人工知能の常に進化する風景の中で、Llama 2は革新の兆しとして際立っています。先進的な大規模言語モデル(LLM)であるLlama 2は、テック愛好家、開発者、AI愛好家の想像力を掴んでいます。人間らしいテキストの理解と生成能力は、魅力的なコンテンツの作成からコーディング支援まで、さまざまな応用領域を開拓しました。しかしながら、Llama 2の真の魔法はローカルで実行されるときに発揮され、ユーザーには前例のないプライバシー、コントロール、オフラインの利便性が提供されます。これがLM Studioです。MacとWindowsのユーザーのためにLlama 2などのLLMをローカルで簡単に展開するゲームチェンジャーです。先進的なAIとユーザーフレンドリーなソフトウェアの融合により、個人およびプロフェッショナルなAIの利用法に新たな時代が訪れました。
これらの事前構築されたLlamaチャットボットをお試しください:
キーポイントのまとめ
- Llama 2:先進的なAI機能により、コンテンツ作成やコーディング支援などを革新しています。
- ローカル展開: Llama.cpp、Ollama、MLC LLMなどのツールを使用して、Llama 2のフルポテンシャルを自分のデバイスで活用し、プライバシーとオフラインアクセスを確保します。
- LM Studio:この使いやすいプラットフォームは、MacとWindowsでのLlama 2および他のLLMのローカル展開を簡素化し、先進的なAIをこれまで以上に利用しやすくしています。
- Anakin AI:ローカルのインストールにコミットすることなく、Llamaモデルを探求したい場合、Anakin AIはテストや実験に便利なオンラインプラットフォームを提供しています。
Llama 2モデルとは何ですか?
Meta AIが開発およびリリースしたLlama 2モデルは、大規模言語モデル(LLM)の領域での重要な進歩を表しています。これらのモデルは、一般的および特定のアプリケーションに合わせたさまざまな機能を提供する7兆から700兆のパラメータを備えています。Llama 2は、人間らしいテキスト応答を生成するために最適化された自己回帰的言語モデルとして設計されており、さまざまな自然言語処理タスクにおいて重要なツールとなっています。
技術仕様と機能
- バリエーション: Llama 2は、事前学習および微調整されたバリエーションを含む複数のバージョンで提供されており、さまざまなニーズと使用事例に対応しています。
- アーキテクチャ:Llama 2のコアは最適化されたトランスフォーマーアーキテクチャに基づいており、監視付き微調整(SFT)や人間フィードバックによる強化学習(RLHF)などの技術を使用して、モデルの出力をヘルプフルさと安全性に関する人間の好みに合わせて調整します。
- トレーニングデータ:モデルは、公開されているさまざまなオンライン情報源から取得した2兆のトークンからなる多様なデータセットでトレーニングされており、さまざまな主題とコンテキストの幅広い理解を保証しています。
Llama 2内の専門モデル
- Llama Chat:Llama 2の微調整版であるLlama Chatは、対話型の使用事例に最適化されており、対話能力を向上させるために100万以上の人間による注釈付きの例に対してトレーニングされています。
- Code Llama:コード生成に特化したCode Llamaは、Llama 2アーキテクチャ上に構築され、Python、C ++、Javaなどの一般的なプログラミング言語をサポートする5000億トークンのコードでトレーニングされています。
AI開発への重要性
Llama 2モデルは、オープンソース性、さまざまなベンチマークに対する高性能、および商業および研究目的の両方に適応できる柔軟性という点でAIの風景で際立っています。文脈に即したテキストの理解と生成能力に加え、開発における倫理的な考慮を備えることにより、Llama 2は技術における言語モデルの能力と応用を前進させるための重要な開発として位置付けられています。
Llama 2モデルとその応用に関する詳細な情報については、Meta AIの公式ウェブサイトで提供されるリソースをご覧ください。
クイック検索に基づいて、以下のことがわかりました。
1. Anakin AIを使用してLlama 2を実行する方法
Llama 2モデルをワークフローに統合する最も簡単な方法の1つは、Anakin AIを使用することです。
AIモデルを搭載したAIアプリを作成したいですか?心配ご無用です。単に新しいチャットボットやワークフローを作成し、希望するAIモデルをオプションとして選択します。例えば、Llama 13B、Llama 70Bモデルをすぐに試したい場合、Anakin AIを使用して1クリックでアプリを構築できます。

2. Llama.cppを使用してLlama 2をローカルで実行する方法
Llama.cppは、Georgi Gerganovによって開発されたライブラリで、CPU上で大規模な言語モデル(LLM)を効率的に実行するために設計されており、GPUへのアクセス権のないユーザーに特に有益です。さまざまなLLMに対して高速な推論を提供し、llama-cpp-pythonパッケージを介してPythonと統合することができます。これにより、Pythonの幅広いライブラリをプロジェクトで活用することができます。
Llama.cppのセットアップ
インストール:まず、llama-cpp-pythonパッケージをインストールする必要があります。これは、llama.cppライブラリのPythonバインディングを提供し、Python環境での使用を容易にします。
次のコードを使用して、pipでインストールできます:
pip install llama-cpp-python
詳細なインストール手順については、llama-cpp-pythonのドキュメントを参照してください。
LLMのダウンロードとロード: Hugging FaceなどのソースからGGML形式のモデルをダウンロードする必要があります。モデルは量子化されていることを確認し、メモリ要件を減らす一方で性能に大きな影響を与えないようにします。以下に、モデルをダウンロードしロードするための例のコードスニペットを示します:
import os
import urllib.request
from llama_cpp import Llama
def download_file(file_link, filename):
if not os.path.isfile(filename):
urllib.request.urlretrieve(file_link, filename)
print("ファイルのダウンロードに成功しました。")
else:
print("ファイルは既に存在しています。")
ggml_model_path = "ここにモデルのリンクを入力"
filename = "ここにモデルのファイル名を入力"
download_file(ggml_model_path, filename)
llm = Llama(model_path=filename, n_ctx=512, n_batch=126)
"ここにモデルのリンクを入力"と"ここにモデルのファイル名を入力"を、実際のGGMLモデルのリンクとファイル名に置き換えてください。
テキストの生成: モデルがロードされたら、モデルにプロンプトを渡すことでテキストを生成することができます。次の例では、テキストを生成するためのシンプルな関数です:
def generate_text(prompt, max_tokens=256, temperature=0.1, top_p=0.5, echo=False, stop=["#"]):
output = llm(prompt, max_tokens=max_tokens, temperature=temperature, top_p=top_p, echo=echo, stop=stop)
return output["choices"][0]["text"].strip()
この関数では、トークンの最大数、ランダム性のための温度、および停止条件など、生成プロセスのカスタマイズが可能です。
3. MacでOllamaを使用してローカルでLlama 2を実行する方法

Ollamaは、シンプルさ、コスト効率性、プライバシー、柔軟性などの点で優れており、クラウドベースのLLMソリューションに対して遅延やデータ転送の問題をなくし、幅広いカスタマイズが可能です。
MacでOllamaをセットアップする
ステップ1。Ollamaのウェブサイトにアクセスし、ollama dmg パッケージをダウンロードします。
ステップ2。Ollamaが現在サポートしている利用可能な llama モデルのいずれかをインストールします。ターミナルで次のコマンドを実行するだけです:
ollama run llama2チャットのファインチューニングなしで、事前トレーニング済みの llama2 をテストしたい場合は、次のコマンドを使用してください:ollama run llama2:text
Ollamaは、標準で多くのLlama 2バージョンをサポートしています。パラメータやシステムのメモリに応じて、ご希望のオプションのうちの1つを選択してください:
- 7bモデルは一般的に少なくとも8GBのRAMを必要とします
- 13bモデルは一般的に少なくとも16GBのRAMを必要とします
- 70bモデルは一般的に少なくとも64GBのRAMを必要とします
一般的に、リソースの限られたローカル環境を使用している場合、7B-Chat_Q4_K_Mモデルを実行することをおすすめします。
ollama run llama2:7b-chat-q4_K_MDockerを使用してOllamaをセットアップする
Dockerのインストール:まず、システムにDockerがインストールされていることを確認してください。インストールされていない場合は、公式DockerのWebサイトからダウンロードしてインストールしてください。
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
Ollama Dockerイメージの取得:Dockerがセットアップされたら、ターミナルで以下のコマンドを実行してOllamaイメージを取得します:
docker pull ollama/ollama
Ollamaの実行:Ollamaを起動するには、次のコマンドを実行します:
docker run -it ollama/ollama
このコマンドはOllamaを起動し、モデルとの対話を開始できます。
Ollamaでのモデルの操作
- モデルの一覧表示:`ollama list`を使用して利用可能なモデルを表示します。
- モデルの実行:特定のモデルと対話するには、`ollama run
`を使用します。 - モデルの停止:モデルを停止する必要がある場合は、`ollama stop
`を使用します。
異なるプラットフォーム上のOllama
OllamaはLinuxに限らず、WindowsおよびmacOSユーザーにも対応しており、幅広い利用環境が可能です。
WindowsでのOllamaのセットアップ
- Windows用の実行可能ファイルのダウンロード:OllamaのGitHubリポジトリにアクセスし、最新のWindows用実行可能ファイルをダウンロードします。
- Ollamaのインストール:ダウンロードした実行可能ファイルを実行し、インストールを完了させます。
- Ollamaの実行:コマンドプロンプトを開き、Ollamaのインストールディレクトリに移動し、
ollama.exe runを実行します。
OllamaでのGPUの活用
計算量の多いタスクでは、OllamaはGPUアクセラレーションを活用してパフォーマンスを向上させるため、NVIDIAおよびAMDのGPUをサポートしています。お使いのGPUに適切なドライバがインストールされていることを確認し、次のコマンドに--gpuフラグを追加してGPUサポートを有効にします:
ollama run --gpu <model_name>
このコマンドにより、GPUアクセラレーションが有効になり、モデルの推論速度が大幅に向上します。
OllamaとPythonの統合
OllamaはPythonとの互換性があり、データサイエンスや機械学習のプロジェクトでの有用性が高まります。Ollama Pythonパッケージ(pip install ollama)をインストールした後、OllamaモデルをPythonスクリプトに簡単に組み込むことができ、コードベース内で直接対話や推論を行うことができます。
Windows用のLlama 2を実行するための提供された手順を記事に組み込む場合、このセクションをどのように構成して詳細に説明するかを次に示します:
4. WindowsでLlama 2を実行する方法(Llama.cppを使用)

Windowsエコシステムの場合、Llama 2をローカルにセットアップするにはいくつかの準備ステップが必要ですが、強力なAIツールが手の届く範囲にあります。以下は、初めての方への詳細なガイドです:
事前インストール要件
Nvidia GPU ユーザー:Nvidia GPUをお持ちの場合、パフォーマンスを向上させるためにGPUアクセラレーションを利用するために、まずCUDAツールキットをインストールする必要があります。CUDAツールキットは、公式のNvidiaのWebサイト「CUDA Toolkit Download」からダウンロードできます。
モデルのダウンロード:次に、Llama 2モデルが必要です。 以下のリンクから、ハギングフェース(Hugging Face)からモデルをダウンロードできます:Llama 2-13Bモデルのダウンロード。モデルを後の手順で簡単にアクセスできる場所に保存してください。
WindowsでのLlama 2のインストール(ステップバイステップガイド)
Windows Terminalを開き、次のコマンドをPowerShellで使用します:
Llama.cppリポジトリをクローンします:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
ビルド環境を準備します:
mkdir build
cd build
CMakeを使用してビルドファイルを生成し、CUDAを有効にしてビルドします(Nvidia GPUを使用している場合):
cmake .. -DLLAMA_CUBLAS=ON
cmake --build . --config Release
Releaseディレクトリに移動し、モデルをセットアップします:
cd bin/Release
mkdir models
mv モデルをダウンロードしたフォルダのパス .\models
すべてが正しくセットアップされていることを確認するため、テストプロンプトでLlama 2を実行します:
.\main.exe -m .\models\llama-2-13b-chat.ggmlv3.q4_0.bin --color -p "Hello, how are you, llama?" 2> $null
コマンドの2> $null部分は、デバッグメッセージをターミナル上で抑制して出力をきれいに保つために使用されます。
PowerShell関数で将来の使用を簡素化する
Llama 2の実行プロセスを効率化するために、PowerShell関数を定義できます:
PowerShellプロファイルをテキストエディタで開きます(たとえば):
notepad $PROFILE
次の関数をプロファイルに追加し、必要に応じてパスを調整してください:
function llama {
.\main.exe -m .\models\llama-2-13b-chat.ggmlv3.q4_0.bin -p $args 2> $null
}
この関数を使用すると、PowerShellターミナルでllama "promptの内容"と入力することで、Llama 2のプロンプトをより便利に実行できます。
これらの手順により、Windowsユーザーはインターネット接続を必要とせずにさまざまなタスクにAIの能力を活用できるLlama 2のローカルな利点を享受できます。このセットアップは、高度なAIモデルへのアクセスの民主化だけでなく、個人のカスタマイズ可能なAI体験も提供します。
5. MLC LLMを使用したLlama 2のローカルでの実行
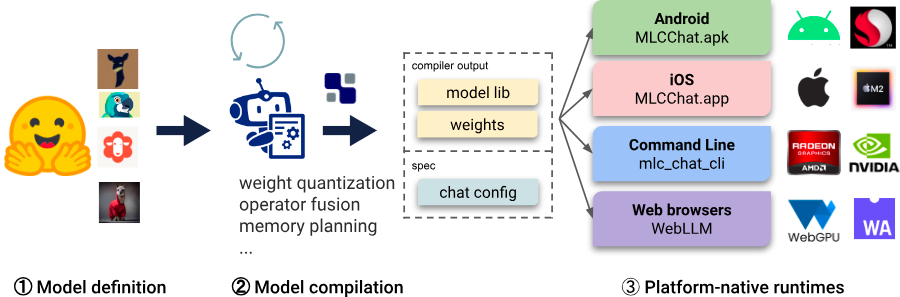
MLC LLMは、効率的な推論のためのプリコンパイルされたバイナリを活用し、ローカルでLlama 2モデルを提供するスムーズなアプローチを提供します。以下は、簡略化されたステップバイステップガイドです:
- GPUを選択します:使用するGPUのタイプを決定します。例えば、NVIDIAのA10G GPUの場合は"a10g"とします。
- Llamaモデルのサイズを選択します:使用するLlamaモデルのサイズを決定します。たとえば、7兆パラメーターの場合は"7b"、13兆パラメーターの場合は"13b"とします。
- 環境をセットアップします:MLCのCUDA要件に対応したNVIDIA CUDAイメージを使用します。たとえば、"nvidia/cuda:12.2.2-cudnn8-runtime-ubuntu22.04"とします。
- 依存関係をインストールします:必要なパッケージやライブラリ(git、curl、mlc-ai-nightly-cu122、mlc-chat-nightly-cu122などのPythonパッケージ)をインストールします。
- モデルとライブラリをダウンロードします:必要なライブラリと選んだ特定のLlamaモデルをGitHubや他のソースからクローンします。
- 推論関数を実装します:mlc_chatのChatModuleを使用してモデルとライブラリをロードし、入力プロンプトを処理して応答を生成する関数を作成します。
- モデルを実行します:選択したGPU上でセットアップを実行し、Llama 2とローカルで対話します。
より詳細な手順と正確なコマンドについては、公式MLCドキュメントを参照してください。
6. LM Studioを使用したLlama 2のローカルでの実行
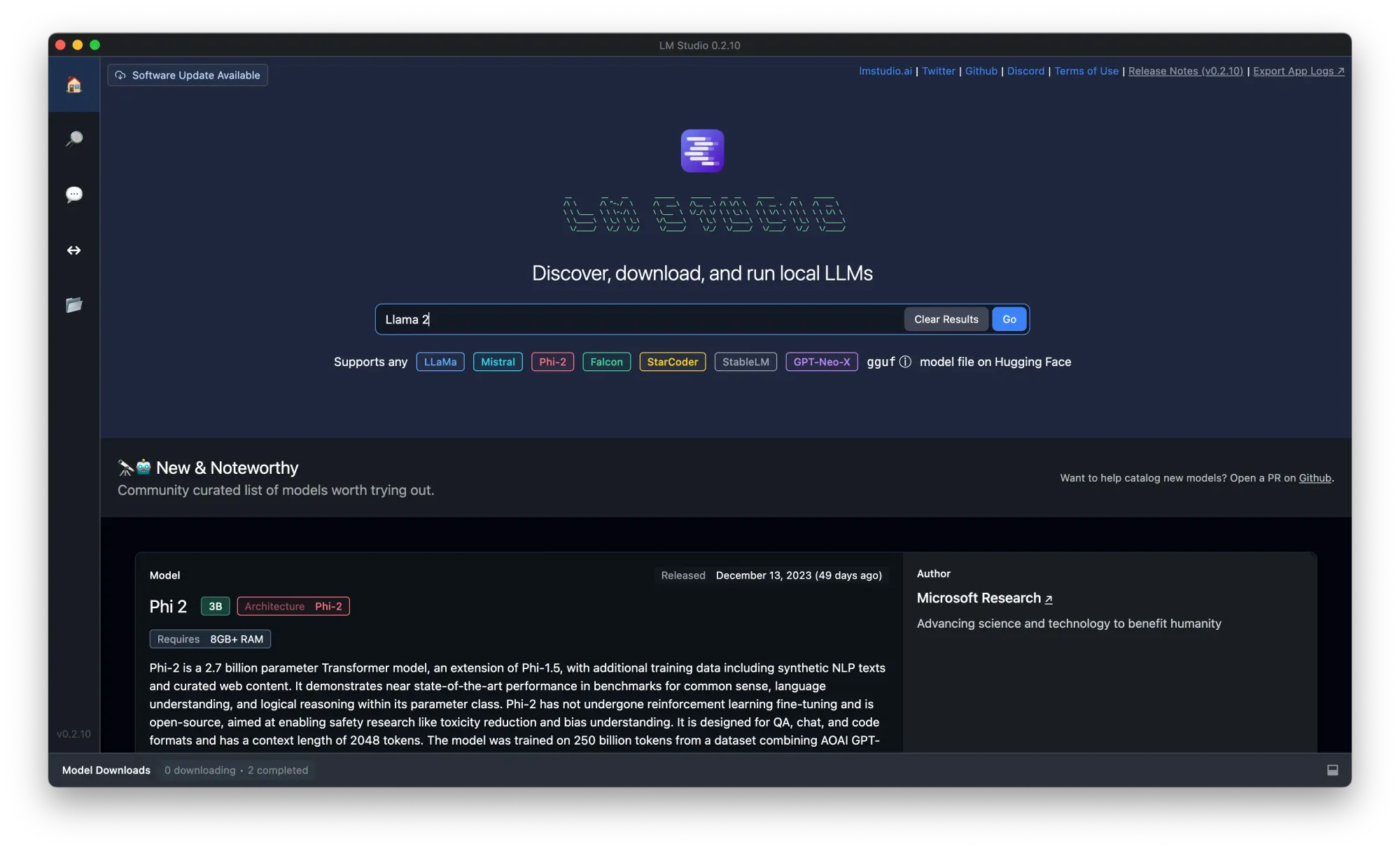
LM Studioは、ローカルマシン上でLlama 2を含むさまざまなLLMを実行することを簡素化します。ただし、即座の検索結果ではLM Studioの具体的な手順を見つけることができませんでした。一般的に、LM Studioを使用する場合は次のような手順となります:
ステップ1. LM Studioをダウンロードしてローカルにインストールします。
ステップ2. 検索バーで「llama」と検索し、量子化バージョンを選択し、「ダウンロード」ボタンをクリックします。この場合、「The Block, llama 2 chat 7B Q4_K_M gguf」をダウンロードすることにします。
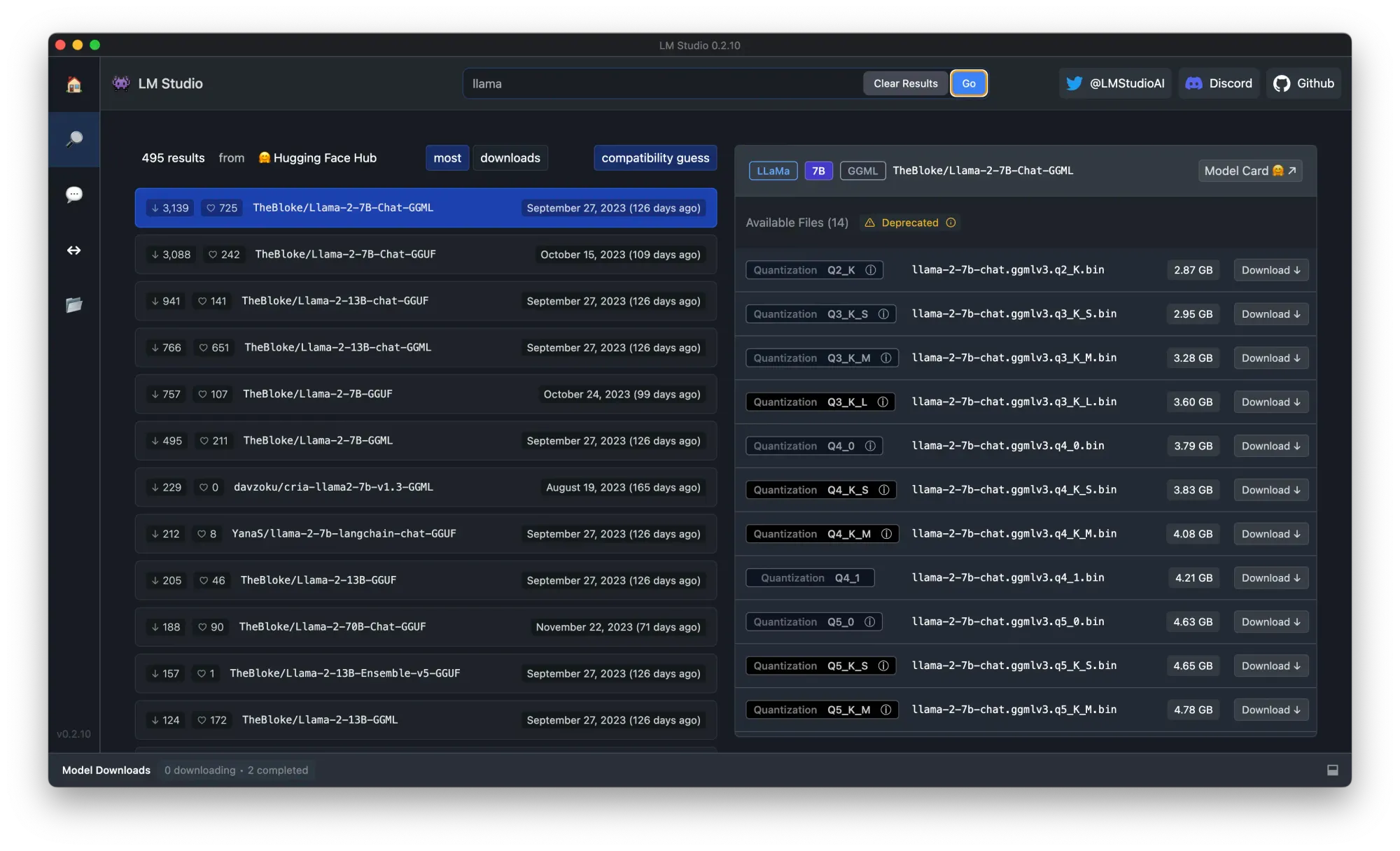
ステップ3. ダウンロードが完了したら、左側のパネルで「Chat」ボタンをクリックし、ダウンロードしたモデルをロードします
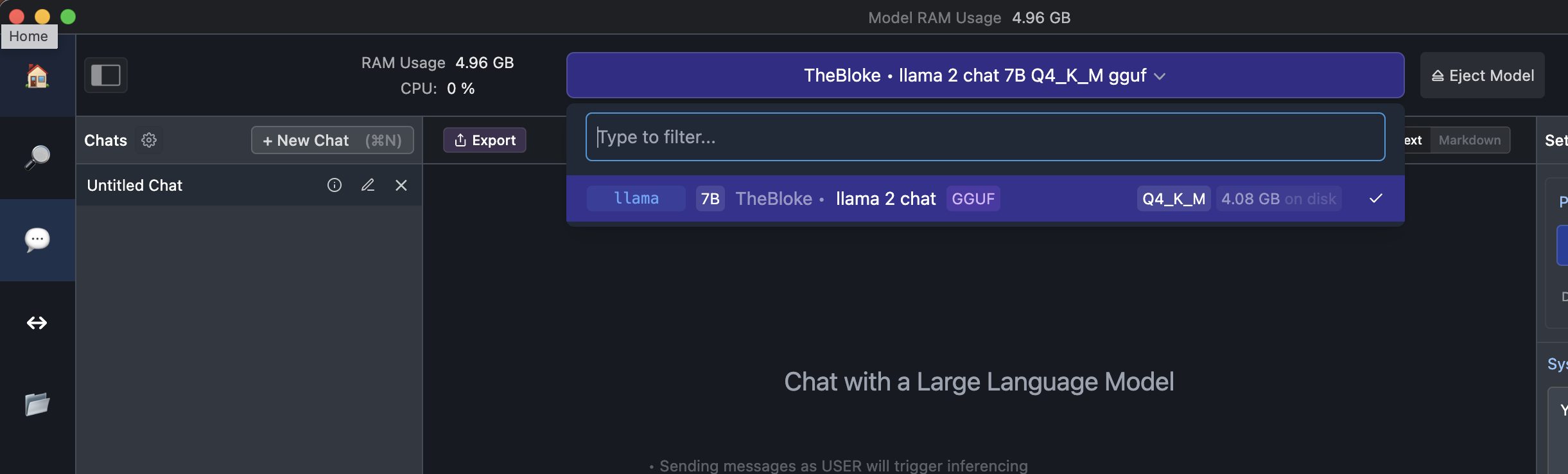
ステップ4. これでLlama 2とチャットすることができます!より高速な体験のために、右側のパネルで「Apple Metal(GPU)オプションを使用」をオンにするのを忘れないでください。
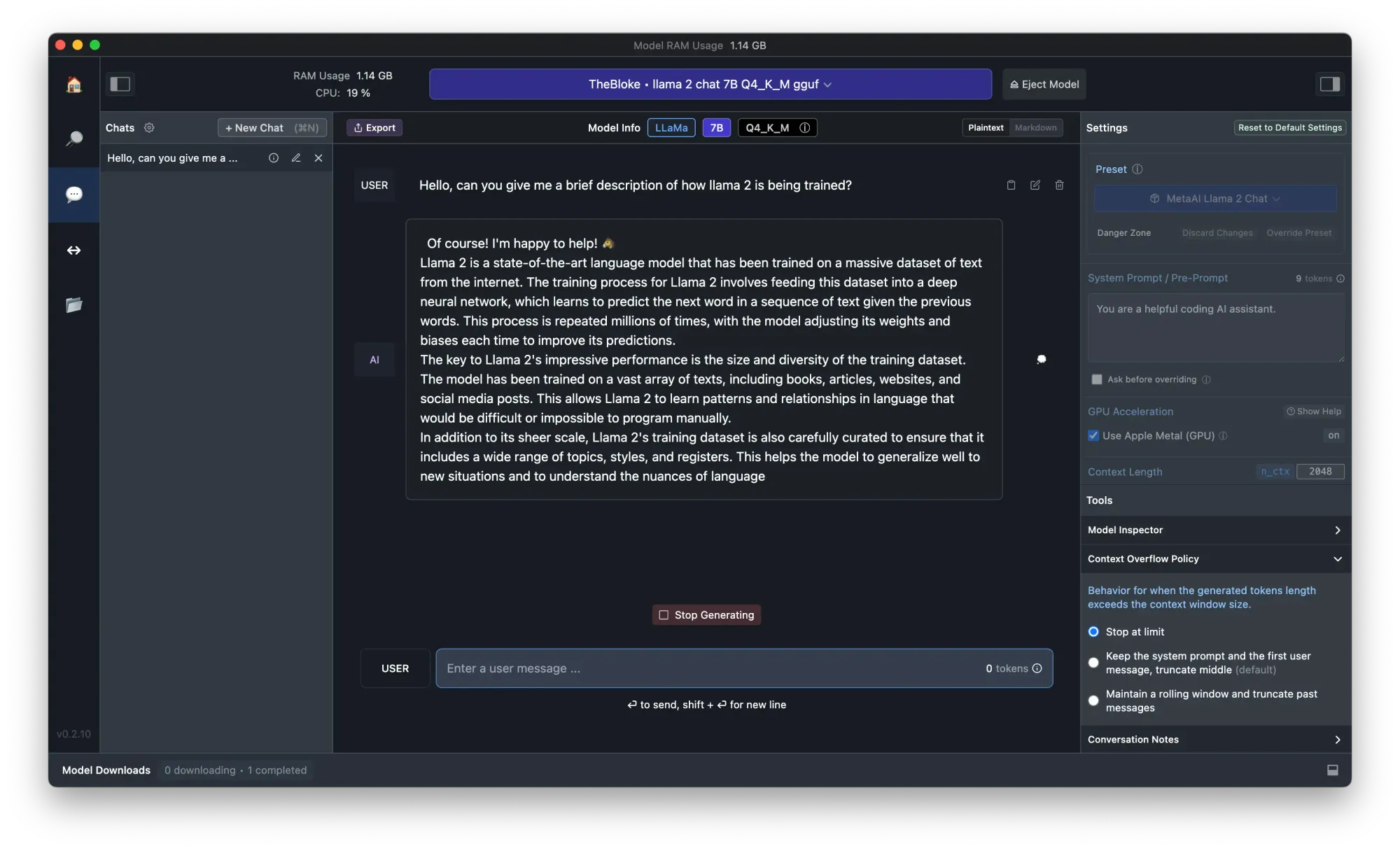
結論
Llama 2モデルは、高度な言語処理能力を提供するAIの重要な進歩を表しています。Llama.cpp、OLLAMA、MLC LLM、およびLM Studioなどのツールを使用してこれらのモデルをローカルで実行することは、柔軟性が向上し、プライバシーが強化され、クラウドベースのソリューションよりも費用効果が高い場合があります。各メソッドは技術的な複雑さとシステム要件が異なり、さまざまなユーザーのニーズに対応しています。読者には、Llama 2や他のLLMとの関与において、ローカルとオンラインのオプションの両方を探索することをお勧めします。選択肢は、技術的な専門知識、リソースの可用性、および特定の要件に合うものにすることが重要です。 このLLMのローカルデプロイメントへの探求は、革新的なアプリケーションとAIの潜在的な理解を深める扉を開きます。
今すぐこれらの事前に構築されたLlamaチャットボットを試してみてください: