FLUX、最先端のAI画像生成器は、人工知能シーンの最前線に躍り出ました。テキストプロンプトから複雑な詳細と想像力豊かな画像を生成する能力で知られ、アーティスト、デザイナー、AI愛好者にとって人気のあるリソースです。ウェブアクセス可能なバージョンも提供されていますが、FLUXを個人のコンピュータで実行することには、処理速度の向上、制限のない使用、優れたプライバシーなどの利点があります。このガイドでは、Windows、Mac、およびLinuxシステムでFLUXをローカルに実行する方法について説明します。もっと読む
始める前に、より高品質な代替としての最良のFlowGPT画像生成器についてお話ししましょう。
次の画像は、Anakin AIのAI画像生成器で生成されています。今すぐ試してみてください!👇👇👇


プロンプト:無邪気で魅力的、長髪、オルタナティブな雰囲気、美しい目、そばかす、中くらいの胸、控えめな胸の谷間、引き締まった体、セクシー、カジュアルな写真、(居心地の良い寝室)、オフショルダーシャツ、ダイナミックな角度、鮮やかな照明、高コントラスト、ドラマティックな影、非常に詳細な、詳細な肌、被写界深度、フィルムグレイン
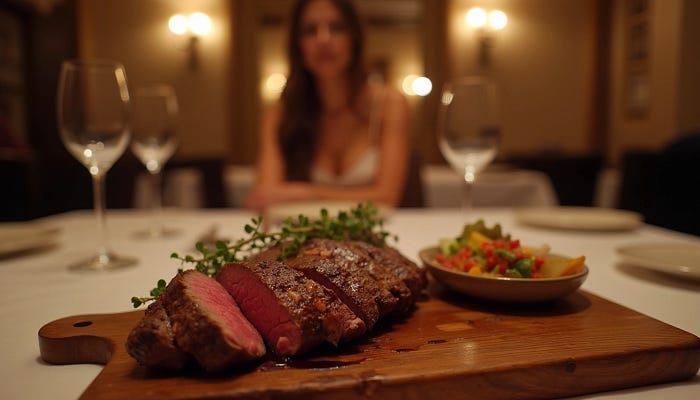
プロンプト:レストランのテーブルに座ったモデルのPOV写真、カメラに向かってロマンティックで高級な設定。ミディアムレアのステーキがテーブルにあり、いくつかの切り分けられ、木の板の上に、小皿には切った野菜が入ったサイドの調味料やサルサが置いてあります。

プロンプト:「Breaking Bread」のTVショーポスター、「Breaking Bad」のパロディ。厳格なパン職人が小麦粉をまぶしたエプロンを着て、武器のように麺棒を持って、素朴なパン屋で立っています。パンのローフや小麦粉の袋が砂漠の背景を模倣しています。黒板のメニューには、ダジャレが入った項目がリストされています。「Breaking」のタイトルには粗いフォントが、そして「Bread」には金色でパンのような文字が使われています。キャッチフレーズ:「ベーキングは危険なゲームです。」

プロンプト:可愛い日本のアニメスタイル、白い天使の翼を持つ大人の女性、黒い悪魔の角と黒いヘッドバンド、赤い後光、長いピンクの波状の髪、茶色の目、悪党のような笑み。黒と白のテクニカルウェアのフーディ、ジーンズ、たくさんのストラップとバックルを着ています。彼女はスプレー缶を持ち、彼女の隣には「Anakin AI画像生成器」という大きな黒と黄色のスプレーペイントの落書きがある壁に立っています。
これらの素晴らしく高品質な画像は、Anakin AIのAI画像生成器で生成されています。今すぐ試してみてください!👇👇👇
Anakin.ai - ワンストップAIアプリプラットフォーム
コンテンツ、画像、ビデオ、音声を生成し、オートメーションワークフロー、カスタムAIアプリ、インテリジェントエージェントを作成します。あなたの…
app.anakin.ai
方法1: ComfyUIを使用してFLUXをローカルに実行する
ComfyUIは、FLUXを含むAIモデルを実行するための強力でユーザーフレンドリーなインターフェースです。この方法は、グラフィカルインターフェースを好み、コマンドライン操作を扱いたくないユーザーに推奨されます。
ステップ1: ComfyUIをインストールする
- ComfyUIのGitHubリリースページにアクセスします: https://github.com/comfyanonymous/ComfyUI/releases
- オペレーティングシステムに適した最新バージョンをダウンロードします。
- ダウンロードしたアーカイブを任意の場所に解凍します。
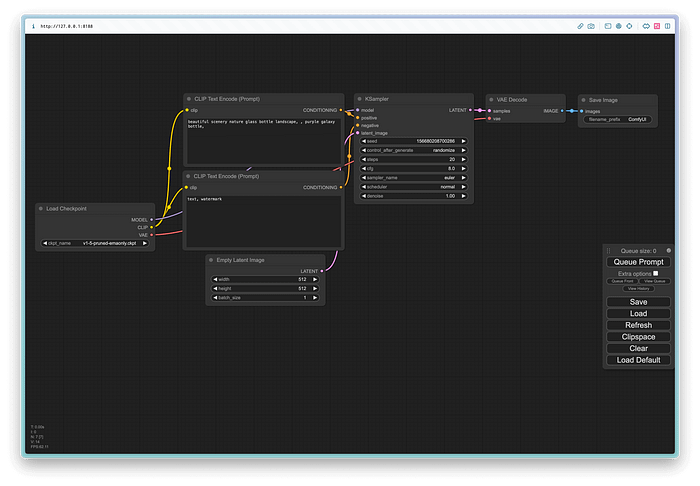
ステップ2: FLUXモデルをダウンロードする
- FLUX HuggingFaceリポジトリにアクセスします: https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main
- 次のファイルをダウンロードします:
- flux_schnell.safetensors(メインモデル)
- ae.safetensors(VAEファイル)
3. FLUXテキストエンコーダーのリポジトリ(https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main)から、次のファイルをダウンロードします:
- t5xxl_fp16.safetensors(32GB以上のRAMを持つシステム用)
- t5xxl_fp8_e4m3fn.safetensors(32GB未満のRAMを持つシステム用)
- clip_l.safetensors
ステップ3: ComfyUIフォルダーにファイルを配置する
- flux_schnell.safetensorsをComfyUI/models/checkpoints/に移動します。
- ae.safetensorsをComfyUI/models/vae/に移動します。
- t5xxl_fp16.safetensors(またはt5xxl_fp8_e4m3fn.safetensors)とclip_l.safetensorsをComfyUI/models/clip/に移動します。
ステップ4: ComfyUIを実行する
- ターミナルまたはコマンドプロンプトを開きます。
- ComfyUIフォルダーに移動します。
- システムに適したコマンドを実行します:
- Windows: python_embeded\\\\python.exe -m ComfyUI
- Mac/Linux: python3 main.py
4. ウェブブラウザを開いてhttp://localhost:8188にアクセスします。
ステップ5: FLUXワークフローを設定する
- ComfyUIインターフェースで右クリックして、次のノードを追加します:
- CLIP Text Encode (T5XXL)
- CLIP Text Encode (CLIP L)
- Flux Guidance
- Empty Latent Image
- VAE Decode
2. ノードを次のように接続します:
- CLIP Text Encode (T5XXL)の出力をFlux Guidanceの「t5_emb」入力に接続します。
- CLIP Text Encode (CLIP L)の出力をFlux Guidanceの「clip_emb」入力に接続します。
- Empty Latent Imageの出力をFlux Guidanceの「latent」入力に接続します。
- Flux Guidanceの出力をVAE Decodeの入力に接続します。
3. 各ノードで希望するパラメーターを設定します。
ステップ6: 画像を生成する
- 両方のCLIP Text Encodeノードにテキストプロンプトを入力します。
- 「Queue Prompt」をクリックして画像を生成します。
方法2: Stable Diffusion WebUIを使用する
Stable Diffusion WebUIは、FLUXを含むAIモデルを実行するためのもう一つの人気のあるインターフェースです。この方法は、すでにStable Diffusionに慣れていて、そのインターフェースを好むユーザーに適しています。
ステップ1: Stable Diffusion WebUIをインストールする
- Stable Diffusion WebUIリポジトリをクローンします:
git clone <https://github.com/AUTOMATIC1111/stable-diffusion-webui.git>
2. クローンしたディレクトリに移動します:
cd stable-diffusion-webui
3. システムに適したスクリプトを実行します:
- Windows: webui-user.bat
- Mac/Linux: ./webui.sh
ステップ2: FLUXモデルをダウンロードする
方法1と同様の手順でFLUXモデルとVAEファイルをダウンロードします。
ステップ3: Stable Diffusion WebUIフォルダーにファイルを配置する
- flux_schnell.safetensorsをstable-diffusion-webui/models/Stable-diffusion/に移動します。
- ae.safetensorsをstable-diffusion-webui/models/VAE/に移動します。
ステップ4: Stable Diffusion WebUIを設定する
- WebUIで「設定」タブに移動します。
- 「Stable Diffusion」の下で、FLUXモデルを選択します。
- 「VAE」の下で、FLUX VAEファイルを選択します。
- 「設定を適用」をクリックして、WebUIを再起動します。
ステップ5: 画像を生成する
- テキスト・トゥ・イメージタブでプロンプトを入力します。
- 希望の設定を調整します。
- 「生成」をクリックして画像を作成します。
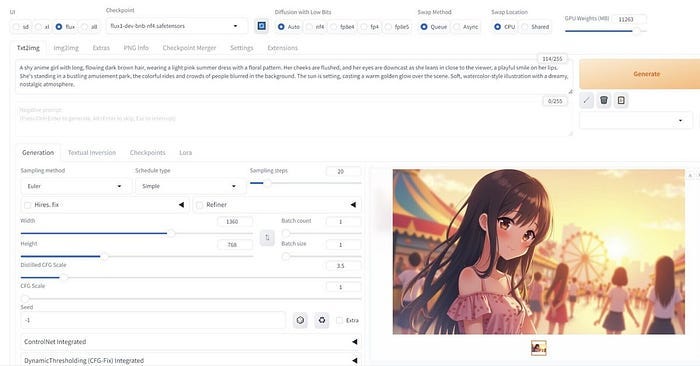
方法3: Stability Matrixを使用する
Stability Matrixは、FLUXを含むさまざまなAIモデルを実行することができる強力でユーザーフレンドリーなアプリケーションです。この方法は、使いやすさとカスタマイズオプションのバランスを求めるユーザーに最適です。
ステップ1: Stability Matrixをインストールする
- Stability MatrixのGitHubページにアクセスします: https://github.com/LykosAI/StabilityMatrix
- オペレーティングシステム(Windows、Mac、またはLinux)用の最新リリースをダウンロードします。
- OSに応じてアプリケーションをインストールします:
- Windows: インストーラ実行ファイルを実行します。
- Mac: .appファイルをアプリケーションフォルダにドラッグします。
- Linux: AppImageを展開し、実行可能にします。
ステップ2: Stability Matrixを設定する
- Stability Matrixを起動します。
- 最初の実行時に、アプリケーションが初期設定をガイドします。
- 希望のインストール場所とGPU設定を選択します。
ステップ3: ComfyUIパッケージをインストールする
- Stability Matrixで「パッケージマネージャ」タブに移動します。
- 利用可能なパッケージのリストから「ComfyUI」を見つけます。
- ComfyUIの隣にある「インストール」をクリックします。
- インストールが完了するまで待ちます。
ステップ4: FLUXモデルをダウンロードする
- Stability Matrixで「モデルマネージャ」タブに移動します。
- 「新しいモデルを追加」をクリックします。
- 検索バーに「FLUX」と入力し、Enterを押します。
- 次のモデルを見つけて、各モデルの「ダウンロード」をクリックします:
- FLUX.1-schnell(メインモデル)
- FLUX VAE(VAEファイル)
- FLUX T5XXLテキストエンコーダ(システムのRAMに基づいてfp16またはfp8を選択します)
- FLUX CLIP Lテキストエンコーダ
ステップ5: FLUX用にComfyUIを設定する
- Stability Matrixで「インストール済みパッケージ」タブに移動します。
- ComfyUIを見つけて「起動」をクリックします。
- ComfyUIがブラウザに開いたら、ワークスペースで右クリックして、次のノードを追加します:
- CLIP Text Encode (T5XXL)
- CLIP Text Encode (CLIP L)
- Flux Guidance
- Empty Latent Image
- VAE Decode
ステップ6: FLUXワークフローを設定する
- ノードを次のように接続します:
- CLIP Text Encode (T5XXL)の出力をFlux Guidanceの「t5_emb」入力に接続します。
- CLIP Text Encode (CLIP L)の出力をFlux Guidanceの「clip_emb」入力に接続します。
- Empty Latent Imageの出力をFlux Guidanceの「latent」入力に接続します。
- Flux Guidanceの出力をVAE Decodeの入力に接続します。
2. 各ノードで適切なFLUXモデルを選択します:
- CLIP Text Encode (T5XXL)には、FLUX T5XXLテキストエンコーダを選択します。
- CLIP Text Encode (CLIP L)には、FLUX CLIP Lテキストエンコーダを選択します。
- Flux Guidanceには、FLUX.1-schnellを選択します。
- VAE Decodeには、FLUX VAEを選択します。
ステップ7: 画像を生成する
- 両方のCLIP Text Encodeノードに希望のテキストプロンプトを入力します。
- Flux Guidanceノードでパラメーターを調整します:
- ステップ数を設定します(例: 20–50)
- ガイダンススケールを調整します(例: 7–9)
- 希望の幅と高さを設定します(例: 512x512)
3. 「Queue Prompt」をクリックして画像を生成します。
方法4: Pythonスクリプトを使用する(上級者向け)
この方法は、Pythonに慣れている上級ユーザー向けで、よりカスタマイズ可能なアプローチを好む方向けです。
ステップ1: Python環境を設定する
- Python 3.8以上をインストールします。
2. 新しい仮想環境を作成します:
python -m venv flux_env
3. 仮想環境をアクティブにします:
- Windows: flux_env\\\\Scripts\\\\activate
- Mac/Linux: source flux_env/bin/activate
ステップ2: 依存関係をインストールする
- CUDAサポート付きのPyTorchをインストールします(あなたのシステムに適したコマンドについてはpytorch.orgを訪問してください)。
2. その他の必須パッケージをインストールします:
pip install transformers diffusers accelerate
ステップ3: FLUXモデルをダウンロードする
方法1と同様の手順でFLUXモデルとVAEファイルをダウンロードします。
ステップ4: Pythonスクリプトを作成する
以下の内容でrun_flux.pyという新しいファイルを作成します:
import torch
from diffusers import FluxModel, FluxScheduler, FluxPipeline
from transformers import T5EncoderModel, CLIPTextModel, CLIPTokenizer
def load_flux():
flux_model = FluxModel.from_pretrained(“path/to/flux_schnell.safetensors”)
t5_model = T5EncoderModel.from_pretrained(“path/to/t5xxl_fp16.safetensors”)
clip_model = CLIPTextModel.from_pretrained(“path/to/clip_l.safetensors”)
clip_tokenizer = CLIPTokenizer.from_pretrained(“openai/clip-vit-large-patch14”)
scheduler = FluxScheduler()
pipeline = FluxPipeline(
flux_model=flux_model,
t5_model=t5_model,
clip_model=clip_model,
clip_tokenizer=clip_tokenizer,
scheduler=scheduler
)
return pipeline
def generate_image(pipeline, prompt, num_inference_steps=50):
image = pipeline(prompt, num_inference_steps=num_inference_steps).images[0]
return image
if __name__ == “__main__”:
pipeline = load_flux()
prompt = “美しい山と湖のある風景”
image = generate_image(pipeline, prompt)
image.save(“flux_generated_image.png”)
ステップ5: スクリプトを実行する
- ターミナルまたはコマンドプロンプトを開きます。
- 仮想環境をアクティブにします。
- スクリプトを実行します:
python run_flux.py
結論
FLUXをローカルに使用することで、AI生成アートとデザインの無限の可能性の領域に入ることができます。使いやすいComfyUI、馴染みのあるStable Diffusion WebUI、またはカスタムPythonスクリプトを通じて、あなたのローカルマシンでFLUXの力をコントロールできるようになります。モデルのライセンス条項を常に遵守し、責任を持って使用してください。
FLUXを深く探求し、さまざまなプロンプト、設定、ワークフローを試して、その全体的な可能性を評価してください。FLUXをローカルに実行することで、生成中により多くの制御が得られるだけでなく、より迅速なイテレーションとモデルの能力の深い理解が可能になります。
献身と想像力を持って、あなたはAI支援アートの限界を超えた特別で高品質なビジュアルを作り出す道を歩んでいます。FLUXとAI画像生成の魅力的な世界への旅を楽しんでください!あなた自身の創造物のエロン・マスクになりましょう!
