メタのLlama 3.1シリーズは、大規模な言語モデル(LLM)の領域において重要な進歩を表しており、3つの異なるバリアントを提供しています。巨大な405Bパラメータモデル、中程度の70Bモデル、よりコンパクトな8Bモデルです。この記事では、これらの3つのモデルの性能評価と価格に焦点を当て、総合的な比較を提供します。
💡
リージョン制限のない最もパワフルなAIモデル、Llama 3.1 405Bを使いたいですか?
Anakin AIはあなたの頼れるソリューションです!
Anakin AIは、Llama Models from Meta、Claude 3.5 Sonnet、GPT-4、Google Gemini Flash、
Uncensored LLM、DALLE 3、Stable Diffusionへのアクセスが1つの場所で可能で、
APIサポートにより簡単に統合できます!
はじめてみてください!👇👇👇
 Llama 3.1 405Bを使用
Llama 3.1 405Bを使用Llama 3.1 405B vs 70B vs 8B: モデルの概要
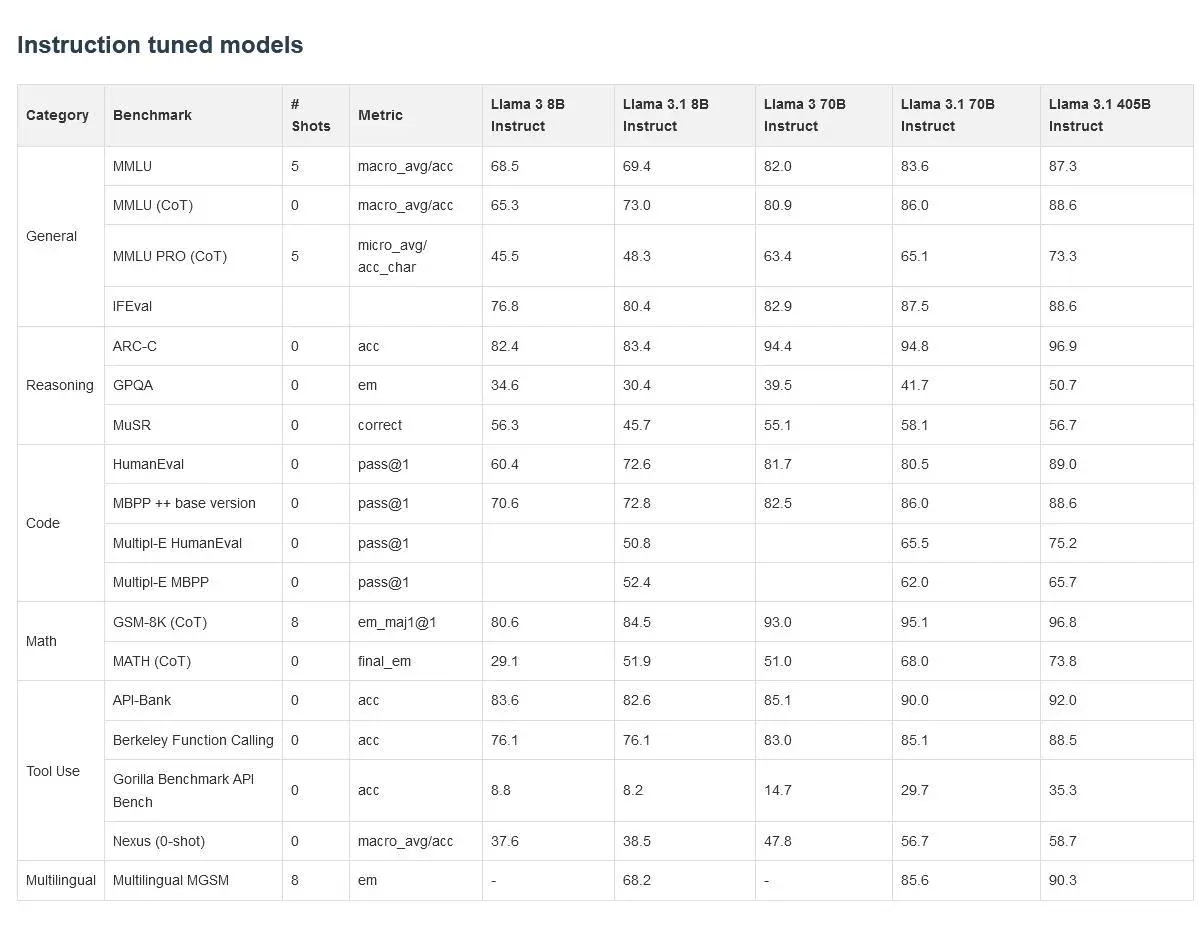 Llama 3.1 405B vs 70B vs 8B ベンチマーク比較
Llama 3.1 405B vs 70B vs 8B ベンチマーク比較Llama 3.1シリーズは、以前のバージョンの成功を受けて、多言語対応、推論、全体的なパフォーマンスの改善を導入しています。3つのモデルはいくつかの共通の特徴を共有しています。
- トレーニングデータ:公開されているソースから15T以上のトークンでトレーニングされました
- 多言語サポート:フランス語、ドイツ語、ヒンディー語、イタリアン語、ポルトガル語、スペイン語、タイ語に明示的なサポートがあります
- アーキテクチャ:最適化されたトランスフォーマーアーキテクチャに基づいています
- コンテキストの長さ:すべてのモデルに対して128kのトークン
各モデルの具体的な詳細について見ていきましょう。
Llama 3.1 405B vs 70B vs 8Bのパフォーマンスベンチマーク
各モデルの能力を理解するために、さまざまなベンチマークでのパフォーマンスを調べます。以下の表は、主要なメトリックの比較を提供します:
| ベンチマーク |
Llama 3.1 8B |
Llama 3.1 70B |
Llama 3.1 405B |
| MMLU |
66.7 |
79.3 |
85.2 |
| MMLU PRO (CoT) |
37.1 |
53.8 |
61.6 |
| AGIEval English |
47.8 |
64.6 |
71.6 |
| CommonSenseQA |
75.0 |
84.1 |
85.8 |
| Winogrande |
60.5 |
83.3 |
86.7 |
| BIG-Bench Hard (CoT) |
64.2 |
81.6 |
85.9 |
| ARC-Challenge |
79.7 |
92.9 |
96.1 |
| TriviaQA-Wiki |
77.6 |
89.8 |
91.8 |
| SQuAD |
77.0 |
81.8 |
89.3 |
| DROP (F1) |
59.5 |
79.6 |
84.8 |
主な観点:
- 一貫した改善:すべてのベンチマークにおいて、8Bから70B、そして405Bモデルに移行するにつれて明確な改善が見られます。
- 著しい向上:8Bから70Bへの飛躍は、70Bから405Bへのジャンプよりもより大きな改善を示しており、より高いパラメータ数では収益の減少が示唆されています。
- 405Bの優位性:405Bモデルは、その他のモデルよりも一貫して優れた性能を発揮します。特に、MMLU PROやAGIEvalなどの複雑な推論タスクでは、大幅なマージンで上回ることがあります。
指示に調整されたパフォーマンス
これらのモデルの指示に調整されたバージョンは、さらに素晴らしい結果を示しています:
| ベンチマーク |
Llama 3.1 8B Instruct |
Llama 3.1 70B Instruct |
Llama 3.1 405B Instruct |
| MMLU |
69.4 |
83.6 |
87.3 |
| MMLU (CoT) |
73.0 |
86.0 |
88.6 |
| MMLU PRO (CoT) |
48.3 |
65.1 |
73.3 |
| ARC-C |
83.4 |
94.8 |
96.9 |
| HumanEval |
72.6 |
80.5 |
89.0 |
| GSM-8K (CoT) |
84.5 |
95.1 |
96.8 |
| MATH (CoT) |
51.9 |
68.0 |
73.8 |
主な洞察:
- 指示に調整されたパフォーマンスの向上:すべてのモデルが指示に調整された場合、ベースと指示バージョンのギャップが特に8Bモデルでは顕著になります。
- 405Bは複雑なタスクで優れた性能を発揮:405Bモデルは、MATHやGSM-8Kなどの深い推論や数学的な能力を必要とするタスクでその強さを発揮します。
- 収益の減少:405Bモデルが常に他のモデルを上回っていますが、70Bと405Bの間のギャップは、8Bと70Bの間のギャップよりも小さい場合が多いことを示しています。
価格に関する考慮事項
さまざまなアプリケーションに使用するモデルを検討する際には、価格も重要な要素です。以下は既知の価格情報の概要です:
- Llama 3.1 405B:ホスティングと推論の月額費用は約$200-250
- Llama 3.1 70B:1Mトークンあたりの価格は約$0.90(入力と出力のトークンの3:1比率の合算)
- Llama 3.1 8B:具体的な価格は不明ですが、70Bモデルよりもかなり低いと予想されます
コスト効果の分析:
- 405Bモデル:最も高いパフォーマンスを提供する一方で、高い計算要件がありますので、主に企業や大規模なアプリケーションに適しています。トップクラスのパフォーマンスが必要なタスクでは、費用が正当化される場合があります。
- 70Bモデル:パフォーマンスとコストのバランスが取れています。8Bモデルよりもはるかに強力であり、405Bバリアントよりもアクセスしやすいです。
- 8Bモデル:多くのアプリケーションにとって最もコスト効果の高いオプションであり、特に予算の制約が主要な懸念事項の場合に適しています。
デプロイメントに関する考慮事項
これらのモデルのサイズと計算要件は、デプロイメントにおいて重要な役割を果たします:
405Bモデル:
- 専用ハードウェアが必要(たとえば、8xH100の複数のDGXシステムなど)
- FP16およびFP8のバージョンのいずれかで提供される可能性があり、FP8の方が費用対効果が高い可能性があります
- 一般消費者向けのGPUには適していません
70Bモデル:
- 高性能なGPUシステムで展開可能
- 中規模から大規模な組織にとってアクセスしやすい
8Bモデル:
- 展開オプションの面では最も汎用性があります
- 適切な最適化が施された一般消費者向けのGPUで実行する可能性があります
Llama 8B、70B、405Bの最適な使用ケースは何ですか?
パフォーマンスベンチマークと価格に関する考慮事項に基づいて、以下は異なる使用ケースに対する推奨事項です:
エンタープライズレベルのアプリケーション:
- ベストチョイス:405Bモデル
- 理由:計算リソースが十分な組織に適しており、複雑なタスクに強力なパフォーマンスを提供します
中規模の企業や研究機関:
- ベストチョイス:70Bモデル
- 理由:高いパフォーマンスと扱いやすい計算要件をバランスさせています
スタートアップや個人の開発者:
- ベストチョイス:8Bモデル
- 理由:多くのタスクに対して良好なパフォーマンスを提供し、コストとハードウェア要件の面では最もアクセスしやすいです
多言語アプリケーション:
- 推奨:より大きなモデル(70Bまたは405B)を使用すると、複数の言語でより優れたパフォーマンスが得られます
リソースに制約のある環境:
- ベストチョイス:8Bモデル(可能であれば量子化も検討)
- 理由:強力なハードウェアを必要とせず、まだまあまあの性能を提供できるよう最適化できます
結論
Llama 3.1シリーズは、異なるニーズとリソースに応じたモデルの範囲を提供しています。405Bモデルはパワフルであり、特定のベンチマークではGPT-4oなどのプロプライエタリモデルと競合し、時には上回ることがあります。しかし、そのデプロイメントの課題と費用のため、大規模なアプリケーションにのみ適しています。
70Bモデルはパフォーマンスとアクセス性のバランスが取れており、多くの組織にとって魅力的な選択肢です。8Bモデルよりも大幅な改善を提供しながら、405Bバリアントほど制約が少ないです。
8Bモデルは、パワフルさには劣りますが、多くのアプリケーションにとって依然として優れたオプションです。特にコストとデプロイメントの柔軟性が主な懸念事項の場合、多くのプロジェクトの出発点として優れています。
最終的な選択は、具体的なタスクの要件、利用可能な計算リソース、予算制約に依存します。AIのフィールドは急速に進化しており、将来にわたってこれらのモデルのバランスを変えるさらなる改善や最適化が期待されます。
💡
リージョン制限のない最もパワフルなAIモデル、Llama 3.1 405Bを使いたいですか?
Anakin AIはあなたの頼れるソリューションです!
Anakin AIは、Llama Models from Meta、Claude 3.5 Sonnet、GPT-4、Google Gemini Flash、
Uncensored LLM、DALLE 3、Stable Diffusionへのアクセスが1つの場所で可能で、
APIサポートにより簡単に統合できます!
はじめてみてください!👇👇👇



