップについて説明しました。
RAGシステムは、大規模言語モデルの強みと情報検索能力を組み合わせることで、より正確でコンテキストに即した応答を実現する強力なツールです。最先端のLlama 3言語モデルとユーザーフレンドリーなLlamaIndexライブラリを活用することで、さまざまなアプリケーションに効率的かつ効果的なRAGシステムを構築できます。
特定のニーズに合わせて、さまざまなデータセット、埋め込みモデル、および設定を試して探索したり、ユーザーインターフェースやAPIなどの他のコンポーネントとRAGシステムを統合して、より包括的でユーザーフレンドリーなアプリケーションを作成することを検討してください。
楽しくコーディングし、追求不思議なRetrieval Augmented Generationの世界を探求してください!
以下は、代替RAGソリューションとしてのAnakin AIの使用に関するセクションです:



