一貫性のある高品質の動画を作成するのに苦労したことはありませんか?あなたは一人ではありません。コンテンツクリエイター、マーケター、またはAI愛好家として、私たちは皆、一貫性のない動画出力に対するフラストレーションを抱えています。しかし、もし私が、あなたの動画制作プロセスを変革できる強力なソリューションがあると言ったらどうでしょうか?
WAN 2.1とその微調整された対応モデル、WAN-LoRA-Trainerをご紹介します。この革新的なAIモデルは、Replicateプラットフォームと組み合わせることで、あなた自身の画像や動画を使ってカスタム動画スタイルを簡単にトレーニングできます。このガイドの終わりまでには、WAN 2.1を活用して、視覚的に驚くべき一貫した動画を毎回制作する方法を正確に理解できるでしょう。
では、始めましょう!
WAN-LoRA-Trainerとは何で、なぜ関心を持つべきなのでしょうか? WAN-LoRA-Trainerは、WAN 2.1に基づいた特化型の微調整手法で、LoRA(Low-Rank Adaptation)技術を利用しています。簡単に言えば、LoRAの微調整では、元のモデルのパラメータの大部分を固定し、ごく小さなサブセットのみをトレーニングします。このアプローチにより、計算コストが大幅に削減され、品質を犠牲にすることなくトレーニングが加速します。
あなたのビジョンに一貫して合った動画を制作することを想像してみてください—もう予測不可能な結果や無駄な時間の調整は必要ありません。WAN-LoRA-Trainerは、あなたの創造的ニーズに正確に合ったパーソナライズされたAIモデルを作成する力を与えてくれます。
ステップ1: データセットの準備 — 品質が重要です! あなたのトレーニングデータセットはモデルの基盤です。効果的に準備する方法は次のとおりです:
画像: 顔や物体のような焦点を絞ったコンセプトには、高品質の画像を5~30枚使用します。より広範なスタイルや複雑なテーマの場合は、20~100枚を目指してください。 解像度: 各画像が少なくとも512×512ピクセルであることを確認してください。大きな画像はトレーニング中に自動的にリサイズされます。 キャプション: 各画像に対して、.txtファイル内に説明的なキャプションをペアにします。キャプションは、モデルが文脈と詳細を把握するのに役立ちます。 例:image1.jpg → image1.txtには「スチームパンク風のオブジェクトの詳細な写真。」と記載。
プロのヒント: BLIPやHugging FaceモデルなどのAIツールを使ってキャプション作成を自動化し、貴重な時間を節約しましょう。
ステップ2: データセットを圧縮してアップロードする データセットの準備が整ったら:
すべての画像とキャプションを1つの.zipファイル(例:my_dataset.zip)に圧縮します。 Google Drive、Amazon S3、GitHub Pagesなどのサービスを使用して、このファイルを公開アクセス可能なURLにアップロードします。 さあ、トレーニングする準備ができました!
ステップ3: ReplicateでWAN-LoRAモデルをトレーニングする Replicateは、使用した分だけ支払う直感的なプラットフォームを提供し、WAN-LoRAモデルのトレーニングをサポートします。手順は以下の通りです:
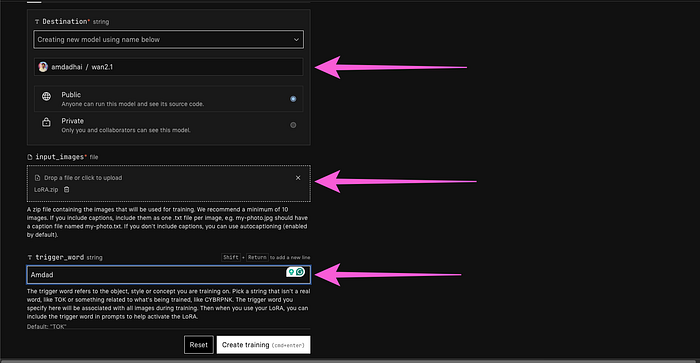
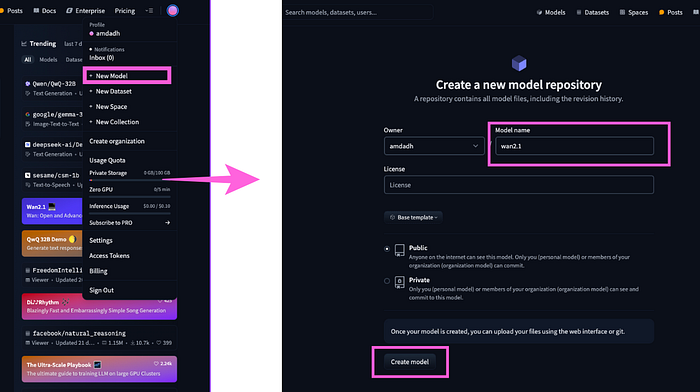
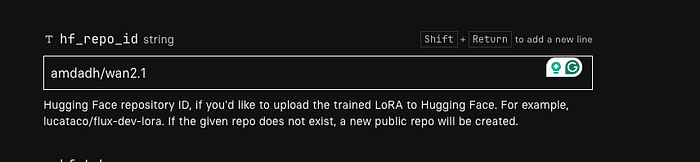
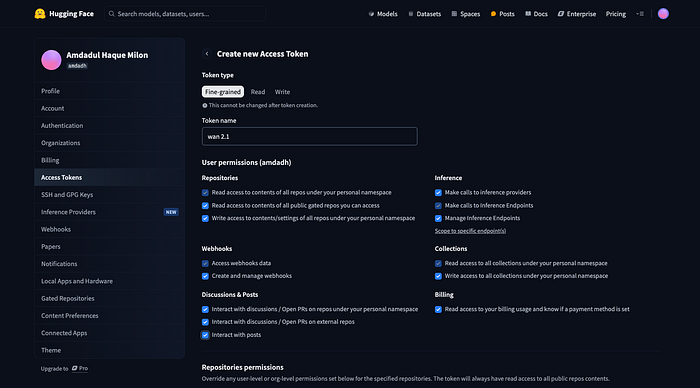
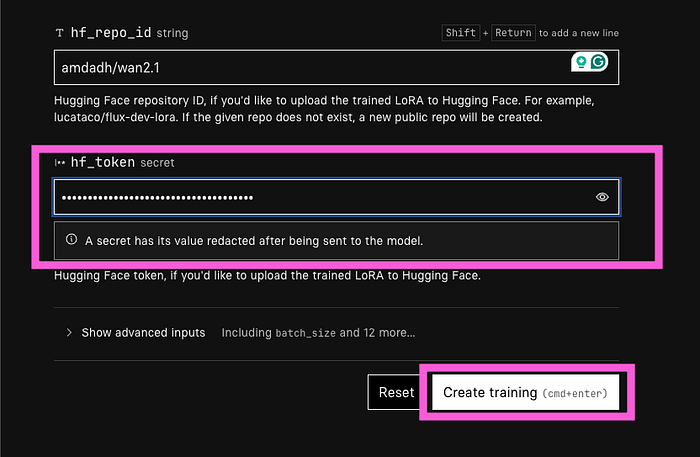
ReplicateのWAN-LoRA トレーナーページにアクセスします。まず、宛先をクリックし、新しいモデルを作成し、好きな名前を付けます。 次に、入力画像セクションにあなたのzipファイルを提供します。 トリガーワードを設定します。トリガーワードはあなたのトレーニングモデルを識別する特定の単語です。 宛先、入力画像、トリガーワードを設定すると、2000ステップのデフォルト設定を見つけるために2ステップスクロールダウンします。それはかなり良いですが、推奨範囲である3000から4000 次にHF repo_idに行きます。それはHugging FaceのリポジトリIDです。このIDを取得するには、Hugging Faceにアクセスし、アカウントを作成し、プロフィールをクリックして新しいモデルを作成し、モデルに名前を付けて、モデルを作成をクリックします。 モデルを作成すると、モデル説明からIDをコピーできます。 次にHFトークンを提供する必要があります。それはHugging Faceのトークンでもあります。このトークンを取得するには、再度Hugging Faceにアクセスして設定をクリックし、アクセス・トークンをクリックし、新しいトークンを作成し、名前を付け、ユーザー権限を提供し、トークンを作成をクリックします。トークンを作成すると、トークンをコピーできるようになります。そのままコピーをクリックしてください。 このトークンをhf_tokenにペーストし、トレーニング作成をクリックします。 今は待つだけで、その魔法を見てください!
トレーニングされたWAN-LoRAモデルを使用して素晴らしい動画を簡単に作成する方法 おめでとうございます!ReplicateでのWAN-LoRAモデルのトレーニングが成功しました。次に興奮する部分がやってきます — あなたのパーソナライズされたモデルを使用して、一貫した高品質の動画を簡単に作成します。
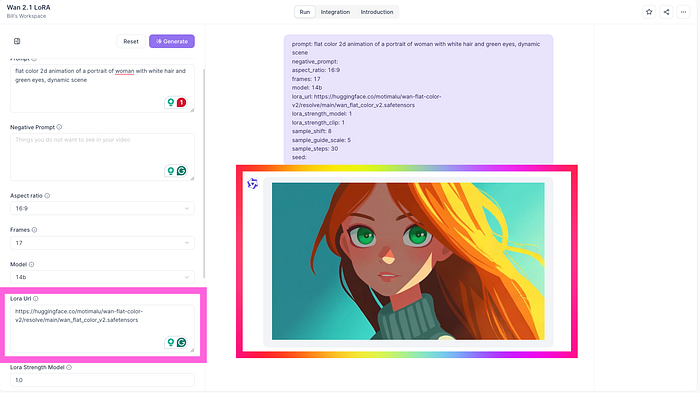
ステップ1: トレーニングされたLoRA URLにアクセスする トレーニングが完了すると、ReplicateはトレーニングされたLoRAモデルに直接リンクするユニークなURLを提供します。通常、このような形式です: https://huggingface.co/motimalu/wan-flat-color-v2/resolve/main/wan_flat_color_v2.safetensors
このURLはあなたの金の切符です — それにより、あなたはトレーニングされたモデルをほぼどこでも使用でき、ローカルのコンピュータでも使用できます。
しかし、カスタムモデルを使用して動画を作成するさらにシンプルで効率的な方法があります。
ステップ2: Anakin AIで動画を簡単に生成する 複雑なセットアップやローカルインストールを扱う代わりに、直感的なAnakin AIプラットフォームを利用することができます。手順はとても簡単です:
WAN 2.1 LoRA | Anakin.ai 自分のトレーニングされたWAN 2.1 LoRAモデルを使用して、瞬時に美しいパーソナライズされた動画を作成します。 anakin.ai
LoRA URL入力フィールドが見えるまでスクロールします。 トレーニングされたLoRA URLをそのままこのフィールドにペーストします。 プロンプト&ネガティブプロンプト: モデルサイズの選択: 140億パラメータ: 10億パラメータ: 予算と品質要件に最も適したモデルサイズを選択すれば大丈夫です。
なぜAnakin AIを選ぶのか? 使いやすさ: テクニカルな問題を心配する必要はありません — URLをペーストして生成するだけです。 コストの柔軟性: 予算に合ったモデルサイズを選択します。 品質の結果: 一貫してプロフェッショナル品質の動画を簡単に得ることができます。 あなたの創造性を実現する準備はできていますか?
✨ Anakin AIでWAN-LoRAモデルを使って動画を作成し始めましょう!
コスト見積もり: WAN-LoRAトレーニングの実際のコストは? ReplicateでWAN-LoRAモデルのトレーニングにかかるコストを理解することは、予算計画にとって重要です。Replicateは、GPU使用量に基づいて課金され、異なるGPUが異なるパフォーマンスと価格を提供します。以下に明確な内訳があります:
3000ステップトレーニングのコスト計算例 仮に、Nvidia L40S GPUで3000ステップのトレーニングに約7.5時間かかるとします(これは推定時間であり、データセットの複雑性や設定によって実際の実行時間はわずかに異なる可能性があります):
時間単価(L40S GPU): $3.51 推定トレーニング時間: 7.5時間 合計推定コスト: 7.5時間 × 3.51ドル/時間 = **26.33 USD** 効率的なGPU(例えば、Nvidia A100)を選択した場合、トレーニング時間が大幅に短縮される可能性があります(約5時間まで短縮されるなど):
時間単価(A100 GPU): $5.04 推定トレーニング時間: 5時間 合計推定コスト: 5時間 × 5.04ドル/時間 = **25.20 USD** Nvidia A100 GPUは高い時間単価を持っていますが、高速な処理速度により、L40S GPUと比較して同等またはそれ以下の総コストになることが多く、迅速なターンアラウンドタイムという利点も得られます。
トレーニングコストと結果を最適化するためのヒント WAN-LoRAトレーニングから最高の価値と品質を得るために、次の実用的なヒントを考慮してください:
データセットの品質: ノイズの多いまたは無関係な画像は避ける: 高品質で焦点を絞った画像がより良い結果をもたらします。 多様な視点を含める: 異なる角度、照明条件、背景がモデルの一般化を改善します。 ハイパーパラメータの調整: 学習率と勾配蓄積を調整する: 初期結果を監視し、それに応じてこれらのパラメータを調整します。 混合精度(fp16)を使用する: これによりメモリ使用量が大幅に削減され、品質を犠牲にすることなくトレーニングが加速します。 定期的なテスト: 出力サンプルを定期的に生成する: モデルが順調に進んでいるか確認するために、数エポックごとに出力を確認します。 キャプションを改善するか、データを追加する: 結果が期待に達していない場合は、キャプションを改善したりデータセットを拡張したりします。 これらの要因を慎重に管理することで、ReplicateでWAN-LoRAモデルを効率的にトレーニングし、コストを抑えながら優れた結果を一貫して達成することができます!
APIを介した動画生成の自動化 生産性に熱心な方にとって、ReplicateのAPIを使用することで、動画の作成を自動化できます。以下は迅速なPythonの例です:import replicatemodel = replicate.models.get("zsxkib/hunyuan-video-lora")
ワークフローを自動化し、動画制作をシームレスに拡張しましょう!
最終的な考え: 一貫性が鍵です 一貫性のある視覚的に魅力的な動画を作成することは、複雑やフラストレーションを伴う必要はありません。WAN-LoRA-TrainerとReplicateを使用すれば、あなたの創造的なビジョンを簡単に実現する強力なツールが手に入ります。
パーソナライズされたブランディング、魅力的なストーリーテリング、インパクトのあるマーケティングキャンペーン — すべてがあなたの独自のスタイルと一貫して調和しています。
動画制作プロセスを変革し、あなたの創造性を解き放つ準備はできましたか?
動画制作のレベルを高める準備はできましたか? WAN-LoRA-Trainer、HunyuanVideoなどの最先端AI動画制作ツールの力を活用し、すべてを直感的なプラットフォームでシームレスに統合しましょう。映画のような傑作を簡単かつ一貫して作成できます。
今すぐAnakin AIビデオジェネレーターを探索しましょう →