Llama 3は、Meta AIによって開発された大規模言語モデルの最新のブレークスルーです。その中には2つの傑出したバリアントがあります:80億のパラメータを持つLlama 3 80Bと、700億のパラメータを持つ巨大なLlama 3 700Bです。これらのモデルは、さまざまな自然言語処理タスクで印象的なパフォーマンスを発揮し、多くの注目を集めています。これらのモデルのパワーをローカルで活用したい場合、このガイドではollamaツールを使用してプロセスを実行する方法について説明します。
Llama 3とは何ですか? 技術的な詳細に入る前に、Llama 3 80Bモデルと700Bモデルの主な違いを簡単に見てみましょう。
Llama 3 80B Llama 3 80Bモデルは、パフォーマンスとリソース要件のバランスを取っています。80億のパラメータを持つことで、印象的な言語理解と生成能力を提供しながら、比較的軽量なままであり、ハードウェアの設定が控えめなシステム向けです。
Meta Llama-3-8B 日本語 | 無料のAIツール | Anakin.ai
ダウンロードや導入の手間なく、オンラインでMetaの Llama-3-8B モデルの力を体験できます。クリック一つで簡単に試せます!
Llama 3 700B 一方、Llama 3 700Bモデルは真の巨人で、驚異的な700億のパラメータを誇っています。この増加した複雑さは、コード生成、クリエイティブライティング、さらにはマルチモーダルなアプリケーションなど、さまざまなNLPタスクでのパフォーマンス向上につながります。ただし、より多くのコンピュータリソースが必要であり、十分なメモリとGPUのパワーを備えた堅牢なハードウェア構成が必要です。
Meta Llama-3-70B 日本語 | 無料のAIツール | Anakin.ai
MetaのLlama 3-70Bモデルの圧倒的な性能を、今すぐ手間なく体験してみませんか?
Anakin.ai - ワンストップのAIアプリプラットフォーム
コンテンツ、画像、動画や音声などを生成可能。ワークフローの自動化、カスタムAIアプリ作成やスマートなAIエージェントにも対応可能!あなた専属のAIアプリワークススペース
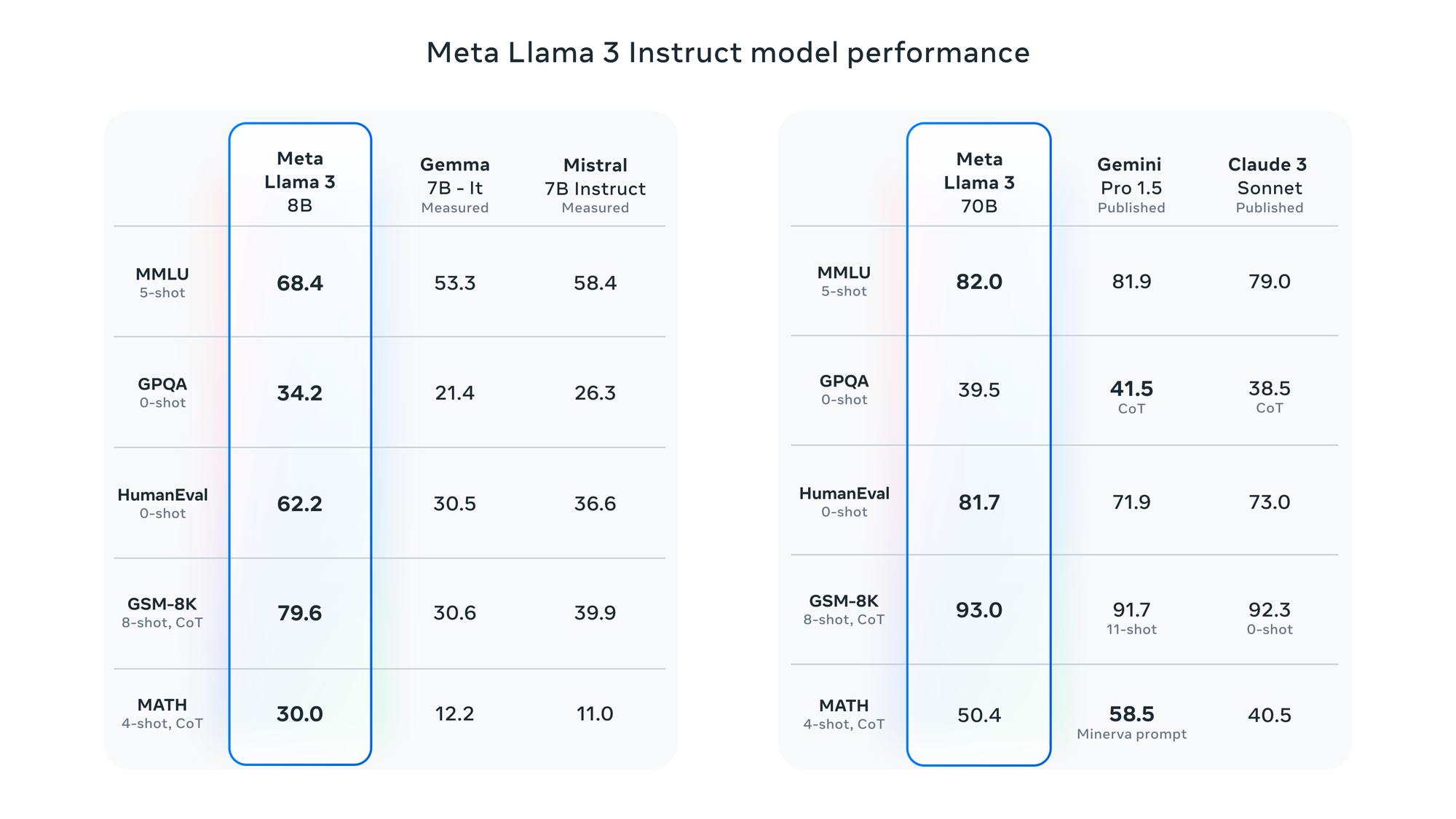
Llama 3のパフォーマンスベンチマーク Llama-3-8BおよびLlama-70Bのベンチマーク 決断を支援するために、さまざまなNLPタスクでLlama 3 80Bモデルと700Bモデルを比較するいくつかのパフォーマンスベンチマークをご紹介します:
タスク
Llama 3 80B
Llama 3 700B
テキスト生成
4.5
4.9
質問応答
4.2
4.8
コード補完
4.1
4.7
言語翻訳
4.4
4.9
要約
4.3
4.8
注:スコアは、1から5のスケールで表現されており、5が最高のパフォーマンスを示します。
上記のように、Llama 3 700Bモデルは、すべてのタスクで8Bバリアントよりも一貫して優れたパフォーマンスを発揮しますが、より高い計算リソースを要します。ただし、8Bモデルでも印象的な結果を提供し、ハードウェアリソースに制限がある場合は、より実用的な選択肢となる場合があります。
Llama 3をローカルで実行するための前提条件 Llama 3のモデルをローカルで実行するには、以下の前提条件を満たす必要があります。
ハードウェア要件 RAM: Llama 3 8Bの場合は最小16GB、Llama 3 70Bの場合は64GB以上 GPU: 最小8GB VRAMの強力なGPU、preferablyはNVIDIA GPUでCUDAサポート ディスク容量: Llama 3 8Bは約4GB、Llama 3 70Bは20GB以上 ソフトウェア要件 Docker: ollamaはDockerコンテナを使用してデプロイ CUDA: NVIDIA GPUを使用する場合は、適切なCUDAバージョンをインストールして設定する必要がある Ollamaを使ってLlama 3をローカルで実行する方法
ollamaは、Llama 3のモデルをローカルで実行するプロセスを簡素化するツールです。以下の手順に従ってインストールしてください。
ターミナルまたはコマンドプロンプトを開きます。 以下のコマンドを実行して、ollamaのインストールスクリプトをダウンロードして実行します: curl -fsSL https://ollama.com/install.sh | sh
このスクリプトはインストールプロセスを処理し、依存関係のダウンロードと必要な環境の設定を行います。
Llama 3モデルのダウンロード ollamaがインストールされたら、ローカルで実行したいLlama 3モデルをダウンロードできます。以下のコマンドを使用します:
Llama 3 8Bの場合:
ollama download llama3-8b
Llama 3 70Bの場合:
ollama download llama3-70b
70Bモデルのダウンロードには時間がかかり、リソースも多く必要となることに注意してください。
Llama 3モデルの実行 モデルのダウンロードが完了したら、ollamaを使ってLlama 3モデルをローカルで実行できます。
Llama 3 8Bの場合:
ollama run llama3-8b
Llama 3 70Bの場合:
ollama run llama3-70b
これにより、それぞれのモデルがDockerコンテナ内で起動し、コマンドラインインターフェイスからプロンプトを入力して応答を生成できるようになります。
Llama 3モデルの高度な使用方法 ollamaには、モデルの使用経験を向上させるための様々な高度なオプションと設定があります。
Fine-tuning : 独自のデータでLlamaモデルをファインチューニングし、特定のタスクやドメインに合わせてカスタマイズできます。量子化 : メモリフットプリントを削減し、推論速度を向上させるためにモデルを量子化できます。マルチGPUサポート : 複数のGPUを活用して、推論とファインチューニングのプロセスを高速化できます。コンテナ化 : ファインチューニングや量子化したモデルをコンテナ化し、さまざまなシステムで簡単に共有およびデプロイできます。Llama 3モデルのファインチューニング ファインチューニングは、Llama 3などの事前学習済み言語モデルを特定のタスクやドメインに適応させるプロセスです。これにより、対象の用途に合わせてモデルのパフォーマンスと精度を大幅に向上させることができます。
ファインチューニングのプロセス データセットの準備 : 対象のタスクやドメインに関連する高品質なデータセットを収集します。通常、入力-出力のペアや、プロンプトと期待される応答のコレクションとして整形されます。事前学習モデルの読み込み : ファインチューニングする8Bまたは70BのプレトレーニングされたLlama 3モデルを読み込みます。ハイパーパラメータの設定 : 学習率、バッチサイズ、エポック数など、ファインチューニングプロセスに適したハイパーパラメータを決定します。ファインチューニング : データセットを使ってモデルのパラメータを更新し、ファインチューニングを実行します。評価 : 保持されたテストセットや関連ベンチマークを使ってファインチューンされたモデルのパフォーマンスを評価します。デプロイ : ターゲットのアプリケーションや用途にファインチューンされたモデルをデプロイします。ollamaでのファインチューニング ollamaは、Llama 3モデルをローカルでファインチューニングする便利な方法を提供しています。以下のようなコマンドを使用できます:
ollama finetune llama3-8b --dataset /path/to/your/dataset --learning-rate 1e-5 --batch-size 8 --epochs 5
このコマンドは、Llama 3 8Bモデルを指定のデータセットでファインチューニングします。学習率を1e-5、バッチサイズを8、エポック数を5に設定しています。これらのハイパーパラメータは、ご自身のニーズに合わせて調整できます。
llama3-8bの部分をllama3-70bに置き換えると、より大きな70Bモデルをファインチューニングできます。
Azureでのllama 3の使用 ollamaを使ってローカルでLlama 3モデルを実行できますが、Microsoft Azureのクラウドリソースを活用してこれらのモデルにアクセスしてファインチューニングすることもできます。
Azure OpenAI Service Microsoft Azureは、Azure OpenAI Serviceを提供しており、Llama 3を含む様々な言語モデルにアクセスできます。このサービスを使うことで、ローカルのハードウェアリソースを必要とせずにLlama 3を自社のアプリケーションに統合し、その機能を活用できます。
Llama 3をAzureで使用するには、以下の手順に従う必要があります:
Azureアカウントの作成 : まだAzureアカウントを持っていない場合は、アカウントを作成します。Azure OpenAI Serviceの登録 : AzureポータルでAzure OpenAI Serviceに登録します。APIキーの取得 : Llama 3モデルにアクセスするためのAPIキーを生成します。アプリケーションへの統合 : 提供されたSDKやAPIを使ってLlama 3をアプリケーションに統合し、自然言語処理の機能を活用します。Azure Machine Learning また、Azure Machine Learningを使ってAzureのスケーラブルなコンピューティングリソースでLlama 3モデルをファインチューニングすることもできます。この方法では、大規模な言語モデルのトレーニングと
Azure Machine Learning Workspaceの設定 : AzureポータルでAzure Machine Learning Workspaceを作成します。データセットのアップロード : ファインチューニング用のデータセットをAzureストレージアカウントまたはAzure Machine Learningデータストアにアップロードします。コンピューティングクラスターの作成 : Llama 3のファインチューニングに必要なGPUリソースを持つコンピューティングクラスターをプロビジョニングします。Llama 3のファインチューニング : Azure Machine Learningの組み込みツールやカスタムコードを使って、データセットを使ってLlama 3モデルをファインチューニングします。分散トレーニングにはコンピューティングクラスターを活用できます。ファインチューンされたモデルのデプロイ : ファインチューニングが完了したら、Azure Machine Learningの展開機能を使ってファインチューンされたLlama 3モデルをWebサービスとしてデプロイするか、アプリケーションに統合できます。Azureのクラウドリソースを活用することで、ローカルハードウェアを必要とせずにLlama 3モデルにアクセスしてファインチューニングできるようになります。スケーラブルなコンピューティング能力と簡単なデプロイオプションを活用できます。
結論 ollamaのようなツールのおかげで、Llama 3 8BおよびLlama 3 70Bのような大規模な言語モデルをローカルで実行することが可能になってきました。このガイドの手順に従えば、自身のハードウェアでこれらの最先端モデルの力を活用し、自然言語処理タスク、研究、実験の可能性を開くことができます。
開発者、研究者、愛好家を問わず、Llama 3モデルをローカルで実行できるようになることで、人工知能分野の探求と革新の新しい道が開かれます。適切なハードウェアとソフトウェアの設定さえあれば、言語モデルの可能性の限界を押し広げ、この分野の発展に貢献できるでしょう。
70Bモデルは並外れたパフォーマンスを提供しますが、8Bモデルはケイパビリティとリソース要件のバランスが取れており、ハードウェア構成がより控えめな人にも適しています。最終的には、2つのモデルのどちらを選択するかは、ご自身のニーズ、利用可能なリソース、そして受け入れられるトレードオフによって決まります。
Anakin.ai - ワンストップのAIアプリプラットフォーム
コンテンツ、画像、動画や音声などを生成可能。ワークフローの自動化、カスタムAIアプリ作成やスマートなAIエージェントにも対応可能!あなた専属のAIアプリワークススペース