情報が王様の時代において、話された言葉を正確に書き起こす能力は非常に価値があります。コンテンツクリエイターや転写者、研究者、メモの取得に時間を節約したい人など、OpenAIのWhisperは音声からテキストへの変換において強力な解決策を提供しています。この包括的なガイドでは、OpenAI Whisperの機能を最大限に活用し、話された言語を簡単かつ正確に書き写すプロセスを詳しく説明します。
OpenAI Whisperの紹介
音声からテキストへの変換は、私たちのデジタルライフの不可欠な一部となっています。インタビューや会議の書き起こし、動画やポッドキャストの字幕の生成など、信頼性と効率の高い転写ツールへの需要はかつてなく高まっています。人工知能の分野でリーダーであるOpenAIは、話された言語を書き起こすのに優れた自動音声認識(ASR)システムであるWhisperを開発しました。この記事は、Whisperの理解と効果的な活用のためのロードマップとなります。
Whisperの重要性
OpenAI Whisperの使用方法の詳細に入る前に、なぜそれが重要なのかを理解してみましょう。正確な音声からテキストへの変換には、さまざまな産業分野で様々な応用があります:
コンテンツ作成:コンテンツクリエイターは、録音されたインタビューやポッドキャストを書かれた記事に変換する際の手作業の時間を節約することができます。
アクセシビリティ:Whisperは、正確なビデオや音声コンテンツの字幕を提供することで、聴覚障害のある人々がデジタルコンテンツにアクセスしやすくなります。
研究:研究者は、インタビューやフォーカスグループのディスカッション、調査などを簡単に書き起こすことができ、より良い分析とデータの解釈が可能となります。
法的サービス:法律分野では、法廷の手続きや証言の迅速な書き起こしが行われ、事件の文書化とレビューを支援します。
医療:医療関係者は、効率的に患者のメモを書き起こし、正確かつ詳細な記録を確保することができます。
教育:教育者は、学生にアクセス可能な講義の書き起こしを提供することで、学習体験を向上させることができます。
金融:金融アナリストは、収益のコールを書き起こすことで、効果的に財務情報を追跡・分析することができます。
これらの様々な応用により、OpenAI Whisperのような信頼性の高い高品質な音声からテキストへの変換ツールへの需要はこれまでにないほど高まっています。以下のセクションでは、Whisperを使用する2つの方法を探求し、その精度を最大化し、制約事項に対処する方法について解説していきます。
方法1:Anakin AIのノーコードアプリビルダーを使用する
ステップ1:Anakin AIのノーコードアプリビルダーにアクセスする
- Anakin AIのウェブサイトにアクセスし、アカウントを作成します(まだアカウントを作成していない場合)。
- ログインしたら、ノーコードアプリビルダーのセクションに移動します。
- 「新しいアプリを作成」ボタンをクリックして、アプリの作成を開始します。
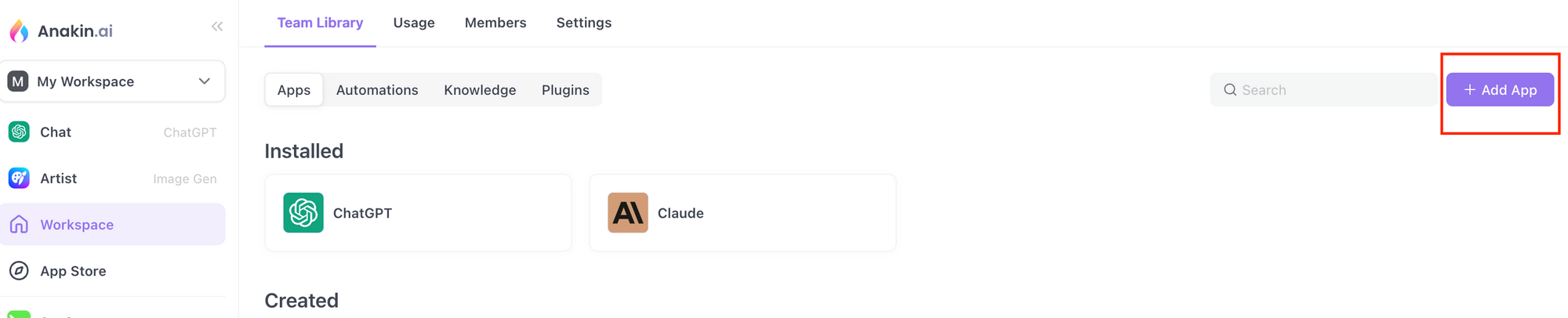
その後、アプリの名前を設定し、ワークフローオプションを選択し、続行ボタンをクリックします。
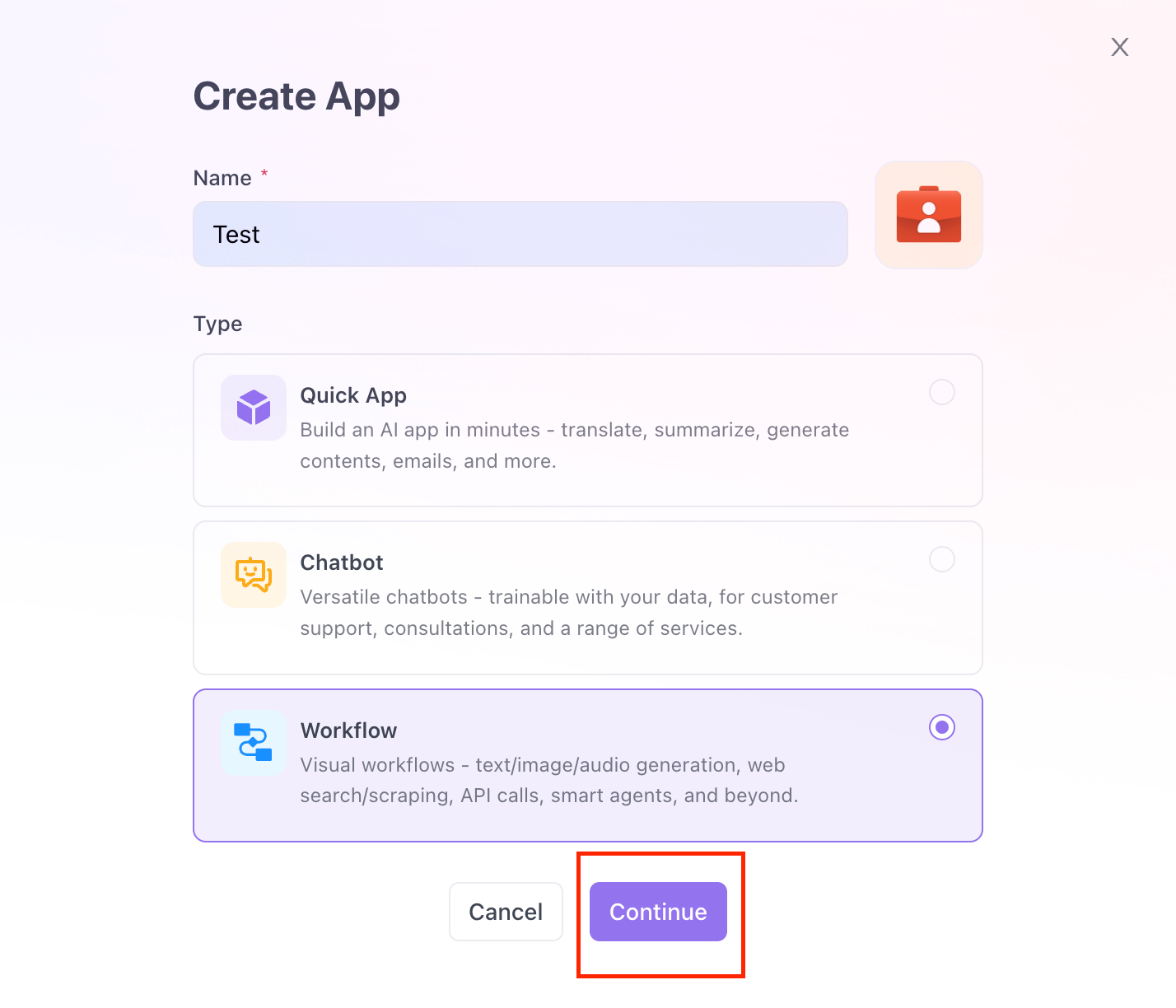
ステップ2:アプリにWhisper APIを追加する
アプリビルダーで、ステップを追加ボタンをクリックし、音声からテキストオプションを選択します。
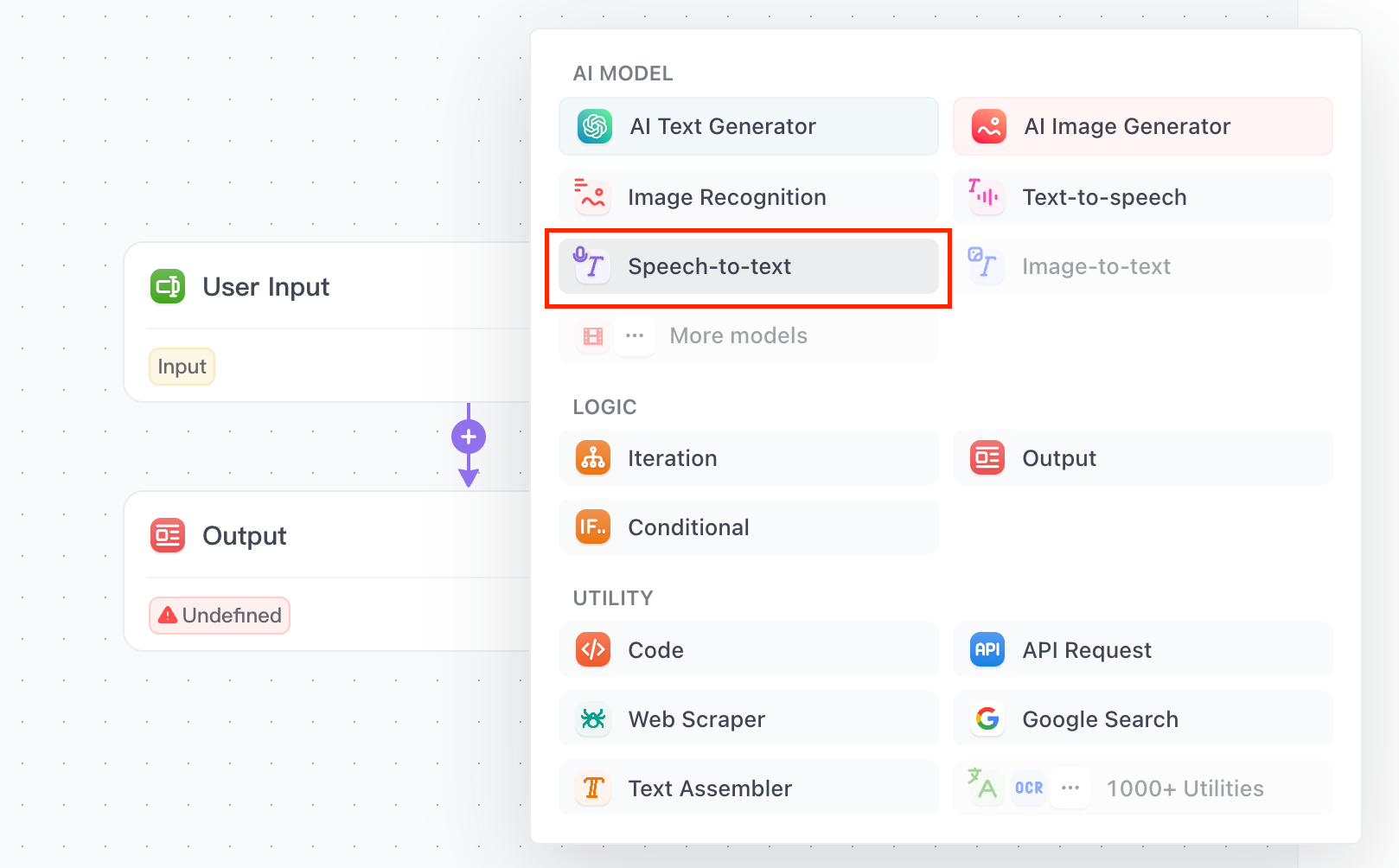
パネルの右側で、AIモデルとしてWhisperを選択できます!

ステップ3:アプリをビルドする
必要に応じてアプリのワークフローをカスタマイズします。Whisper ASRをアプリの他のモジュールやサービスに接続することができます。
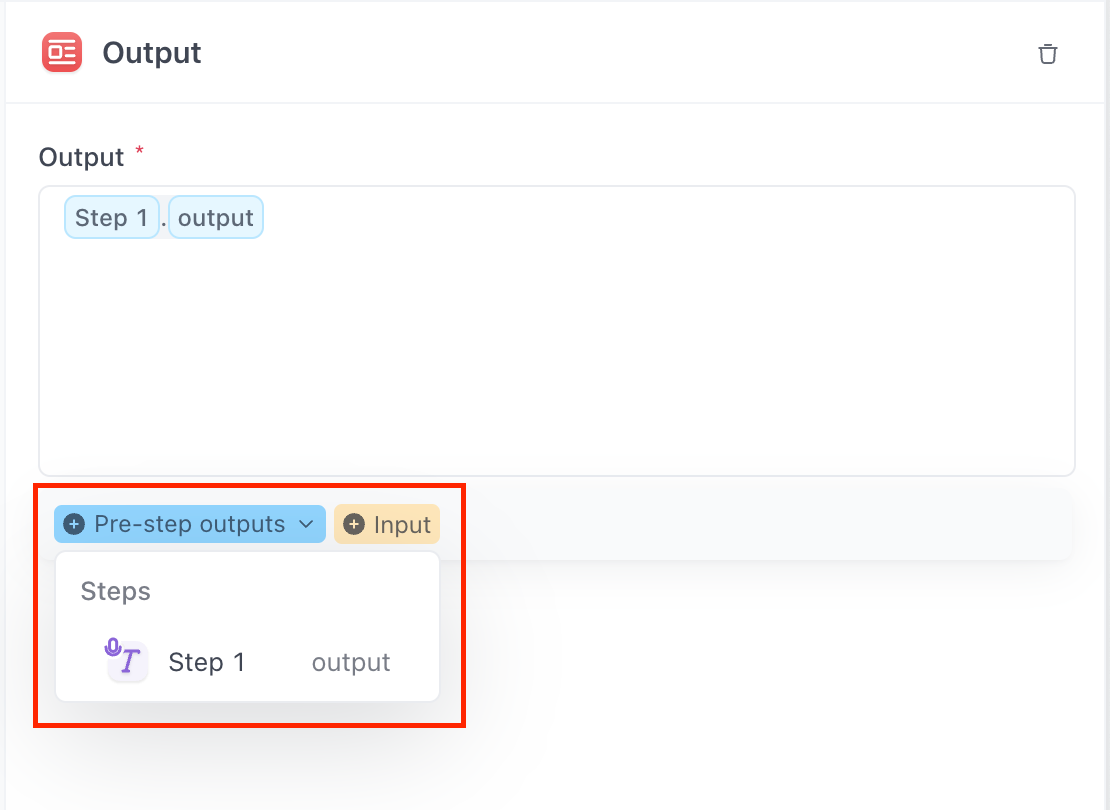
OutputステップでWhisperを出力ファイルとして選択することを忘れないでください!
ステップ4:アプリをテストして保存する

- アプリをテストするには、テストタブをクリックします。
- 満足したら、ワークスペースに保存ボタンをクリックして保存してください!
Anakin AIのノーコードアプリビルダーを使用すると、コーディングの知識がなくても、OpenAI Whisperを使用した音声からテキストへの変換を活用したカスタマイズアプリを簡単に作成することができます。この方法は、Whisperの利用方法をシンプルにしたいユーザーに最適です。
方法2:手動のインストールと使用
ステップ1:Whisperをインストールする
- コンピューター上でターミナルまたはコマンドプロンプトを開きます。
- 次のコマンドを使用して、必要な依存関係とWhisperパッケージをインストールします:
pip install git+https://github.com/openai/whisper.git
ステップ2:OpenAIアカウントの確認
- Whisperにアクセスするためには、アクティブなOpenAIアカウントが必要です。お持ちでない場合は、OpenAIのウェブサイトでサインアップし、APIキーを生成してください。
ステップ3:Whisperを実行する
- Whisperがインストールされたら、コマンドラインから実行して音声をテキストに書き起こすことができます。以下のコマンドを使って、実際のOpenAI APIキーで
your_api_keyを置き換えてください:
openai-whisper transcribe --api-key your_api_key "ここに話された内容を入力してください。"
ステップ4:音声ファイルの書き起こし
- Whisperは音声ファイルの書き起こしにも使用できます。例えば、
sample.wavという名前の音声ファイルを書き起こすには、次のコマンドを使用します:
openai-whisper transcribe --api-key your_api_key --audio sample.wav
ステップ5:その他の考慮事項
- より大きな、より強力なWhisperのバージョンが必要なアプリケーションでは、最適なパフォーマンスのためにGPU上でWhisperを実行することをおすすめします。
- Whisperには「large」と「medium」といった異なるバージョンがあり、それぞれ独自の機能と要件があります。
これらの手動のインストールと使用手順に従うことで、OpenAI Whisperを効果的に音声からテキストへの変換に使用することができ、プロセスに対してより多くの制御と柔軟性を得ることができます。
OpenAI Whisperの精度を向上させる方法
前のセクションでは、音声からテキストへの変換にOpenAI Whisperを使用する2つの方法を探求しました。 さて、トランスクリプションの精度を向上させるための重要な側面を見ていきましょう。Whisperは強力なツールですが、トランスクリプションテキストができるだけ正確になるようにするためには、いくつかの戦略を活用することができます。
異なるモデルを活用する
OpenAIでは、small、medium、largeなど、さまざまなWhisperモデルが提供されています。モデルの選択はトランスクリプションの正確さに大きな影響を与えることがあります。
ステップ1: 適切なモデルを選択する
- 自分のトランスクリプションのニーズを評価してください。より高い正確さが必要な場合は、「large」モデルを使用することを検討してください。
- 大きなモデルはより多くの処理リソースを消費する場合があるため、それをサポートできるハードウェアを確保してください。
「faster-whisper」プロジェクトを検討する
「faster-whisper」プロジェクトは、OpenAI WhisperモデルをCTranslate2で実装し、トランスクリプション時間を大幅に短縮するものです。
ステップ2: 「faster-whisper」を実装する
- 「faster-whisper」のGitHubリポジトリ(https://github.com/iwat/fast-whisper)を訪れ、この最適化バージョンの実装方法に関する手順を確認してください。
- 提供されたガイドラインに従って、「faster-whisper」を設定および実行し、迅速かつ効率的なトランスクリプションを行います。
特殊なタスクに向けたファインチューニング
ホギングフェース(Hugging Face)は、特定のデータセットや言語におけるWhisperモデルのファインチューニングにより、そのパフォーマンスを大幅に向上させることができます。ナチュラルランゲージプロセシングの人気プラットフォームであるHugging Faceは、Whisperモデルのファインチューニングに関するディスカッションと例を提供しています。
ステップ3: ファインチューニングを探索する
- Hugging Faceのウェブサイト(https://huggingface.co/)にアクセスし、Whisperモデルのページに移動します。
- ご利用のトランスクリプションのニーズに合わせてWhisperをファインチューニングするためのリソースやチュートリアルを探索します。
- モデルを効果的にファインチューニングするためのガイドラインに従ってください。
ハードウェアの最適化
ハードウェアの最適化はWhisperのパフォーマンスと正確性の向上に重要な役割を果たします。特に大きなモデルの場合にはさらに重要です。
ステップ4: ハードウェアをアップグレードする
- GPU(グラフィックス処理ユニット)を使用するなど、ハードウェアをアップグレードしてWhisperのパフォーマンスを大幅に向上させることを検討してください。
- 選択したWhisperモデルの要件をハードウェアが満たしていることを確認してください。
これらのアプローチを考慮することで、特定のユースケースにおけるOpenAI Whisperの精度向上に取り組むことができます。研究、コンテンツ作成、その他のアプリケーションで正確なトランスクリプションが必要な場合、これらの戦略はより正確な結果を得るのに役立ちます。
OpenAI Whisperの制限の理解
OpenAI Whisperは、音声をテキストに変換するための多目的で強力なツールですが、使用する際にはいくつかの制限があります。これらの制限を理解することは、期待値の管理や潜在的な課題の対処に重要です。
ファイルサイズの制限
Whisperは、トランスクリプト化できる音声ファイルのサイズを25MBに制限しています。この制限を超えるファイルがある場合、モデルはエラーを返し、より小さいファイルを提出するようにユーザーに促します。
トレーニングデータの依存性
機械学習モデルであるWhisperは、トレーニングされていないデータや方言の処理において、その性能が影響を受ける場合があります。これにより、トレーニングされていないデータや方言の処理において正確性が低下する可能性があります。
APIのレート制限
Whisper APIには公平な使用を確保するためのレート制限があります。最新の情報によれば、レート制限は1分あたり50リクエストであり、同時リクエスト数にも制限があります。トランスクリプションタスクを計画する際には、これらの制限に注意する必要があります。
既知のエラーモード
Whisperには既知のエラーモードがあり、開発者が対処する必要があります。これには、無音セグメントの問題、出力の反復、および幻覚(元のオーディオに存在しなかったコンテンツを生成するモデル)が含まれます。これらのエラーは、コンプライアンス、金融、医療、および法務などの特定の自動音声認識(ASR)ユースケースにおいて重要な問題となる可能性があります。
OpenAI Whisperの実際の応用
制限があるにもかかわらず、OpenAI Whisperは様々な現実世界の応用において重要な役割を果たしています:
ヘルスケア
- 医療記録の正確で簡潔な作成のための医療書き起こし。
法的サービス
- 法的ドキュメント作成のための裁判の進行、証言、およびクライアントインタビューの文書化。
金融
- 金融会議、収益報告、および投資家会議の分析および書き起こし。
教育
- アクセス可能な講義のトランスクリプト化、教育コンテンツの包括性向上。
コンテンツ作成
- ポッドキャスト、インタビュー、およびビデオコンテンツを書き起こした記事や字幕への変換。
Whisperの汎用性により、トランスクリプションタスクが効率化され、生産性が向上します。
OpenAI Whisperのベストプラクティス
OpenAI Whisperを最大限に活用するために、次のベストプラクティスを考慮してください:
データ準備
- トランスクリプションの正確性を向上させるために、オーディオデータが高品質で適切な形式であることを確認してください。
APIのレート制限の管理
- Whisper APIによって課されるレート制限に注意し、トランスクリプションタスクを適切に計画してください。
モデルの選択
- 正確性と処理能力の要件に基づいて、適切なWhisperモデル(small、medium、またはlarge)を選択してください。
品質検証
- 特に重要なアプリケーションにおいて、トランスクリプト化されたテキストの正確性を確認および検証してください。
結論
OpenAI Whisperは、スポークンランゲージをテキストに変換するための強力なソリューションとして、私たちの生活を革新しています。Whisperの応用範囲は広範であり、ヘルスケアから金融まで多岐にわたり、その可能性は否定できません。
この包括的なガイドでは、Whisperの始め方、正確性の向上、制限の理解、および実世界のシナリオへの適用方法を探求しました。ベストプラクティスに従い、その能力を認識することで、プロフェッショナルおよび個人の目標においてOpenAI Whisperのフルポテンシャルを引き出すことができます。
正確で効率的なトランスクリプションの需要がますます高まる中、OpenAIのWhisperは信頼できるパートナーとして、スピーチからテキストへの変換作業を容易にし、コンテンツ作成、アクセシビリティ、研究などの分野で新たな可能性を開拓しています。
Whisperの力を解き放ち、自信を持ってトランスクリプションを開始しましょう。