💡
AIの最新トレンドに興味がありますか?
それなら、
Anakin AIを見逃してはいけません!
Anakin AIは、ワークフロー自動化のためのオールインワンプラットフォームで、使いやすいノーコードアプリビルダーを使用して強力なAIアプリを作成できます。Deepseek、OpenAIのo3-mini-high、Claude 3.7 Sonnet、FLUX、Minimax Video、Hunyuanなどを使用します。
Anakin AIを使用することで、わずか数分で夢のAIアプリを構築できます。
 Anakin AIで簡単にAIエージェントワークフローを構築
Anakin AIで簡単にAIエージェントワークフローを構築人工知能は人間のコミュニケーションを理解する上で著しい進歩を遂げていますが、異なるモダリティ間で感情を正確に認識することは依然として課題です。Alibabaの最近発表されたR1-Omniモデルは、この領域において重要なブレークスルーを示しており、確証可能な報酬を伴う強化学習(RLVR)をオムニマルチモーダル大規模言語モデルに初めて適用したものです。
感情認識への新しいアプローチ
人間の感情は複雑であり、同時に複数のチャネルを通じて表現されます - 顔の表情、声のトーン、ボディランゲージ、そして言葉の内容。従来の感情認識システムは、これらの多様な信号を効果的に統合することに苦労しており、視覚的および聴覚的手がかりの間の微妙な相互作用を捉えることに失敗することがよくあります。
R1-Omniは、異なるモダリティが感情状態にどのように寄与するかをより洗練された理解を発展させることを可能にする高度な強化学習アプローチを活用することで、この課題に対処します。オープンソースのHumanOmni-0.5B基盤の上に構築されたこの革新的なモデルは、従来のトレーニングシステムに比べて推論、理解、一般化において優れた能力を示します。
「私たちは感情認識に焦点を当てており、視覚と音声のモダリティが重要な役割を果たすタスクです。」と、R1-Omniの背後にいる研究者たちは彼らの技術文書に記しています。
技術アーキテクチャと革新
R1-Omniの核心は、先進的なマルチモーダル処理を強化学習技術と組み合わせて、より説明可能で正確な感情認識システムを作成することです。このモデルは、SigLIP-base-patch16-224ビジョンタワーを使用して視覚入力を処理し、音声はWhisper-large-v3を介して処理します。この強力な音声処理モデルは、感情情報を伝える微妙な声の手がかりを捉えることができます。
R1-Omniを従来のアプローチと区別するのは、そのトレーニング方法です。従来の監視型微調整(SFT)が、アノテーションされた例に基づいて感情ラベルを予測するようにモデルを訓練するのに対し、R1-Omniは強化学習の枠組みを採用し、モデルは正しい予測だけでなく、それらの予測につながる確証可能な推論経路を示すことで報酬を受け取ります。
この新しいアプローチは、マルチモーダルの入力と感情の出力の間の説明可能な関連を促進します。感情を単に「怒っている」とラベル付けするのではなく、R1-Omniは、その評価に寄与する特定の視覚的手がかり(しかめっ面、緊張した顔の筋肉)や音声特徴(声の大きさ、早口)を明示することができます - これは、敏感な文脈で展開されるAIシステムにおいて信頼を構築するための重要な能力です。
主な機能と性能
R1-Omniは、従来の感情認識システムに対して次の三つの重要な進歩を示しています:
- 強化された推論能力:モデルはその分類に対して詳細な説明を提供し、特定のマルチモーダル観察を感情的な結論に結びつけます。この透明性は、説明なしに分類を提供する「ブラックボックス」アプローチに対して重要な改善を表しています。
- 改善された理解能力:監視型微調整によって訓練されたモデルと比べて、R1-Omniは感情認識タスクで大幅に良好な精度を示します。これは強化学習アプローチが人間の判断とより整合性のある感情状態のより微妙な表現を発展させるのに役立つことを示唆しています。
- 強化された一般化能力:最も印象的なことに、R1-Omniはトレーニング例と異なるシナリオ、すなわち分布外データで顕著な性能を示します。この特定のトレーニングコンテクストを超えて一般化する能力は、実世界のアプリケーションにおいて重要です。
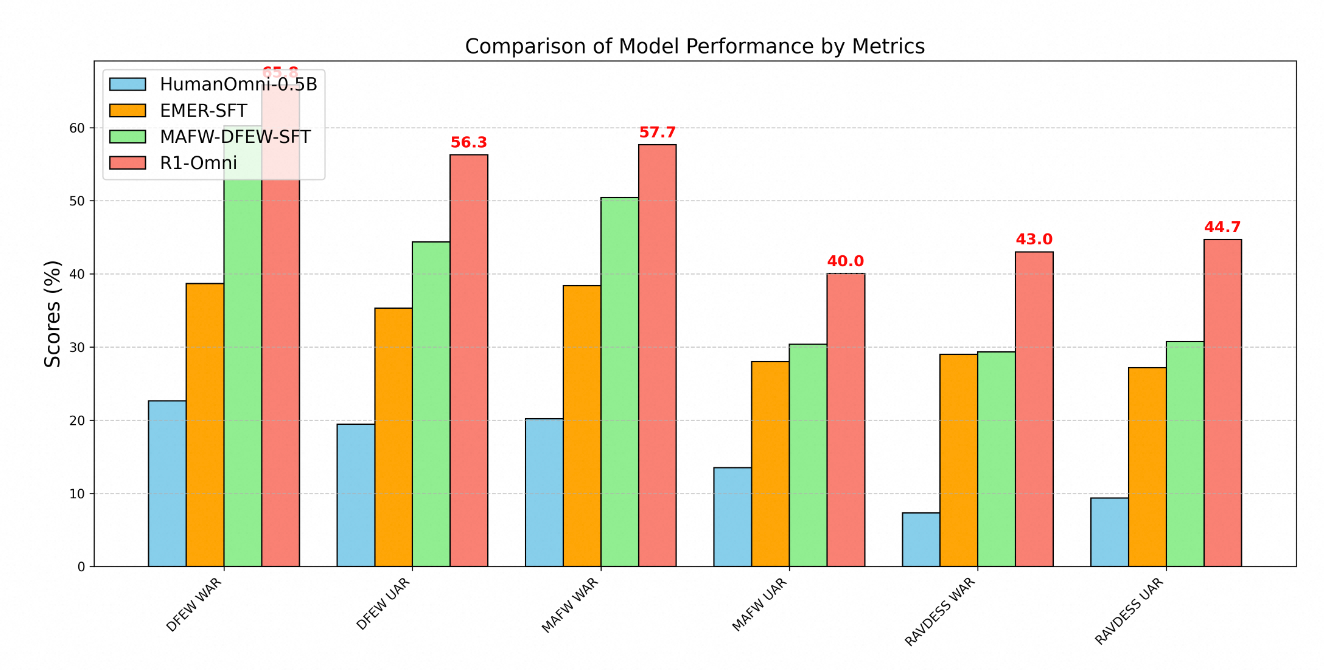
R1-Omniの技術的な優位性は、複数の感情認識ベンチマークにわたる性能指標を通じて明らかに示されています。DFEW、MAFW、RAVDESSの3つの主要データセットでテストすることで、モデルの能力の包括的な評価が行われました。
DFEWデータセットでは、R1-Omniは65.83%の加重平均再現率(WAR)と56.27%の非重み付け平均再現率(UAR)を達成し、ベースラインのHumanOmni-0.5Bモデル(22.64% WAR)とMAFW-DFEW-SFTモデル(60.23% WAR)を大幅に上回りました。
さらに重要なのは、分布外データに対するモデルの性能です。トレーニング中に使用されなかったRAVDESSデータセットでテストしたところ、R1-Omniは43%のWARと44.69%のUARを達成しました - 基本モデル(7.33% WAR)と監視型微調整された代替手段(29.33% WAR)よりもはるかに良い結果を示しました。
トレーニング手法
R1-Omniの開発は、洗練された二段階のトレーニングプロセスに従いました:
最初に、「コールドスタート」フェーズでは、研究者たちはHumanOmni-0.5Bを使用してモデルを初期化し、説明可能なマルチモーダル感情推論データセットから232サンプル、HumanOmniデータセットから348サンプルを含む注意深くキュレーションされたデータセットで微調整しました。これにより、説明可能な推論プロセスを強調しつつ、基礎的な能力が提供されました。
第二段階では、MAFWおよびDFEWデータセットから15,306のビデオサンプルを含む大規模データセットを用いて、確証可能な報酬を伴う強化学習を適用しました。この強化学習フェーズは、モデルの高度な推論力と一般化能力を発展させる上で重要でした。
トレーニング中、プロセスは正確な分類だけでなく、確証可能な推論経路の発展にも重点を置きました。トレーニング例には、通常、感情ラベルと観察から結論への構造的思考プロセスが含まれていました。このアプローチは、モデルが単なる統計的相関を学ぶのではなく、説明可能な関連を発展させることを促しました。
実世界での応用
R1-Omniが示した能力は、さまざまな分野で多くの可能性を開きます:
- メンタルヘルスサポート:このモデルは、患者の感情状態の客観的な評価を提供することにより、セラピストを支援する可能性があります。微妙な感情の手がかりを識別することも可能です。
- 教育:同様のシステムは、教師が学生の関与や学習資料に対する感情反応を測定するのに役立ち、より反応的な教育アプローチを可能にします。
- カスタマーサービス:R1-Omniの技術は、顧客の感情を認識し、適切に応答することで、満足度を向上させる自動化されたカスタマーサービスシステムを強化することができます。
- コンテンツ分析:このモデルは、市場調査、メディア分析、コンテンツモデレーションのために、動画や音声記録の感情内容を分析することができます。
このモデルの説明可能性は特に重要であり、人間のオペレーターがAIが生成した感情評価の背後にある推論を理解し、検証できるようにします。この透明性は、信頼を構築し、敏感なドメインにおける広範な採用のために必要な人間とAIの効果的なコラボレーションを促進します。
今後の発展
プロジェクトのロードマップによれば、今後のR1-Omniの発展には、HumanOmniのソースコードの統合、より詳細な再現プロセスの公開、すべてのトレーニングデータのオープンソース化、単一ビデオおよび単一オーディオモダリティデータ向けの推論能力の開発、大規模な7Bバージョンのモデルの結果をリリースすることが含まれます。
これらの計画された改善により、モデルの研究者や開発者に対するアクセス性と有用性がさらに高まり、マルチモーダル感情認識の分野における進展が加速する可能性があります。
結論
AlibabaのR1-Omniは、マルチモーダル理解における強化学習技術の革新的な応用を通じて、AIベースの感情認識において重要な進歩を表しています。推論能力を高め、精度を向上させ、新しいシナリオに対する優れた一般化を示すことにより、R1-Omniは感情AIの限界を押し広げています。
より自然な人間とコンピュータの相互作用に向かう中で、異なるコミュニケーションチャネルを通じて人間の感情を正確に認識し、応答できるシステムはますます重要な役割を果たすでしょう。このモデルが説明可能性と一般化に重点を置いていることは、従来のアプローチの重要な限界に対処し、責任ある効果的な感情認識技術の新しい標準を設定しています。
強化学習の強みとマルチモーダル処理能力を組み合わせることで、Alibabaは単に改善された感情認識システムを作成するだけでなく、AIシステムが人間のコミュニケーションの微妙な複雑性を理解する方法の新たなパラダイムを生み出す可能性があります。



