イントロダクション:オープンソースで無料のAI音声クローンツールへの飛躍
機械から人間の声が unmistakably human(見間違えることのないほど)に聞こえた最初の瞬間を想像してください。驚きと不信の入り混じった感じ、この技術がどこまで進化できるのかについての好奇心。現在に移ると、GPT-SoVITSは私たちが新たな時代の瀬戸際に立っているのです。このツールは単に限界を押し広げているだけでなく、それらを再定義しているのです。これは機械が話すことについての話だけではありません;これは、機械が人間の音声のニュアンス、感情、独自性を持って話すことなのです。音声技術の未来へようこそ。
記事の概要
- GPT-SoVITSはゼロショットおよびフューショット学習によるテキスト読み上げ(TTS)を革新し、わずかなデータで非常にリアルな音声クローニングが可能です。
- このプラットフォームはクロス言語サポートとWebUIツールスイートを提供し、ユーザーがカスタムのTTSモデルを作成できるようにしています。
- GPT-SoVITSのインストールおよび実行方法はプラットフォームによって異なりますが、Windows、Mac、Kaggle、Google Colabのユーザー向けにガイダンスが用意されています。
もっと多くのAI音声生成ツールをお探しですか?
Elevenlabsの代替としてもっと安価なものをお探しですか?
Anakin AIのAI音声クローニングツールを試してみてください!あなた自身のデータセットで簡単にAI音声をクローンできます!
GPT-SoVITSの主な特徴
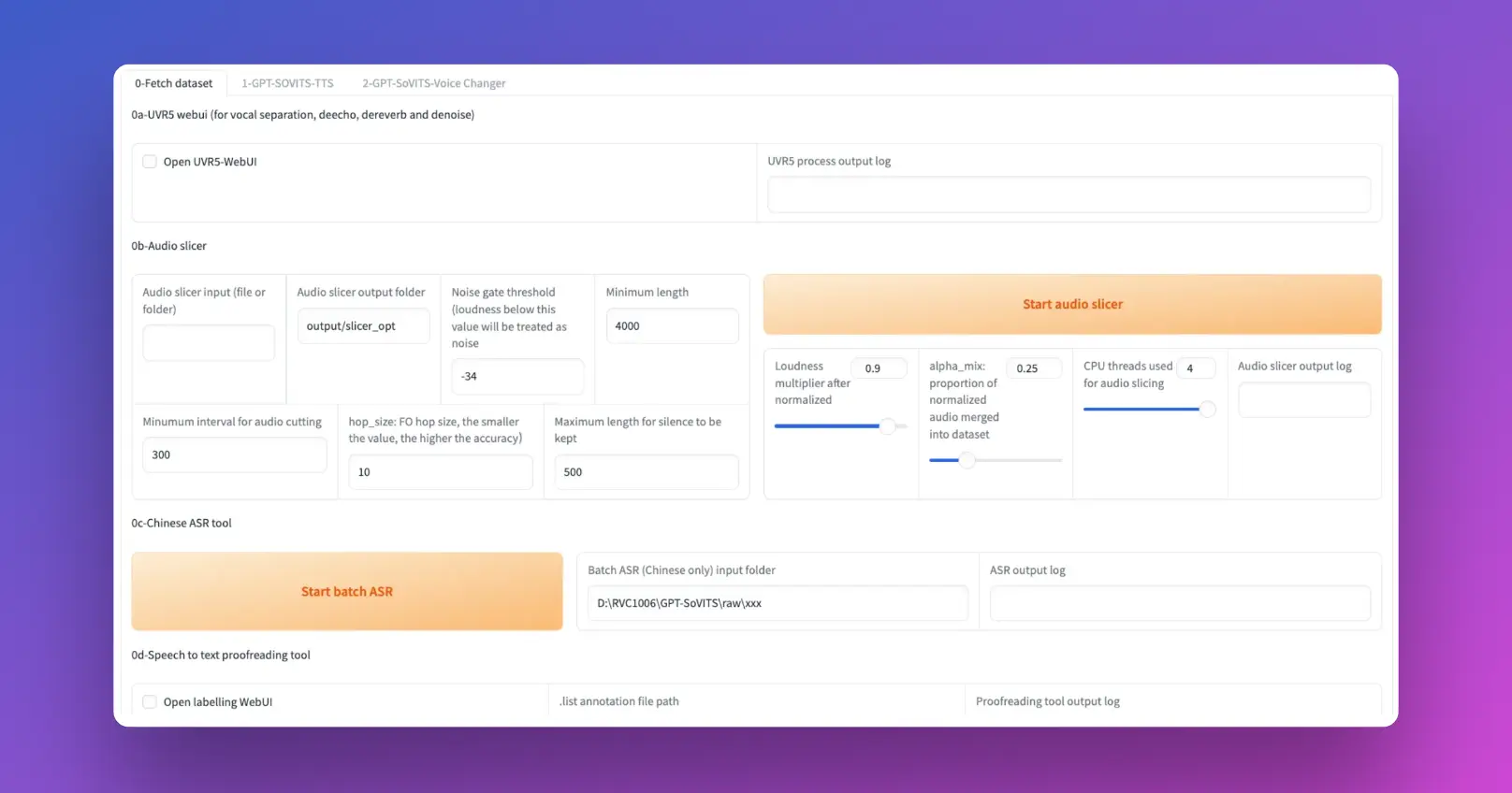
GPT-SoVITSは単なるツールではありません。音声技術の飛躍的な進化をもたらす革新的な特徴をいくつか備えています。これらの特徴を詳しく見ていきましょう。
ゼロショットTTS:未来の一端
- インスタント音声クローニング:ゼロショットTTSにより、GPT-SoVITSはわずかな5秒の音声サンプルだけでテキストから音声へ変換することができます。この機能は、声の本質をスナップショットとして捉え、訓練データの必要なしに書かれた言葉をその声で生命を吹き込むものです。
フューショットTTS:最小限のデータでリアリズムを創出
- 強化された声の類似性:GPT-SoVITSのフューショットTTS機能は、魔法のようです。たった1分の音声データでモデルを訓練することで、驚くほどの声の類似性とリアリズムを実現することができます。これは個別の音声アシスタント、オーディオブック、または音声の個性が重要なアプリケーションを作成する際に特に有益です。
クロス言語サポート:言語の壁を破る
- 多言語推論:GPT-SoVITSの最も印象的な特徴の一つは、トレーニングデータセットとは異なる言語での推論が可能であることです。現在、英語、日本語、中国語などの主要な言語をサポートしています。このクロス言語サポートにより、世界中のユーザーにとってグローバルなコミュニケーションとコンテンツ作成の可能性が広がり、非常に使いやすいツールとなります。
統合されたWebUIツール:クリエイターを支援する
- 総合ツールキット:GPT-SoVITSには、音声クローニングとTTSモデルの作成プロセスを簡素化するために設計された統合WebUIツールスイートが付属しています。
- 声の伴奏分離:バックグラウンドミュージックからボーカルを分離し、クリーンなトレーニングデータセットの作成を容易にします。
- 自動トレーニングセットセグメンテーション:音声データの自動セグメンテーションにより、トレーニングセットの作成を効率化します。
- 中国語の音声認識(ASR)およびテキストラベリング:これらの機能により、中国語の音声データを書き起こし、ラベリングする際のユーザーサポートが行われ、中国語の言語サポートを備えたTTSモデルの訓練を容易にすることができます。
これらの特長があることで、GPT-SoVITSは、趣味家やコンテンツクリエーターから研究者や専門家まで、音声技術の最先端を探求するための包括的な解決策となっています。

GPT-SoVITSのインストール方法:無料のAI音声クローンツールの環境準備
GPT-SoVITSのセットアップには、オペレーティングシステムに応じた特定の準備が必要です。GPT-SoVITSの高度な音声合成の世界に飛び込む準備が整っていることを確認するためのステップバイステップガイドを用意しました。
Windowsユーザー向け:
- 必要なダウンロード:Windowsユーザーは、
ffmpeg.exeとffprobe.exeをダウンロードする必要があります。これらはマルチメディアファイルの処理に必要な重要なファイルであり、GPT-SoVITSのルートディレクトリ直下に配置する必要があります。これにより、GPT-SoVITSが音声ファイルを円滑に処理できるようになります。 - 環境設定:適切なPython環境を設定することから始めます。依存関係を効果的に管理するためには、Condaを使用することをお勧めします。
Macユーザー向け:
- システム要件:Macユーザーは、特にGPUサポートについて自分のシステムの互換性を確認する必要があります。GPT-SoVITSは、Apple siliconまたはAMD GPUが搭載されたMacに最適化されています。また、macOSのバージョンは12.3以上であることを確認し、完全なGPUの機能を活用できるようにしてください。
- Conda環境:Windowsと同様に、Conda環境の作成から始めます。これにより、GPT-SoVITSのセットアップが他のPythonプロジェクトと分離され、依存関係管理が簡単になります。
インストール手順:
Conda環境の作成:
conda create -n GPTSoVits python=3.9を実行して、Python 3.9 の新しい 'GPTSoVits' 環境を作成します。このバージョンはGPT-SoVITSの要件との互換性のために選ばれています。conda activate GPTSoVitsで新しい環境をアクティブにします。
依存関係のインストール:
pip install -r requirements.txtを使用して、必要なPythonパッケージをインストールします。 このコマンドは、
requirements.txtファイルにリストされているすべての依存関係を読み取り、それらをConda環境にインストールします。FFmpegのインストール:
- Windows:
ffmpeg.exeとffprobe.exeをダウンロードした後、それらがGPT-SoVITSのルートディレクトリに存在することを確認してください。 - Mac: Homebrewを使用して、
brew install ffmpegコマンドを実行してFFmpegをインストールします。これにより、インストールプロセスが簡素化され、FFmpegがシステムとの統合がスムーズに行われます。
最終チェック:
- すべてのインストールが成功し、環境が正しく設定されていることを確認してください。GPT-SoVITSの機能を使用するPythonスクリプトやコマンドなど、簡単なテストを実行することで、すべてが正常に動作していることを確認できます。
これらの手順に従うことで、WindowsやMac上でGPT-SoVITSの機能を探索する準備が整い、技術的な問題を心配することなく音声合成の作成や実験に集中できるようになります。
WindowsでのGPT-SoVITSのインストール方法
ステップバイステップガイド:
Prezipファイルのダウンロード:
- GPT-SoVITSリポジトリにアクセスし、Windowsユーザー向けのPrezipファイルをダウンロードします。
ファイルの展開:
- ダウンロードしたファイルをコンピュータ上の適当な場所に保存し、使用しているアーカイブマネージャーを使ってファイルを展開します。
GPT-SoVITSの起動:
- 展開したフォルダ内で、
go-webui.batを見つけ、ダブルクリックします。これにより、GPT-SoVITS WebUIが起動し、アプリケーションが使用可能になります。
FFmpegのインストール(必要な場合):
- 信頼できるソースから
ffmpeg.exeとffprobe.exeをダウンロードしてください。これらのファイルをGPT-SoVITSのルートディレクトリに配置することで、オーディオ処理機能が有効になります。
事前学習済みモデル:
- 音声分離や残響除去などの拡張機能を使用する場合は、追加の事前学習済みモデルをダウンロードし、GPT-SoVITSフォルダ内の指定されたディレクトリに配置してください。
これらの手順に従うことで、Windowsユーザーは簡単にGPT-SoVITSをセットアップし、音声クローニングの機能を利用することができます。
MacでのGPT-SoVITSのDockerを使用したインストール方法
Macの準備:
- MacにApple SiliconまたはAMD GPUが搭載されており、macOS 12.3以降が実行されていることを確認してください。
- ターミナルで
xcode-select --installを実行して、Xcodeコマンドラインツールをインストールしてください。
Dockerのインストール:
Dockerのセットアップ:
- まだインストールされていない場合は、公式のDockerウェブサイトからDocker for Macをダウンロードしてインストールしてください。
GPT-SoVITSリポジトリのクローン:
- Gitを使用してGPT-SoVITSリポジトリをローカルマシンにクローンするか、GitHubから直接ダウンロードします。
GPT-SoVITSディレクトリへの移動:
- ターミナルウィンドウを開き、クローンまたはダウンロードしたGPT-SoVITSディレクトリに移動します。
Docker Compose:
- GPT-SoVITSディレクトリ内の
docker-compose.yamlファイルを探し、環境変数やボリュームの構成が適切に設定されていることを確認してください。
Docker Composeで起動:
- ターミナルで
docker compose -f "docker-compose.yaml" up -dを実行します。これにより、Dockerコンテナ内でGPT-SoVITSアプリケーションが起動します。
GPT-SoVITSへのアクセス:
- コンテナが起動して実行されている状態で、ローカルアドレスにアクセスすることで、ウェブブラウザからGPT-SoVITS WebUIにアクセスできます。アクセスするためには、ターミナルの出力に表示されたローカルアドレスに移動します。
Dockerを利用することで、Macユーザーは互換性の問題を克服し、macOSに直接インストールせずにGPT-SoVITSの高度な音声合成機能を活用することができます。
Google Colab/Kaggle NotebookでGPT-Sovits AI Voice Cloningを実行する
GPT-SoVITSをGoogle Colabで使用するための詳細なステップバイステップガイドです:
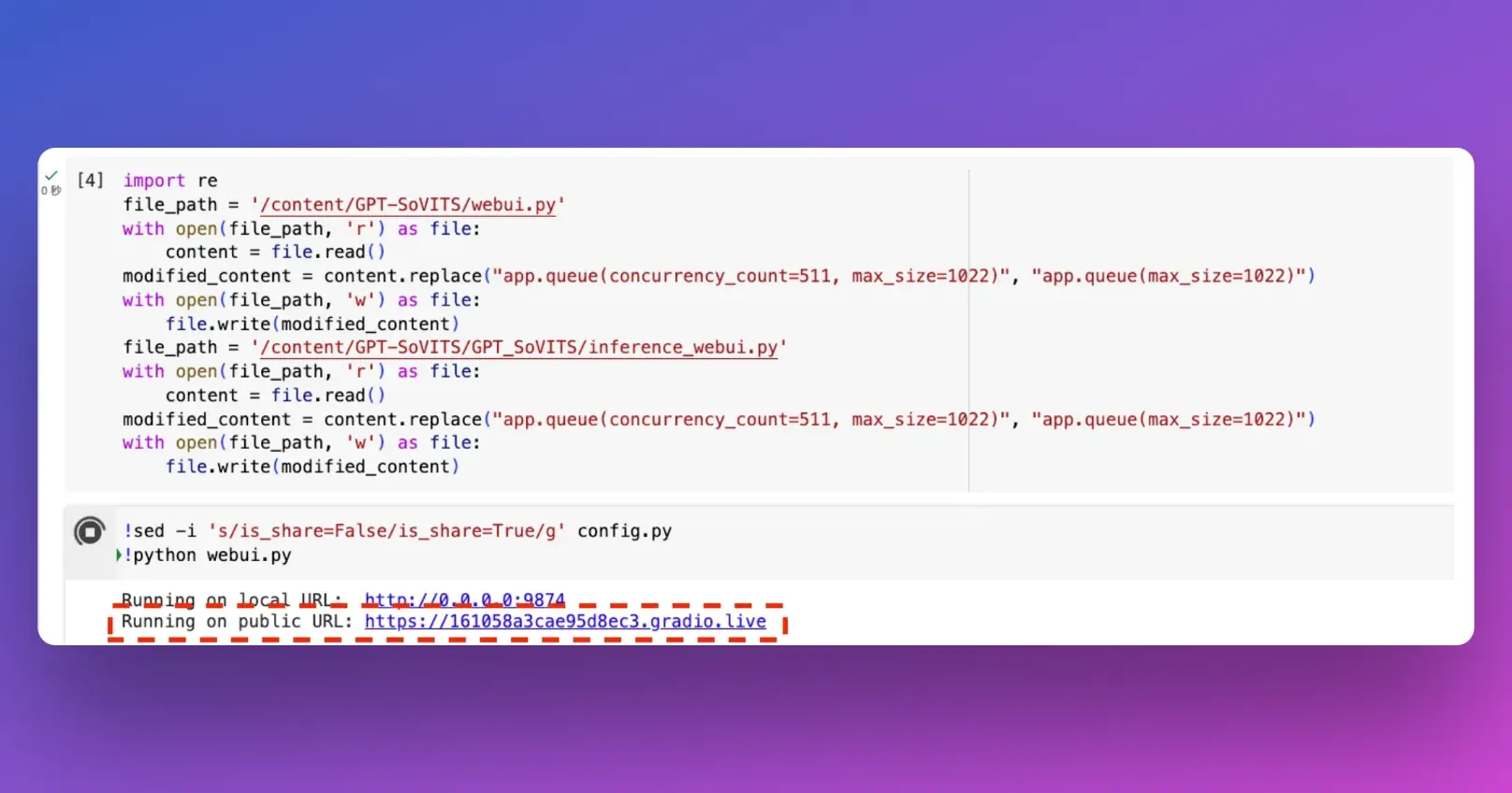
ステップ1:Google ColabにGPT-SoVITSをインストールする
Colabノートブックにアクセス: 提供されたColabノートブックのリンクにアクセスします。Colabを使用するためにはGoogleアカウントにログインしている必要があります。また、Kaggleノートブックのリンクも使用できます。
ノートブックの実行: ノートブックが開いたら、ランタイム > すべて実行をクリックして、GPT-SoVITSのインストールプロセスを開始します。これにより、必要なソフトウェアコンポーネントが自動的にダウンロードおよびインストールされます。
権限の付与: セットアップ中に、Google Driveへのアクセスなどの許可を求めるポップアップが表示される場合があります。これらの許可を許可する必要があります。これにより、ノートブックがDriveとやり取りしてファイルの保存やアクセスができるようになります。
ステップ2:トレーニング音声データの提供
音声データの準備: 1〜2分の長さの、可能な限り背景ノイズのない.wav形式の音声録音ファイルが必要です。現在、中国語のトレーニングのみがサポートされています。
Google Driveへのアップロード: Google Driveで、voice_filesという名前の新しいフォルダを作成します。このフォルダ内に、オリジナルの音声ファイル用のrawサブフォルダと処理済みファイル用のslicerサブフォルダを作成します。.wavファイルをrawフォルダにアップロードします。
ステップ3:音声認識の精度の確認
オーディオスライサーの実行: Colabノートブックでオーディオスライサーを実行するセクションを見つけ、rawフォルダのパス(/content/drive/MyDrive/voice_files/raw)を入力し、スライサーを実行します。これにより、音声ファイルがトレーニングに適したサイズに分割されます。
自動音声認識(ASR): スライスが完了したら、ノートブックのASRセクションでslicerフォルダのパス(/content/drive/MyDrive/voice_files/slicer)を指定し、ASRプロセスを実行します。これにより、音声セグメントが転写されます。
転写の確認: ASRが完了したら、転写の正確性を確認することが重要です。生成された.listファイルにアクセスし、転写内容を手動で確認することができます。
ステップ4:トレーニングデータのフォーマット
データの整理: 転写された音声ファイルとそれに対応する転写内容が正しくフォーマットされ、整理されていることを確認してください。 通常の形式は、エントリが.listファイルにあり、形式は次のようになります:audio_file_path|speaker_name|language|transcription。
フォーマットされたデータのアップロード: この.listファイルとセグメント化されたオーディオファイルを、Colabノートブックの指示に従って、Google Driveの適切なディレクトリにアップロードします。
ステップ5:ファインチューニングのトレーニング
トレーニングの開始: Colabノートブックで、モデルのファインチューニングセクションを見つけます。フォーマットされたデータへの必要なパスを入力し、トレーニングプロセスを開始します。
進行状況の監視: トレーニングには時間がかかる場合があるため、Colabノートブックで提供されるログを使用して進行状況を監視します。エラーがなく、プロセスが正常に完了することを確認します。
ステップ6:推論-テキストから声を生成する
推論のセットアップ: トレーニング後、Colabノートブックで推論環境を設定します。訓練済みモデルの重みへのパスを提供します。
声の生成: 声モデルで合成したいテキストを入力し、推論を実行します。モデルは提供されたテキストに基づいて音声を生成します。
ダウンロードと比較: 生成されたオーディオファイルをダウンロードし、元の音声素材と比較して品質と類似性を評価します。
これらのステップに従うことで、GPT-SoVITSをGoogle Colabで音声クローンやテキスト音声合成に使用することができます。技術を倫理的に使用し、著作権とプライバシー法を尊重することを忘れないでください。このガイドが役立つ場合は、GPT-SoVITSと音声合成技術についてさらに探索してみてください。
GPT-SoVITS(無料のAI音声クローンツール)の事前トレーニング済みモデルとデータセット形式
事前トレーニング済みモデル:
GPT-SoVITSを使用するには、まず事前トレーニング済みモデルをダウンロードして使用する必要があります。これらのモデルは広範なデータセットでトレーニングされており、時間とリソースを節約できます。
メインモデル: 公式のGPT-SoVITSリポジトリまたはモデル配布ページから主要な事前トレーニング済みモデルをダウンロードします。これらのモデルをGPT-SoVITSのインストールフォルダ内のpretrained_modelsディレクトリに配置します。
特殊タスク: ボーカル/伴奏の分離や残響除去などのタスクには、追加のモデルが用意されています。これらの専用モデルをダウンロードし、通常はGPT-SoVITSのインストールのtoolsまたはextensionsフォルダ内の指定されたディレクトリに配置します。
データセットの形式:
テキスト音声合成(TTS)の注釈には、特定の形式でデータセットを編成する必要があります。各エントリには次の項目が含まれる必要があります:
- パス: オーディオファイルへの相対パスまたは絶対パス。
- スピーカー名: 異なる声を区別するために便利なスピーカーの識別子。
- 言語: 言語コード(例:英語の場合は 'en'、日本語の場合は 'ja'、中国語の場合は 'zh')。
- テキスト: 対応するファイルの音声の転写。
例えば、エントリは次のようになります:/path/to/audio.wav|John Doe|en|こんにちは、世界!
さらにAI音声生成ツールを探索したいですか?
より安価なElevenlabsの代替をお探しですか?
Anakin AIのAI音声クローンツールを試してみてください!独自のデータセットでAI音声を容易にクローンできます!
GPT-SoVITSの高度な機能、この無料のAI音声クローンツールの品質はどのようですか?
GPT-SoVITSは、単なる声のクローン化にとどまらず、TTSと音声合成の領域で使い勝手の良い高度な機能を備えた多目的なツールです:
クロスリンガルサポート: GPT-SoVITSは、トレーニングデータと異なる言語の音声を生成することができます。これにより、さまざまな言語のコンテキストにおいて適用範囲が広がります。
統合WebUIツール: このプラットフォームには、ボイス分離、トレーニングセットのセグメンテーションなどのタスクに対応するさまざまなツールが組み込まれており、初心者でも利用できます。
GPT-SoVITSの将来の計画とロードマップ、より良い無料のAI音声クローニングのために
GPT-SoVITSのロードマップには、興奮するような開発が含まれています:
ローカライゼーション: 日本語と英語でのローカライゼーションの計画が進行中であり、異なる地域でのユーザーフレンドリーなツールになることを目指しています。
ユーザーガイド: 新しいユーザーがプラットフォームを簡単にナビゲートできるように、包括的なユーザードキュメントが準備中です。
データセットのファインチューニング: 日本語と英語のデータセットのファインチューニングの向上が予想されており、合成音声の品質と自然さが向上します。
GPT-SoVITSに関する質問は、GitHubリポジトリで質問してください。
結論:無料のオープンソースAI音声クローン技術の未来は?
GPT-SoVITSは、声のクローン化とTTS技術の領域を再構築しています。使いやすさ、個人化のための最小限のデータ要件、さまざまな言語のサポートなど、多様なアプリケーションにおける強力なツールとなっています。コンテンツ作成からパーソナライズされた音声アシスタントまで、GPT-SoVITSは革新的な音声合成機能へのゲートウェイを提供します。プラットフォームが進化し続けるにつれて、その影響力は成長し、音声技術をこれまで以上にアクセス可能かつ多目的にしていきます。
さらにAI音声生成ツールを探索したいですか?
より安価なElevenlabsの代替をお探しですか?
Anakin AIのAI音声クローンツールを試してみてください!独自のデータセットでAI音声を簡単にクローンできます!