急速に進化するAIの風景の中で、DeepSeekは大規模AIモデルのトレーニングと推論における最も重要なボトルネックのひとつに革命的な解決策を導入しました。DeepEP、初のオープンソース専門家並列通信ライブラリは、Mixture-of-Experts(MoE)モデルの展開とスケールの方法を革新すると約束します。
画像、動画、またはテキストベースの生成Flux 1.1 Pro Ultra、Stable Diffusion XL、およびMinimax Video 01
次世代推論のために、GPT-4o、Claude 3、GeminiのようなAIモデルをシームレスに統合します。
自動AIパイプラインとインテリジェントエージェントの展開で計算リソースを最適化します。
高度な画像、動画、テキスト生成モデルを活用してAIの革新を加速させます。
今日からあなたのAIワークフローを超強化しましょう!
Anakin AIを探索する

MoEモデルが重要な理由
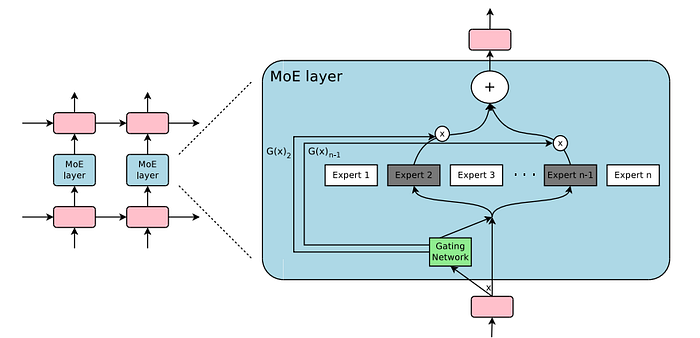
MoEモデルは、AI研究の中で急速に注目を集めています。単一のネットワークに負荷をかけるのではなく、これらのアーキテクチャは特定のタスクに必要な「専門家」ニューラルネットワークのみを活性化し、非常に効率的です。各専門家が自分の作業の一部を担当するチームを持つことを想像してみてください。一人の器用貧乏ではなく。それがMoEの魔法です — 計算コストを膨らませることなく、何兆ものパラメータにスケールアップさせることが可能です。
通信の課題
しかし、どんなバラにも棘があります。MoEモデルが成長するにつれて、トークンを適切な専門家に効率的にルーティングする必要性も高まります。同じGPU上にいる場合でも、異なるノードに広がっている場合でもです。従来の通信ライブラリは、このような全対全データ交換のためには作られていませんでした。その結果、トレーニングの遅延、推論の遅延、およびハードウェアの未活用が発生します。時間とコストとの競争において、毎マイクロ秒が重要です。
DeepSeek DeepEPの解説:それが何であり、何をするのか、どう機能するのか

あなたは「DeepSeek DeepEPとは一体何ですか?」と思っているかもしれません。さあ、わかりやすく説明しましょう。DeepEPはDeepSeekによって作られたオープンソースの通信ライブラリです。これは、タスクを多くの専門家に分担させるMoEモデルの重い負担を軽減するために特別に設計されています。基本的に、DeepEPはすべてのデータが迅速かつスムーズに正しい専門家に届くことを保証します。
DeepEPは何をするのか?
簡単に言えば、DeepEPは専門家間のデータシャッフルを合理化します。適切な専門家に入力トークンを送信し、結果を効率的に収集することを担当します。そうすることで、通常、大規模AIシステムのトレーニングや推論を遅らせるラグやボトルネックを削減します。
それはどのように機能するのか?
DeepEPは、高速通信技術を活用しています:
- マシン内:NVIDIAのNVLinkを使用して、データを驚異的な153 GB/sで移動します。これは、賑やかなキッチンの中で高速度コンベアベルトのように、すべての材料が遅れることなく目的地に届くと考えてください。
- マシン間:異なるマシン間の通信のために、DeepEPはRDMA over InfiniBandに依存しており、最大47 GB/sの速度に達します。できたばかりの注文が記録的な時間で送信され、受信される確実な配達サービスを想像してみてください。
- 精度管理:ネイティブFP8サポートにより、DeepEPはメモリ使用量を大幅に削減しつつ、モデルの精度を維持します — まるで、基本的なものを外さずにスーツケースをより効率よくパッキングするようなものです。
実際の例:
ディナーラッシュの間にレストランを運営していると想像してみてください。注文(入力トークン)が入り、特別料理のために適切なシェフ(専門家)に送信する必要があります。従来のシステムでは注文が混同されたり、配達が遅れたりしてサービスが遅くなり、顧客が不満を抱く可能性があります。DeepEPを使用すると、各注文が迅速に正しいシェフに配送され、完成した料理がウェイター(結合された結果)にすぐに戻され、すべてのゲストが時間通りに食事を受け取れるようになります。この合理化されたプロセスが、まさにDeepEPがMoEモデルのために行うことです — すべてのデータが迅速かつ正確に処理されることを保証します。
実際の影響
DeepEPの利点は理論的なものだけではなく、実際のアプリケーションで波を起こしています。初期のユーザーからは次のような報告が寄せられています:
- トレーニング中のトークン処理が55%早くなる、これはより多くのデータが短時間で処理されることを意味します。
- イテレーション時間が30%短縮される、モデルの実行中に貴重な数秒(または数分)を削減します。
- 電力効率の改善 — グリーンであり、パフォーマンスを向上させながらエネルギーコストを削減します。
これらの改善は、単なる数字ではなく、クラウドコストの実際の節約、より早い実験サイクル、大きなスケーラビリティの向上につながっています。膨大な言語モデルのトレーニングを行っている場合でも、リアルタイムのビデオ分析を行っている場合でも、DeepEPはその価値を証明しています。
未来を見据えて
DeepEPは自慢している暇はありません。今後のロードマップはかなりワクワクします:
- 光インターコネクトは、さらに高いスループットを約束します — 800 Gb/sを考えてみてください。
- 自動精度適応が近づいており、FP8、FP16、FP32間を動的に切り替えて、速度と安定性の最良のバランスを取ります。
- いくつかの情報筋は、量子にインスパイアされたルーティングをほのめかしており、これはサイエンスフィクションのように思えますが、トークン配送効率の次の大きな飛躍になる可能性があります。
結論
では、DeepEPについての最終的な言葉は何でしょうか?それは、MoEモデルに取り組むすべての人にとって新鮮な風です。AIのトレーニングと推論における最も難しいボトルネックのひとつに取り組むことにより、DeepEPは速度と効率を向上させるだけでなく、そのオープンソースの特性を通じて高性能通信ツールへのアクセスを民主化しています。業界全体の専門家たちは、技術的な厳密さと実際の利点を両立させることができるその能力を絶賛しています。
要するに、DeepEPはAIにおける従来の通信の課題を打破しています。これは、可能性の限界を押し上げるだけでなく、プロセス全体をスムーズ、早く、エネルギー効率の良いものにしています。AIコミュニティの人々にとって、これは注目すべき革新です。
言うまでもなく、困難な状況に直面したとき、タフな人々が行動に出る — そしてDeepEPと共に、分散AIの未来はかつてないほど明るく見えます。



