人間の言語の微妙なニュアンスを理解し、画像についての意味のある会話を展開するAIの世界を想像してみてください。それがLLaVAが現実化しようとしている世界です。オープンソースの生成AIモデルであるLLaVAは、視覚とテキストの理解というギャップを埋め、OpenAIのGPT-4とは異なる機能を提供しています。他のモデルとは異なり、LLaVAはユーザーが画像を簡単にチャット会話に統合できるようにし、画像の内容について議論したり、視覚的にアイデアを出し合ったりするプラットフォームを提供します。
シンプルなモデルアーキテクチャを活用し、トレーニングデータの必要量を大幅に削減することで、LLaVAは高度なAIをよりアクセス可能で効率的にするための大きな進歩です。これは単なる代替手段ではなく、オープンソースの協力がAIが達成することのできる領域の境界を押し広げる力を示すものです。
記事の概要:
- LLaVAの紹介とOpenAIのGPT-4V(ビジョン)に対するオープンソースの代替手段としてのユニークな位置づけ。
- LLaVAをそのウェブインターフェースを介して体験するためのユーザーフレンドリーガイド。AIとの相互作用をより視覚的で直感的にする。
- LLaVAをローカルで実行するシームレスなプロセス。先進的なAIが高性能なサーバーに限定されるのではなく、あなたの指先で利用できるようにする。
ローカルのLLMをローカルのラップトップで設定するのに時間を浪費する代わりに、APIを使用して実行したいですか?
心配しないでください、最新のオープンソースLLMオンラインをAnakin AIで試すことができます!現在、ブラウザ内でテストできる利用可能なすべてのオープンソースモデルの完全なリストはこちらです:
Claude | 無料のAIツール | Anakin.ai
You can experience Claude-3-Opus, Claude-3-Sonnet, Claude-2.1 and Claude-Instant in this application. Claude is an intelligent conversational assistant based on large-scale language models. It can handle context with up to tens of thousands of words in a single conversation. It is committed to prov…
LLaVAオンラインのユーザーエクスペリエンス
多くの人にとって、LLaVAの世界への入り口はウェブインターフェースです。これはモデルのユーザーセントリックなデザインの証です。ここでは、ユーザーは画像をアップロードし、LLaVAにそれらを説明するように依頼したり、それに基づいた質問に答えたり、創造的なアイデアを生成したりすることができます。たとえば、冷蔵庫の中身の写真があれば、LLaVAはフルーツサラダからスムージーやケーキまでさまざまなレシピを提案することができます。それは材料を識別し、関連するアイデアを提案する能力を示しています。
この対話は単純なクエリに限定されるものではありません。LLaVAの能力は、視覚要素に基づいた推論や推論ができる理由などにも及びます。ポスターから映画を特定する、スケッチからウェブサイトを作成する、または漫画で描かれたジョークを説明するなど、LLaVAのオンラインインターフェースは、AIが私たちの言葉だけでなく、私たちの世界も理解する未来を垣間見ることができます。
次のセクションでは、LLaVAの動作方法、ローカルでの実行のためのインストールプロセス、およびGoogle Colab上でHuggingFaceライブラリを使用して簡単なチャットボットアプリケーションを構築するための実践的なガイドについて詳しく説明します。LLaVAのレイヤーを明らかにしていく中で、ビジュアルと会話の経験を再定義するAIであるLLaVAの可能性を明らかにしていきます。
LLaVAをローカルで実行し、その技術的なアーキテクチャを理解するために、簡単な概念ガイドに進みましょう。リアルタイムまたは特定のソフトウェアドキュメントに直接アクセスすることはできませんが、類似のAIモデルやAIシステムの理論的な知識を基に、一般的な実践に基づいて解説します。
LLaVAの仕組み
LLaVAのアーキテクチャは、言語処理とビジュアル理解の革新的な融合であり、次の2つの主要なコンポーネントによって区別されます:
Vicuna:自然言語処理の進歩に基づいた事前学習された大規模な言語モデルです。人間のようなテキスト応答を理解し生成するために設計されています。
CLIP:ビジュアル入力を言語モデルが理解できる形式に変換する画像エンコーダです。これにより、モデルは画像を説明的なトークンや埋め込みに変換して「見る」ことができます。
データ処理のワークフロー:
- VicunaとCLIPの相互作用は、射影モジュールを介して合理化されており、アーキテクチャは強力で効率的です。
- 画像が入力されると、CLIPはそれを一連のトークンにエンコードします。これらのトークンは、任意のテキスト入力とともにVicunaに送られ、処理されて一貫性のある応答が生成されます。
- このプロセスにより、LLaVAはテキストとビジュアル情報をシームレスに結合することができ、より豊かでコンテキストに対応した相互作用が可能となります。
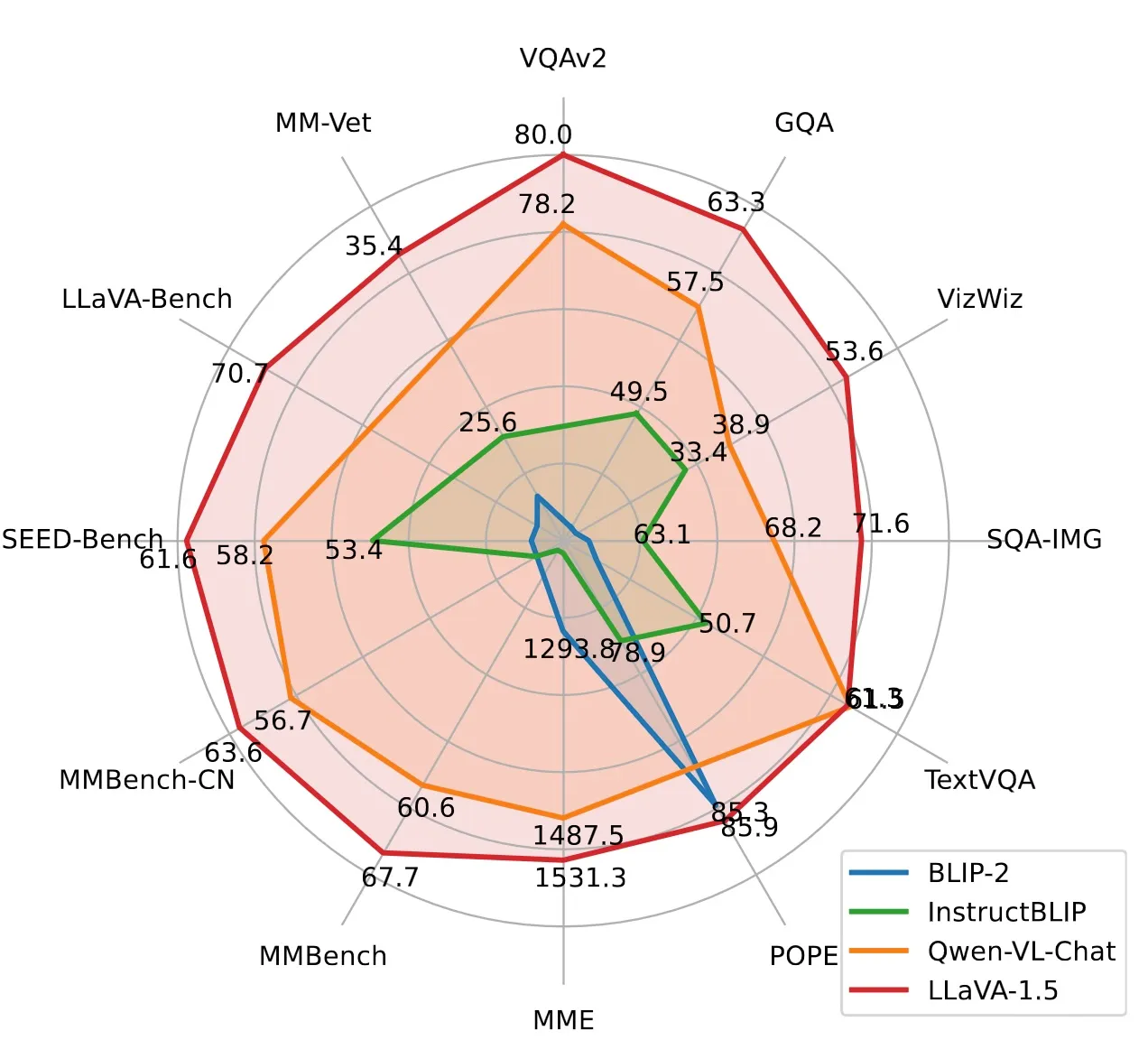 LLaVAベンチマーク
LLaVAベンチマークLLaVAをローカルで実行する方法
LLaVAをローカルで実行するための前提条件
システム要件:LLaVAをローカルマシンで実行するためには、通常次のような要件が必要です:
- 少なくとも8GBのRAM。
- 約4GBの空きディスク容量。
- 処理能力が優れたCPU。パフォーマンスを向上させるためには、GPUが推奨されますが必須ではありません。
- LLaVAはRaspberry Piでも実行できるため、その効率性と適応性が示されています。
インストール手順:
- マシンにPython 3.6以降がインストールされていることを確認します。
- LLaVAは他のAIモデルと同様に、Pythonパッケージを介して利用できることが想定されています。インストールには簡単なpipコマンドが必要な場合があります:
pip install llava
- 特定の依存関係や追加のセットアップが必要な場合は、正確なコマンドや追加のセットアップ手順については、LLaVAの公式のGitHubリポジトリやドキュメントを参照してください。
モデルの実行:
- インストールが完了したら、LLaVAを実行するには、Pythonスクリプトを実行するか、コマンドラインインターフェースを使用し、モデルバージョンやタスク(例:画像からテキストへの変換)などのパラメータを指定することがあります。
LLaVAをローカルで実行するための詳細な例
LLaVAをローカルで実行するには、PythonのTransformersライブラリを使用して統合します。まず、ライブラリをインストールし、次に特定のモデルIDを使用してLLaVAをロードし、効率化のために量子化を適用します。以下に簡潔なガイドを示します:
必要なライブラリのインストール:
!pip install transformers
import torch
from transformers import pipeline, BitsAndBytesConfig
効率的なロードのための量子化の設定:
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
LLaVAモデルのロード:
model_id = "llava-hf/llava-1.5-7b-hf"
pipe = pipeline("image-to-text", model=model_id, model_kwargs={"quantization_config": quantization_config})
説明的なプロンプトを使用して画像を処理する:
- PILを使用して画像を読み込みます。
- プロンプトを作成し、モデルにクエリを投げます。
- 生成されたテキストを表示します。
このシンプルなアプローチにより、リソースが限られたマシン(消費者向けハードウェアやRaspberry Piなど)でも、LLaVAと効率的に対話することができます。
Google ColabでLLaVAを実行する方法
HuggingFaceとGradioを使用したチャットボットの作成
Colab環境の設定:
- 必要なライブラリをインポートし、GradioとHuggingFace Transformersをインストールします。
!pip install gradio transformers
import gradio as gr
from transformers import pipeline
LLaVAモデルのロード:
- モデルIDを使用してHuggingFaceパイプラインを介してLLaVAをロードします。
model_id = "llava-hf/llava-1.5-7b-hf"
llava_pipeline = pipeline("image-to-text", model=model_id)
Gradioインタフェースの統合:
- 画像をアップロードし、テキストの応答を受け取るための使いやすいインタフェースを作成します。
def ask_llava(image, question):
response = llava_pipeline({"image": image, "question": question})
return response
iface = gr.Interface(fn=ask_llava, inputs=["image", "text"], outputs="text")
iface.launch()
チャットボットの起動と対話:
- すべてが設定されたら、Colab notebookで直接LLaVAのチャットボットと対話することができます。画像をアップロードし、質問をし、応答を受け取ります。
この例では、画像ベースの対話のためにLLaVAのトレーニングと適用の基本的なフレームワークを提供しています。実際の実装は、LLaVAライブラリの具体的な仕様と、HuggingFaceとGradioが提供する現在のAPIに依存します。互換性と最新の機能にアクセスするために、常に各ライブラリの最新のドキュメントを参照してください。
ローカルのLLMをローカルのラップトップで設定するのに時間を浪費する代わりに、APIを使用して実行したいですか?
心配しないでください、最新のオープンソースLLMオンラインをAnakin AIで試すことができます!現在、ブラウザ内でテストできる利用可能なすべてのオープンソースモデルの完全なリストはこちらです:
Claude | 無料のAIツール | Anakin.ai
You can experience Claude-3-Opus, Claude-3-Sonnet, Claude-2.1 and Claude-Instant in this application. Claude is an intelligent conversational assistant based on large-scale language models. It can handle context with up to tens of thousands of words in a single conversation. It is committed to prov…
結論
LLaVAを探索することで、ビジュアル理解と対話能力の融合がもたらすAIの未来の一端を垣間見ることができます。詳細なガイドを通じて、LLaVAのパワーをローカルで活用する方法、そのアーキテクチャについての理解、そしてその実用的な応用例を示しました。LLaVAが進化し続けるにつれて、複雑なツールをすべての人にアクセス可能にし、AIをさらに民主化することを約束しています。LLaVAの可能性を探るこの旅は、開発者だけでなく、AI、言語、ビジョンの交差点に興味を持つすべての人にとって、モデルの潜在能力を示しています。



